 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit and Conquer Partial Deepfake Speech
Apr 03, 2026Partial deepfake speech detection requires identifying manipulated regions that may occur within short temporal portions of an otherwise bona fide utterance, making the task particularly challenging for conventional utterance-level classifiers. We propose a split-and-conquer framework that decomposes the problem into two stages: boundary detection and segment-level classification. A dedicated boundary detector first identifies temporal transition points, allowing the audio signal to be divided into segments that are expected to contain acoustically consistent content. Each resulting segment is then evaluated independently to determine whether it corresponds to bona fide or fake speech. This formulation simplifies the learning objective by explicitly separating temporal localization from authenticity assessment, allowing each component to focus on a well-defined task. To further improve robustness, we introduce a reflection-based multi-length training strategy that converts variable-duration segments into several fixed input lengths, producing diverse feature-space representations. Each stage is trained using multiple configurations with different feature extractors and augmentation strategies, and their complementary predictions are fused to obtain improved final models. Experiments on the PartialSpoof benchmark demonstrate state-of-the-art performance across multiple temporal resolutions as well as at the utterance level, with substantial improvements in the accurate detection and localization of spoofed regions. In addition, the proposed method achieves state-of-the-art performance on the Half-Truth dataset, further confirming the robustness and generalization capability of the framework.
Plan for Speed -- Dilated Scheduling for Masked Diffusion Language Models
Jun 23, 2025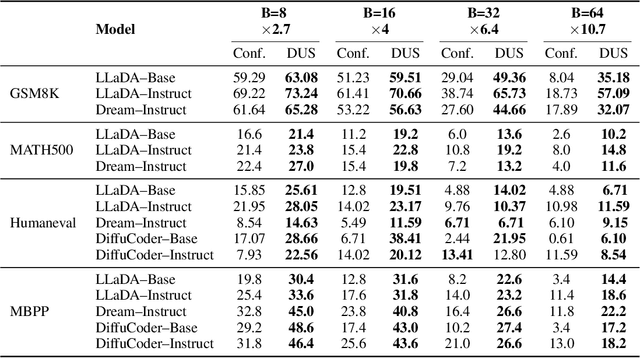



Masked diffusion language models (MDLM) have shown strong promise for non-autoregressive text generation, yet existing samplers act as implicit planners, selecting tokens to unmask via denoiser confidence or entropy scores. Such heuristics falter under parallel unmasking - they ignore pairwise interactions between tokens and cannot account for dependencies when unmasking multiple positions at once, limiting their inference time to traditional auto-regressive (AR) models. We introduce the Dilated-scheduled Unmasking Strategy (DUS), an inference-only, planner-model-free method that requires no additional training. DUS leverages a first-order Markov assumption to partition sequence positions into dilation-based groups of non-adjacent tokens, enabling independent, parallel unmasking steps that respect local context that minimizes the joint entropy of each iteration step. Unlike semi-AR block approaches (e.g., LLADA and Dream) that still invoke the denoiser per block, DUS reduces the number of denoiser calls to O(log B) per generation block - yielding substantial speedup over the O(B) run time of state-of-the-art diffusion models, where B is the block size in the semi-AR inference process. In experiments on math (GSM8K) and code completion (Humaneval, MBPP) benchmarks - domains suited to non-ordinal generation - DUS improves scores over parallel confidence-based planner, without modifying the underlying denoiser. DUS offers a lightweight, budget-aware approach to efficient, high-quality text generation, paving the way to unlock the true capabilities of MDLMs.
HeavyWater and SimplexWater: Watermarking Low-Entropy Text Distributions
Jun 06, 2025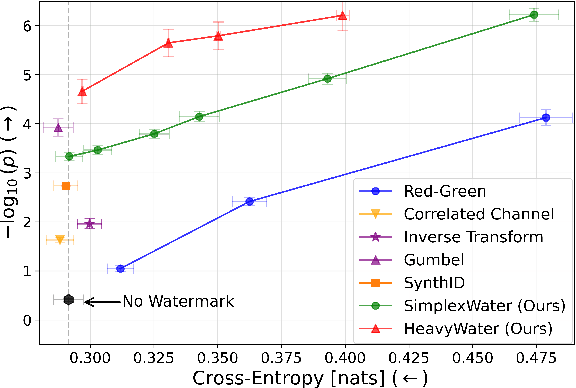
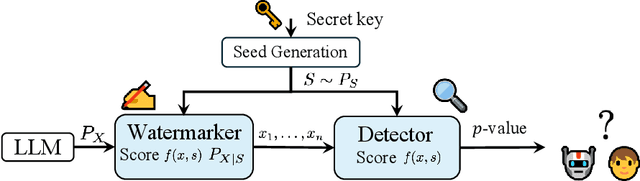
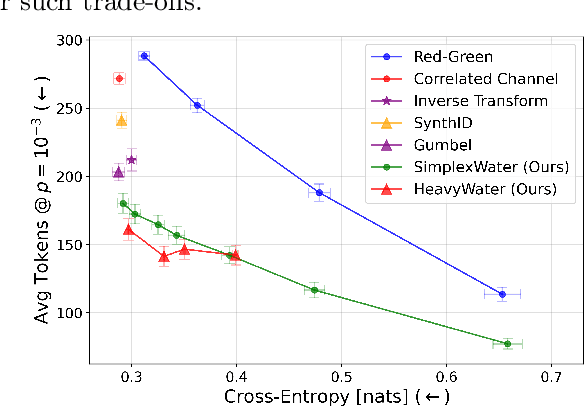
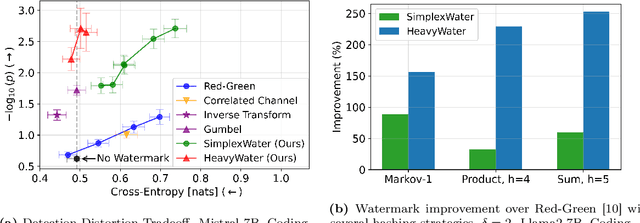
Large language model (LLM) watermarks enable authentication of text provenance, curb misuse of machine-generated text, and promote trust in AI systems. Current watermarks operate by changing the next-token predictions output by an LLM. The updated (i.e., watermarked) predictions depend on random side information produced, for example, by hashing previously generated tokens. LLM watermarking is particularly challenging in low-entropy generation tasks - such as coding - where next-token predictions are near-deterministic. In this paper, we propose an optimization framework for watermark design. Our goal is to understand how to most effectively use random side information in order to maximize the likelihood of watermark detection and minimize the distortion of generated text. Our analysis informs the design of two new watermarks: HeavyWater and SimplexWater. Both watermarks are tunable, gracefully trading-off between detection accuracy and text distortion. They can also be applied to any LLM and are agnostic to side information generation. We examine the performance of HeavyWater and SimplexWater through several benchmarks, demonstrating that they can achieve high watermark detection accuracy with minimal compromise of text generation quality, particularly in the low-entropy regime. Our theoretical analysis also reveals surprising new connections between LLM watermarking and coding theory. The code implementation can be found in https://github.com/DorTsur/HeavyWater_SimplexWater
Optimized Couplings for Watermarking Large Language Models
May 13, 2025Large-language models (LLMs) are now able to produce text that is, in many cases, seemingly indistinguishable from human-generated content. This has fueled the development of watermarks that imprint a ``signal'' in LLM-generated text with minimal perturbation of an LLM's output. This paper provides an analysis of text watermarking in a one-shot setting. Through the lens of hypothesis testing with side information, we formulate and analyze the fundamental trade-off between watermark detection power and distortion in generated textual quality. We argue that a key component in watermark design is generating a coupling between the side information shared with the watermark detector and a random partition of the LLM vocabulary. Our analysis identifies the optimal coupling and randomization strategy under the worst-case LLM next-token distribution that satisfies a min-entropy constraint. We provide a closed-form expression of the resulting detection rate under the proposed scheme and quantify the cost in a max-min sense. Finally, we provide an array of numerical results, comparing the proposed scheme with the theoretical optimum and existing schemes, in both synthetic data and LLM watermarking. Our code is available at https://github.com/Carol-Long/CC_Watermark
Efficient Time Series Forecasting via Hyper-Complex Models and Frequency Aggregation
Feb 27, 2025



Time series forecasting is a long-standing problem in statistics and machine learning. One of the key challenges is processing sequences with long-range dependencies. To that end, a recent line of work applied the short-time Fourier transform (STFT), which partitions the sequence into multiple subsequences and applies a Fourier transform to each separately. We propose the Frequency Information Aggregation (FIA)-Net, which is based on a novel complex-valued MLP architecture that aggregates adjacent window information in the frequency domain. To further increase the receptive field of the FIA-Net, we treat the set of windows as hyper-complex (HC) valued vectors and employ HC algebra to efficiently combine information from all STFT windows altogether. Using the HC-MLP backbone allows for improved handling of sequences with long-term dependence. Furthermore, due to the nature of HC operations, the HC-MLP uses up to three times fewer parameters than the equivalent standard window aggregation method. We evaluate the FIA-Net on various time-series benchmarks and show that the proposed methodologies outperform existing state of the art methods in terms of both accuracy and efficiency. Our code is publicly available on https://anonymous.4open.science/r/research-1803/.
Unmasking Deepfakes: Leveraging Augmentations and Features Variability for Deepfake Speech Detection
Jan 09, 2025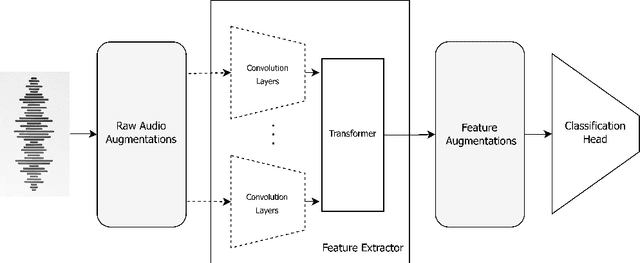


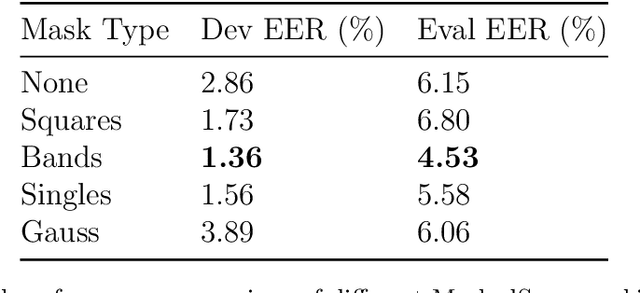
The detection of deepfake speech has become increasingly challenging with the rapid evolution of deepfake technologies. In this paper, we propose a hybrid architecture for deepfake speech detection, combining a self-supervised learning framework for feature extraction with a classifier head to form an end-to-end model. Our approach incorporates both audio-level and feature-level augmentation techniques. Specifically, we introduce and analyze various masking strategies for augmenting raw audio spectrograms and for enhancing feature representations during training. We incorporate compression augmentations during the pretraining phase of the feature extractor to address the limitations of small, single-language datasets. We evaluate the model on the ASVSpoof5 (ASVSpoof 2024) challenge, achieving state-of-the-art results in Track 1 under closed conditions with an Equal Error Rate of 4.37%. By employing different pretrained feature extractors, the model achieves an enhanced EER of 3.39%. Our model demonstrates robust performance against unseen deepfake attacks and exhibits strong generalization across different codecs.
TREET: TRansfer Entropy Estimation via Transformer
Feb 21, 2024
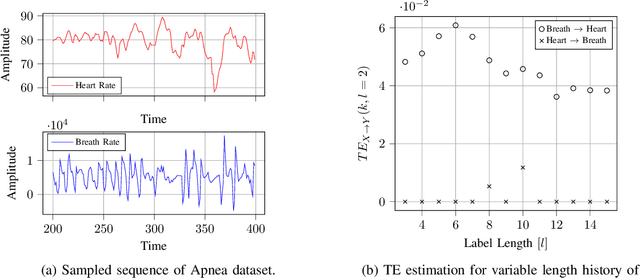


Transfer entropy (TE) is a measurement in information theory that reveals the directional flow of information between processes, providing valuable insights for a wide range of real-world applications. This work proposes Transfer Entropy Estimation via Transformers (TREET), a novel transformer-based approach for estimating the TE for stationary processes. The proposed approach employs Donsker-Vardhan (DV) representation to TE and leverages the attention mechanism for the task of neural estimation. We propose a detailed theoretical and empirical study of the TREET, comparing it to existing methods. To increase its applicability, we design an estimated TE optimization scheme that is motivated by the functional representation lemma. Afterwards, we take advantage of the joint optimization scheme to optimize the capacity of communication channels with memory, which is a canonical optimization problem in information theory, and show the memory capabilities of our estimator. Finally, we apply TREET to real-world feature analysis. Our work, applied with state-of-the-art deep learning methods, opens a new door for communication problems which are yet to be solved.
Multi-Agent Reinforcement Learning for Network Routing in Integrated Access Backhaul Networks
May 12, 2023



We investigate the problem of wireless routing in integrated access backhaul (IAB) networks consisting of fiber-connected and wireless base stations and multiple users. The physical constraints of these networks prevent the use of a central controller, and base stations have limited access to real-time network conditions. We aim to maximize packet arrival ratio while minimizing their latency, for this purpose, we formulate the problem as a multi-agent partially observed Markov decision process (POMDP). To solve this problem, we develop a Relational Advantage Actor Critic (Relational A2C) algorithm that uses Multi-Agent Reinforcement Learning (MARL) and information about similar destinations to derive a joint routing policy on a distributed basis. We present three training paradigms for this algorithm and demonstrate its ability to achieve near-centralized performance. Our results show that Relational A2C outperforms other reinforcement learning algorithms, leading to increased network efficiency and reduced selfish agent behavior. To the best of our knowledge, this work is the first to optimize routing strategy for IAB networks.
Data-Driven Optimization of Directed Information over Discrete Alphabets
Jan 02, 2023
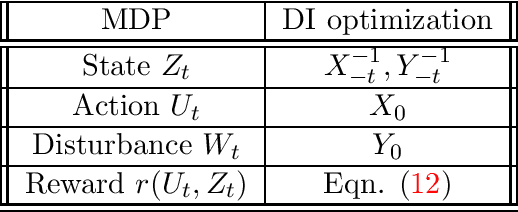


Directed information (DI) is a fundamental measure for the study and analysis of sequential stochastic models. In particular, when optimized over input distributions it characterizes the capacity of general communication channels. However, analytic computation of DI is typically intractable and existing optimization techniques over discrete input alphabets require knowledge of the channel model, which renders them inapplicable when only samples are available. To overcome these limitations, we propose a novel estimation-optimization framework for DI over discrete input spaces. We formulate DI optimization as a Markov decision process and leverage reinforcement learning techniques to optimize a deep generative model of the input process probability mass function (PMF). Combining this optimizer with the recently developed DI neural estimator, we obtain an end-to-end estimation-optimization algorithm which is applied to estimating the (feedforward and feedback) capacity of various discrete channels with memory. Furthermore, we demonstrate how to use the optimized PMF model to (i) obtain theoretical bounds on the feedback capacity of unifilar finite-state channels; and (ii) perform probabilistic shaping of constellations in the peak power-constrained additive white Gaussian noise channel.
A Study On Data Augmentation In Voice Anti-Spoofing
Oct 20, 2021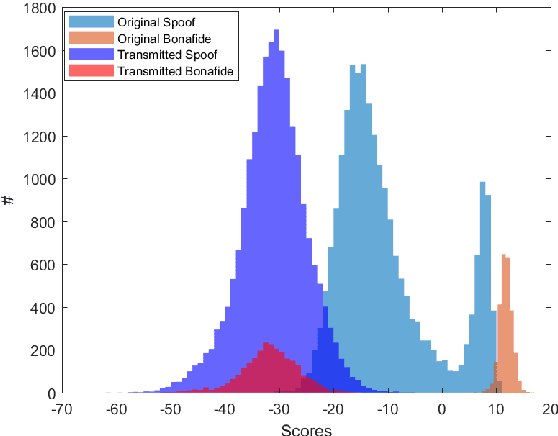
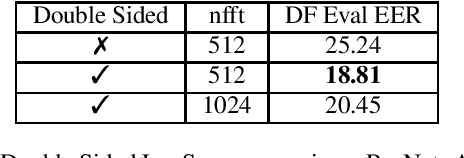
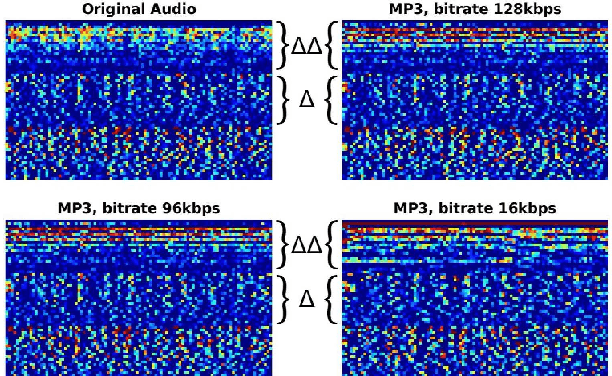

In this paper, we perform an in-depth study of how data augmentation techniques improve synthetic or spoofed audio detection. Specifically, we propose methods to deal with channel variability, different audio compressions, different band-widths, and unseen spoofing attacks, which have all been shown to significantly degrade the performance of audio-based systems and Anti-Spoofing systems. Our results are based on the ASVspoof 2021 challenge, in the Logical Access (LA) and Deep Fake (DF) categories. Our study is Data-Centric, meaning that the models are fixed and we significantly improve the results by making changes in the data. We introduce two forms of data augmentation - compression augmentation for the DF part, compression & channel augmentation for the LA part. In addition, a new type of online data augmentation, SpecAverage, is introduced in which the audio features are masked with their average value in order to improve generalization. Furthermore, we introduce a Log spectrogram feature design that improved the results. Our best single system and fusion scheme both achieve state-of-the-art performance in the DF category, with an EER of 15.46% and 14.46% respectively. Our best system for the LA task reduced the best baseline EER by 50% and the min t-DCF by 16%. Our techniques to deal with spoofed data from a wide variety of distributions can be replicated and can help anti-spoofing and speech-based systems enhance their results.