 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unseen Threat: Residual Knowledge in Machine Unlearning under Perturbed Samples
Jan 29, 2026Machine unlearning offers a practical alternative to avoid full model re-training by approximately removing the influence of specific user data. While existing methods certify unlearning via statistical indistinguishability from re-trained models, these guarantees do not naturally extend to model outputs when inputs are adversarially perturbed. In particular, slight perturbations of forget samples may still be correctly recognized by the unlearned model - even when a re-trained model fails to do so - revealing a novel privacy risk: information about the forget samples may persist in their local neighborhood. In this work, we formalize this vulnerability as residual knowledge and show that it is inevitable in high-dimensional settings. To mitigate this risk, we propose a fine-tuning strategy, named RURK, that penalizes the model's ability to re-recognize perturbed forget samples. Experiments on vision benchmarks with deep neural networks demonstrate that residual knowledge is prevalent across existing unlearning methods and that our approach effectively prevents residual knowledge.
Does Privacy Always Harm Fairness? Data-Dependent Trade-offs via Chernoff Information Neural Estimation
Jan 20, 2026Fairness and privacy are two vital pillars of trustworthy machine learning. Despite extensive research on these individual topics, the relationship between fairness and privacy has received significantly less attention. In this paper, we utilize the information-theoretic measure Chernoff Information to highlight the data-dependent nature of the relationship among the triad of fairness, privacy, and accuracy. We first define Noisy Chernoff Difference, a tool that allows us to analyze the relationship among the triad simultaneously. We then show that for synthetic data, this value behaves in 3 distinct ways (depending on the distribution of the data). We highlight the data distributions involved in these cases and explore their fairness and privacy implications. Additionally, we show that Noisy Chernoff Difference acts as a proxy for the steepness of the fairness-accuracy curves. Finally, we propose a method for estimating Chernoff Information on data from unknown distributions and utilize this framework to examine the triad dynamic on real datasets. This work builds towards a unified understanding of the fairness-privacy-accuracy relationship and highlights its data-dependent nature.
PASS: Private Attributes Protection with Stochastic Data Substitution
Jun 08, 2025The growing Machine Learning (ML) services require extensive collections of user data, which may inadvertently include people's private information irrelevant to the services. Various studies have been proposed to protect private attributes by removing them from the data while maintaining the utilities of the data for downstream tasks. Nevertheless, as we theoretically and empirically show in the paper, these methods reveal severe vulnerability because of a common weakness rooted in their adversarial training based strategies. To overcome this limitation, we propose a novel approach, PASS, designed to stochastically substitute the original sample with another one according to certain probabilities, which is trained with a novel loss function soundly derived from information-theoretic objective defined for utility-preserving private attributes protection. The comprehensive evaluation of PASS on various datasets of different modalities, including facial images, human activity sensory signals, and voice recording datasets, substantiates PASS's effectiveness and generalizability.
HeavyWater and SimplexWater: Watermarking Low-Entropy Text Distributions
Jun 06, 2025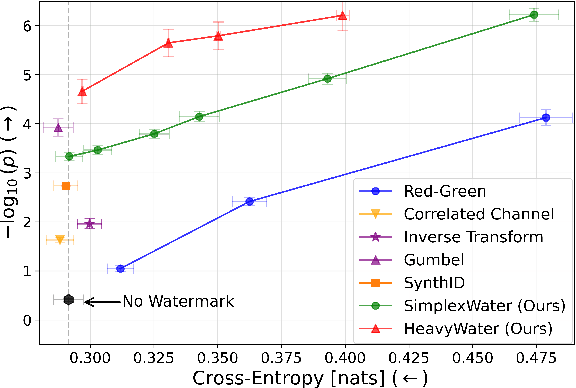
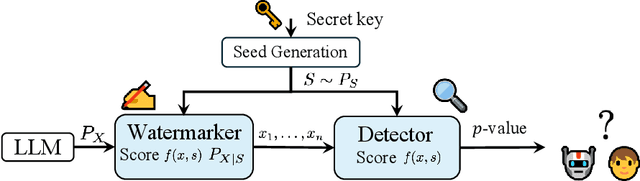
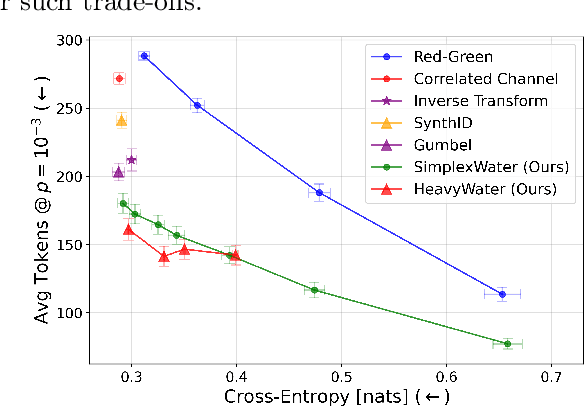
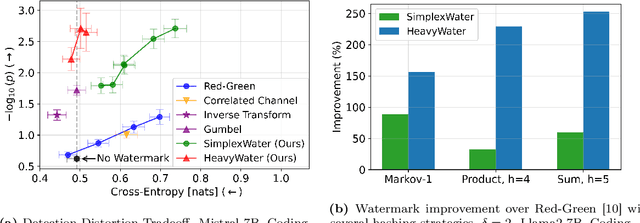
Large language model (LLM) watermarks enable authentication of text provenance, curb misuse of machine-generated text, and promote trust in AI systems. Current watermarks operate by changing the next-token predictions output by an LLM. The updated (i.e., watermarked) predictions depend on random side information produced, for example, by hashing previously generated tokens. LLM watermarking is particularly challenging in low-entropy generation tasks - such as coding - where next-token predictions are near-deterministic. In this paper, we propose an optimization framework for watermark design. Our goal is to understand how to most effectively use random side information in order to maximize the likelihood of watermark detection and minimize the distortion of generated text. Our analysis informs the design of two new watermarks: HeavyWater and SimplexWater. Both watermarks are tunable, gracefully trading-off between detection accuracy and text distortion. They can also be applied to any LLM and are agnostic to side information generation. We examine the performance of HeavyWater and SimplexWater through several benchmarks, demonstrating that they can achieve high watermark detection accuracy with minimal compromise of text generation quality, particularly in the low-entropy regime. Our theoretical analysis also reveals surprising new connections between LLM watermarking and coding theory. The code implementation can be found in https://github.com/DorTsur/HeavyWater_SimplexWater
Optimized Couplings for Watermarking Large Language Models
May 13, 2025Large-language models (LLMs) are now able to produce text that is, in many cases, seemingly indistinguishable from human-generated content. This has fueled the development of watermarks that imprint a ``signal'' in LLM-generated text with minimal perturbation of an LLM's output. This paper provides an analysis of text watermarking in a one-shot setting. Through the lens of hypothesis testing with side information, we formulate and analyze the fundamental trade-off between watermark detection power and distortion in generated textual quality. We argue that a key component in watermark design is generating a coupling between the side information shared with the watermark detector and a random partition of the LLM vocabulary. Our analysis identifies the optimal coupling and randomization strategy under the worst-case LLM next-token distribution that satisfies a min-entropy constraint. We provide a closed-form expression of the resulting detection rate under the proposed scheme and quantify the cost in a max-min sense. Finally, we provide an array of numerical results, comparing the proposed scheme with the theoretical optimum and existing schemes, in both synthetic data and LLM watermarking. Our code is available at https://github.com/Carol-Long/CC_Watermark
Adaptive 3D UI Placement in Mixed Reality Using Deep Reinforcement Learning
Apr 30, 2025


Mixed Reality (MR) could assist users' tasks by continuously integrating virtual content with their view of the physical environment. However, where and how to place these content to best support the users has been a challenging problem due to the dynamic nature of MR experiences. In contrast to prior work that investigates optimization-based methods, we are exploring how reinforcement learning (RL) could assist with continuous 3D content placement that is aware of users' poses and their surrounding environments. Through an initial exploration and preliminary evaluation, our results demonstrate the potential of RL to position content that maximizes the reward for users on the go. We further identify future directions for research that could harness the power of RL for personalized and optimized UI and content placement in MR.
* In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA '24)
LLM Hallucination Reasoning with Zero-shot Knowledge Test
Nov 14, 2024LLM hallucination, where LLMs occasionally generate unfaithful text, poses significant challenges for their practical applications. Most existing detection methods rely on external knowledge, LLM fine-tuning, or hallucination-labeled datasets, and they do not distinguish between different types of hallucinations, which are crucial for improving detection performance. We introduce a new task, Hallucination Reasoning, which classifies LLM-generated text into one of three categories: aligned, misaligned, and fabricated. Our novel zero-shot method assesses whether LLM has enough knowledge about a given prompt and text. Our experiments conducted on new datasets demonstrate the effectiveness of our method in hallucination reasoning and underscore its importance for enhancing detection performance.
OVOR: OnePrompt with Virtual Outlier Regularization for Rehearsal-Free Class-Incremental Learning
Feb 06, 2024Recent works have shown that by using large pre-trained models along with learnable prompts, rehearsal-free methods for class-incremental learning (CIL) settings can achieve superior performance to prominent rehearsal-based ones. Rehearsal-free CIL methods struggle with distinguishing classes from different tasks, as those are not trained together. In this work we propose a regularization method based on virtual outliers to tighten decision boundaries of the classifier, such that confusion of classes among different tasks is mitigated. Recent prompt-based methods often require a pool of task-specific prompts, in order to prevent overwriting knowledge of previous tasks with that of the new task, leading to extra computation in querying and composing an appropriate prompt from the pool. This additional cost can be eliminated, without sacrificing accuracy, as we reveal in the paper. We illustrate that a simplified prompt-based method can achieve results comparable to previous state-of-the-art (SOTA) methods equipped with a prompt pool, using much less learnable parameters and lower inference cost. Our regularization method has demonstrated its compatibility with different prompt-based methods, boosting those previous SOTA rehearsal-free CIL methods' accuracy on the ImageNet-R and CIFAR-100 benchmarks. Our source code is available at https://github.com/jpmorganchase/ovor.
Machine Unlearning for Image-to-Image Generative Models
Feb 02, 2024
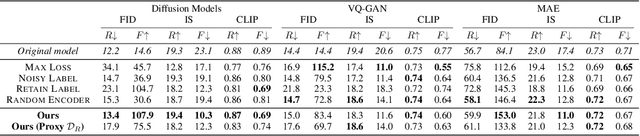
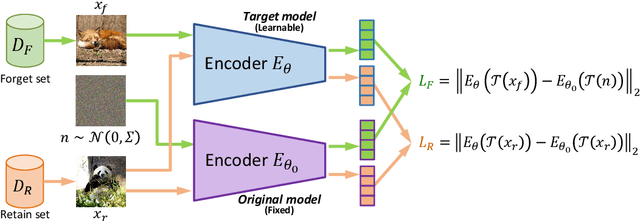
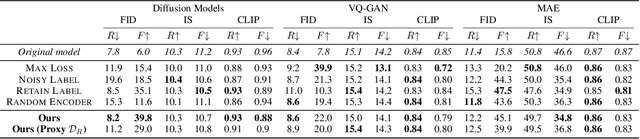
Machine unlearning has emerged as a new paradigm to deliberately forget data samples from a given model in order to adhere to stringent regulations. However, existing machine unlearning methods have been primarily focused on classification models, leaving the landscape of unlearning for generative models relatively unexplored. This paper serves as a bridge, addressing the gap by providing a unifying framework of machine unlearning for image-to-image generative models. Within this framework, we propose a computationally-efficient algorithm, underpinned by rigorous theoretical analysis, that demonstrates negligible performance degradation on the retain samples, while effectively removing the information from the forget samples. Empirical studies on two large-scale datasets, ImageNet-1K and Places-365, further show that our algorithm does not rely on the availability of the retain samples, which further complies with data retention policy. To our best knowledge, this work is the first that represents systemic, theoretical, empirical explorations of machine unlearning specifically tailored for image-to-image generative models. Our code is available at https://github.com/jpmorganchase/l2l-generator-unlearning.
Dropout-Based Rashomon Set Exploration for Efficient Predictive Multiplicity Estimation
Feb 01, 2024



Predictive multiplicity refers to the phenomenon in which classification tasks may admit multiple competing models that achieve almost-equally-optimal performance, yet generate conflicting outputs for individual samples. This presents significant concerns, as it can potentially result in systemic exclusion, inexplicable discrimination, and unfairness in practical applications. Measuring and mitigating predictive multiplicity, however, is computationally challenging due to the need to explore all such almost-equally-optimal models, known as the Rashomon set, in potentially huge hypothesis spaces. To address this challenge, we propose a novel framework that utilizes dropout techniques for exploring models in the Rashomon set. We provide rigorous theoretical derivations to connect the dropout parameters to properties of the Rashomon set, and empirically evaluate our framework through extensive experimentation. Numerical results show that our technique consistently outperforms baselines in terms of the effectiveness of predictive multiplicity metric estimation, with runtime speedup up to $20\times \sim 5000\times$. With efficient Rashomon set exploration and metric estimation, mitigation of predictive multiplicity is then achieved through dropout ensemble and model selection.