 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainFuzz: Explainable and Constraint-Conditioned Test Generation with Probabilistic Circuits
Apr 08, 2026Understanding and explaining the structure of generated test inputs is essential for effective software testing and debugging. Existing approaches--including grammar-based fuzzers, probabilistic Context-Free Grammars (pCFGs), and Large Language Models (LLMs)--suffer from critical limitations. They frequently produce ill-formed inputs that fail to reflect realistic data distributions, struggle to capture context-sensitive probabilistic dependencies, and lack explainability. We introduce ExplainFuzz, a test generation framework that leverages Probabilistic Circuits (PCs) to learn and query structured distributions over grammar-based test inputs interpretably and controllably. Starting from a Context-Free Grammar (CFG), ExplainFuzz compiles a grammar-aware PC and trains it on existing inputs. New inputs are then generated via sampling. ExplainFuzz utilizes the conditioning capability of PCs to incorporate test-specific constraints (e.g., a query must have GROUP BY), enabling constrained probabilistic sampling to generate inputs satisfying grammar and user-provided constraints. Our results show that ExplainFuzz improves the coherence and realism of generated inputs, achieving significant perplexity reduction compared to pCFGs, grammar-unaware PCs, and LLMs. By leveraging its native conditioning capability, ExplainFuzz significantly enhances the diversity of inputs that satisfy a user-provided constraint. Compared to grammar-aware mutational fuzzing, ExplainFuzz increases bug-triggering rates from 35% to 63% in SQL and from 10% to 100% in XML. These results demonstrate the power of a learned input distribution over mutational fuzzing, which is often limited to exploring the local neighborhood of seed inputs. These capabilities highlight the potential of PCs to serve as a foundation for grammar-aware, controllable test generation that captures context-sensitive, probabilistic dependencies.
Mi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety
Jun 05, 2025As large language models (LLMs) see wider real-world use, understanding and mitigating their unsafe behaviors is critical. Interpretation techniques can reveal causes of unsafe outputs and guide safety, but such connections with safety are often overlooked in prior surveys. We present the first survey that bridges this gap, introducing a unified framework that connects safety-focused interpretation methods, the safety enhancements they inform, and the tools that operationalize them. Our novel taxonomy, organized by LLM workflow stages, summarizes nearly 70 works at their intersections. We conclude with open challenges and future directions. This timely survey helps researchers and practitioners navigate key advancements for safer, more interpretable LLMs.
Shape it Up! Restoring LLM Safety during Finetuning
May 22, 2025Finetuning large language models (LLMs) enables user-specific customization but introduces critical safety risks: even a few harmful examples can compromise safety alignment. A common mitigation strategy is to update the model more strongly on examples deemed safe, while downweighting or excluding those flagged as unsafe. However, because safety context can shift within a single example, updating the model equally on both harmful and harmless parts of a response is suboptimal-a coarse treatment we term static safety shaping. In contrast, we propose dynamic safety shaping (DSS), a framework that uses fine-grained safety signals to reinforce learning from safe segments of a response while suppressing unsafe content. To enable such fine-grained control during finetuning, we introduce a key insight: guardrail models, traditionally used for filtering, can be repurposed to evaluate partial responses, tracking how safety risk evolves throughout the response, segment by segment. This leads to the Safety Trajectory Assessment of Response (STAR), a token-level signal that enables shaping to operate dynamically over the training sequence. Building on this, we present STAR-DSS, guided by STAR scores, that robustly mitigates finetuning risks and delivers substantial safety improvements across diverse threats, datasets, and model families-all without compromising capability on intended tasks. We encourage future safety research to build on dynamic shaping principles for stronger mitigation against evolving finetuning risks.
Can LLM Generate Regression Tests for Software Commits?
Jan 19, 2025



Large Language Models (LLMs) have shown tremendous promise in automated software engineering. In this paper, we investigate the opportunities of LLMs for automatic regression test generation for programs that take highly structured, human-readable inputs, such as XML parsers or JavaScript interpreters. Concretely, we explore the following regression test generation scenarios for such programs that have so far been difficult to test automatically in the absence of corresponding input grammars: $\bullet$ Bug finding. Given a code change (e.g., a commit or pull request), our LLM-based approach generates a test case with the objective of revealing any bugs that might be introduced if that change is applied. $\bullet$ Patch testing. Given a patch, our LLM-based approach generates a test case that fails before but passes after the patch. This test can be added to the regression test suite to catch similar bugs in the future. We implement Cleverest, a feedback-directed, zero-shot LLM-based regression test generation technique, and evaluate its effectiveness on 22 commits to three subject programs: Mujs, Libxml2, and Poppler. For programs using more human-readable file formats, like XML or JavaScript, we found Cleverest performed very well. It generated easy-to-understand bug-revealing or bug-reproduction test cases for the majority of commits in just under three minutes -- even when only the code diff or commit message (unless it was too vague) was given. For programs with more compact file formats, like PDF, as expected, it struggled to generate effective test cases. However, the LLM-supplied test cases are not very far from becoming effective (e.g., when used as a seed by a greybox fuzzer or as a starting point by the developer).
LLM Hallucination Reasoning with Zero-shot Knowledge Test
Nov 14, 2024LLM hallucination, where LLMs occasionally generate unfaithful text, poses significant challenges for their practical applications. Most existing detection methods rely on external knowledge, LLM fine-tuning, or hallucination-labeled datasets, and they do not distinguish between different types of hallucinations, which are crucial for improving detection performance. We introduce a new task, Hallucination Reasoning, which classifies LLM-generated text into one of three categories: aligned, misaligned, and fabricated. Our novel zero-shot method assesses whether LLM has enough knowledge about a given prompt and text. Our experiments conducted on new datasets demonstrate the effectiveness of our method in hallucination reasoning and underscore its importance for enhancing detection performance.
Effective Guidance for Model Attention with Simple Yes-no Annotations
Oct 29, 2024



Modern deep learning models often make predictions by focusing on irrelevant areas, leading to biased performance and limited generalization. Existing methods aimed at rectifying model attention require explicit labels for irrelevant areas or complex pixel-wise ground truth attention maps. We present CRAYON (Correcting Reasoning with Annotations of Yes Or No), offering effective, scalable, and practical solutions to rectify model attention using simple yes-no annotations. CRAYON empowers classical and modern model interpretation techniques to identify and guide model reasoning: CRAYON-ATTENTION directs classic interpretations based on saliency maps to focus on relevant image regions, while CRAYON-PRUNING removes irrelevant neurons identified by modern concept-based methods to mitigate their influence. Through extensive experiments with both quantitative and human evaluation, we showcase CRAYON's effectiveness, scalability, and practicality in refining model attention. CRAYON achieves state-of-the-art performance, outperforming 12 methods across 3 benchmark datasets, surpassing approaches that require more complex annotations.
Zero-Shot Multi-Hop Question Answering via Monte-Carlo Tree Search with Large Language Models
Sep 28, 2024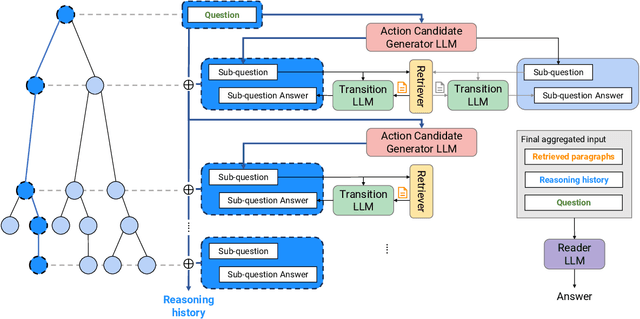
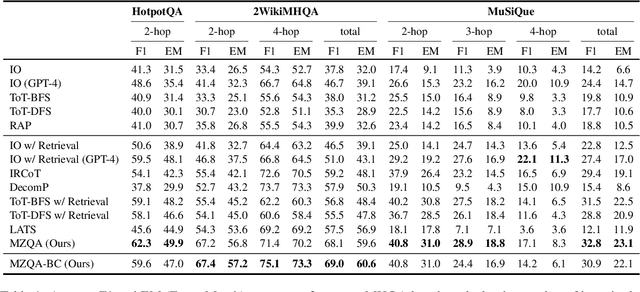
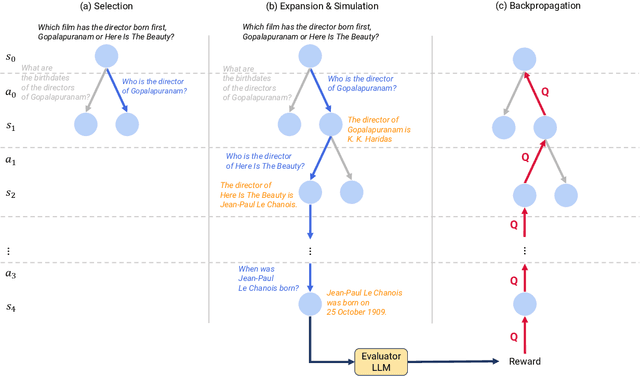
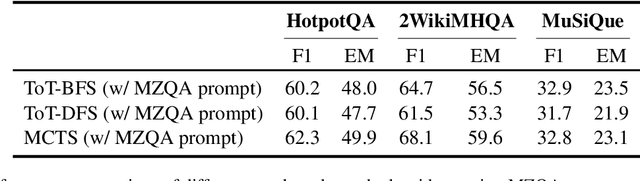
Recent advances in large language models (LLMs) have significantly impacted the domain of multi-hop question answering (MHQA), where systems are required to aggregate information and infer answers from disparate pieces of text. However, the autoregressive nature of LLMs inherently poses a challenge as errors may accumulate if mistakes are made in the intermediate reasoning steps. This paper introduces Monte-Carlo tree search for Zero-shot multi-hop Question Answering (MZQA), a framework based on Monte-Carlo tree search (MCTS) to identify optimal reasoning paths in MHQA tasks, mitigating the error propagation from sequential reasoning processes. Unlike previous works, we propose a zero-shot prompting method, which relies solely on instructions without the support of hand-crafted few-shot examples that typically require domain expertise. We also introduce a behavioral cloning approach (MZQA-BC) trained on self-generated MCTS inference trajectories, achieving an over 10-fold increase in reasoning speed with bare compromise in performance. The efficacy of our method is validated on standard benchmarks such as HotpotQA, 2WikiMultihopQA, and MuSiQue, demonstrating that it outperforms existing frameworks.
Transformer Explainer: Interactive Learning of Text-Generative Models
Aug 08, 2024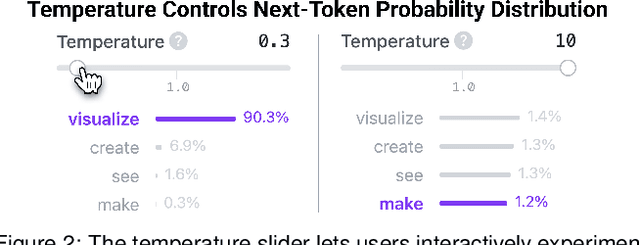
Transformers have revolutionized machine learning, yet their inner workings remain opaque to many. We present Transformer Explainer, an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model. Our tool helps users understand complex Transformer concepts by integrating a model overview and enabling smooth transitions across abstraction levels of mathematical operations and model structures. It runs a live GPT-2 instance locally in the user's browser, empowering users to experiment with their own input and observe in real-time how the internal components and parameters of the Transformer work together to predict the next tokens. Our tool requires no installation or special hardware, broadening the public's education access to modern generative AI techniques. Our open-sourced tool is available at https://poloclub.github.io/transformer-explainer/. A video demo is available at https://youtu.be/ECR4oAwocjs.
CanonicalFusion: Generating Drivable 3D Human Avatars from Multiple Images
Jul 05, 2024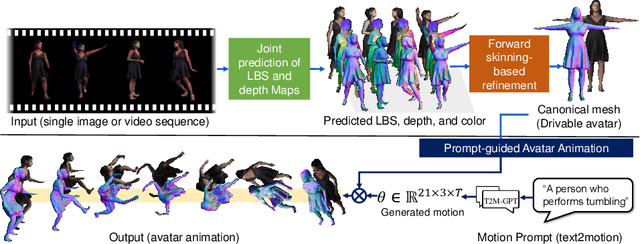
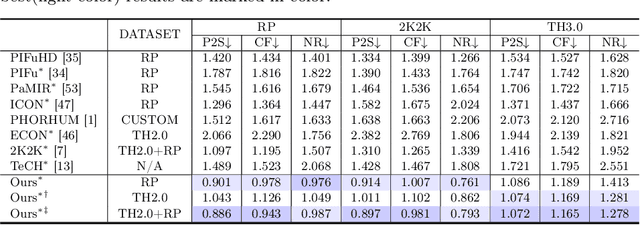
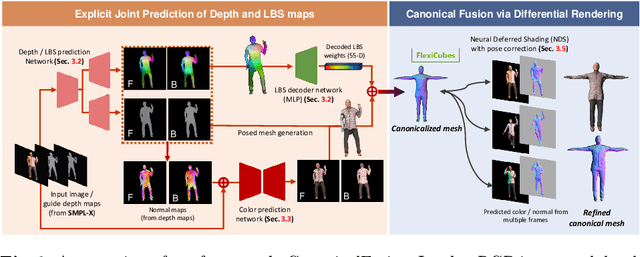
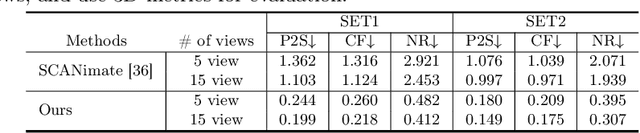
We present a novel framework for reconstructing animatable human avatars from multiple images, termed CanonicalFusion. Our central concept involves integrating individual reconstruction results into the canonical space. To be specific, we first predict Linear Blend Skinning (LBS) weight maps and depth maps using a shared-encoder-dual-decoder network, enabling direct canonicalization of the 3D mesh from the predicted depth maps. Here, instead of predicting high-dimensional skinning weights, we infer compressed skinning weights, i.e., 3-dimensional vector, with the aid of pre-trained MLP networks. We also introduce a forward skinning-based differentiable rendering scheme to merge the reconstructed results from multiple images. This scheme refines the initial mesh by reposing the canonical mesh via the forward skinning and by minimizing photometric and geometric errors between the rendered and the predicted results. Our optimization scheme considers the position and color of vertices as well as the joint angles for each image, thereby mitigating the negative effects of pose errors. We conduct extensive experiments to demonstrate the effectiveness of our method and compare our CanonicalFusion with state-of-the-art methods. Our source codes are available at https://github.com/jsshin98/CanonicalFusion.