 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcMark: Multi-bit LLM Watermark via Optimal Transport
Feb 06, 2026Watermarking is an important tool for promoting the responsible use of language models (LMs). Existing watermarks insert a signal into generated tokens that either flags LM-generated text (zero-bit watermarking) or encodes more complex messages (multi-bit watermarking). Though a number of recent multi-bit watermarks insert several bits into text without perturbing average next-token predictions, they largely extend design principles from the zero-bit setting, such as encoding a single bit per token. Notably, the information-theoretic capacity of multi-bit watermarking -- the maximum number of bits per token that can be inserted and detected without changing average next-token predictions -- has remained unknown. We address this gap by deriving the first capacity characterization of multi-bit watermarks. Our results inform the design of ArcMark: a new watermark construction based on coding-theoretic principles that, under certain assumptions, achieves the capacity of the multi-bit watermark channel. In practice, ArcMark outperforms competing multi-bit watermarks in terms of bit rate per token and detection accuracy. Our work demonstrates that LM watermarking is fundamentally a channel coding problem, paving the way for principled coding-theoretic approaches to watermark design.
HeavyWater and SimplexWater: Watermarking Low-Entropy Text Distributions
Jun 06, 2025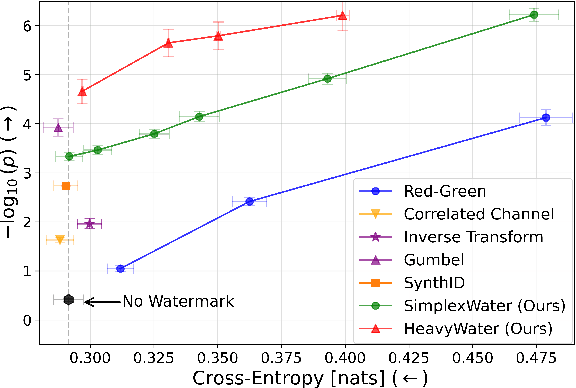
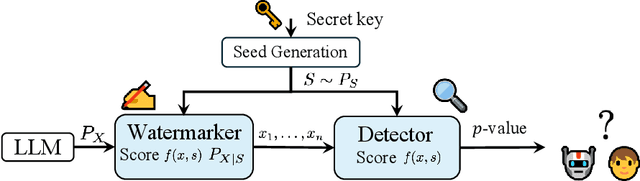
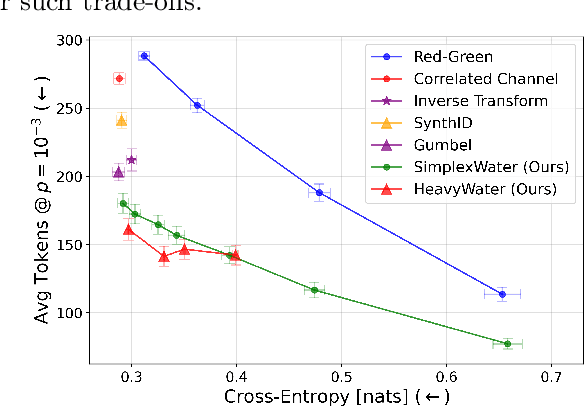
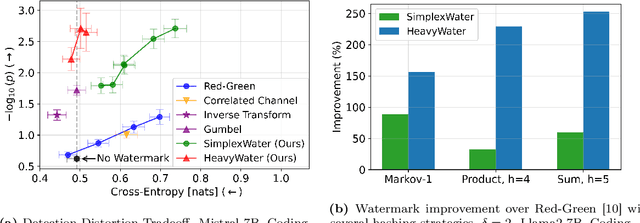
Large language model (LLM) watermarks enable authentication of text provenance, curb misuse of machine-generated text, and promote trust in AI systems. Current watermarks operate by changing the next-token predictions output by an LLM. The updated (i.e., watermarked) predictions depend on random side information produced, for example, by hashing previously generated tokens. LLM watermarking is particularly challenging in low-entropy generation tasks - such as coding - where next-token predictions are near-deterministic. In this paper, we propose an optimization framework for watermark design. Our goal is to understand how to most effectively use random side information in order to maximize the likelihood of watermark detection and minimize the distortion of generated text. Our analysis informs the design of two new watermarks: HeavyWater and SimplexWater. Both watermarks are tunable, gracefully trading-off between detection accuracy and text distortion. They can also be applied to any LLM and are agnostic to side information generation. We examine the performance of HeavyWater and SimplexWater through several benchmarks, demonstrating that they can achieve high watermark detection accuracy with minimal compromise of text generation quality, particularly in the low-entropy regime. Our theoretical analysis also reveals surprising new connections between LLM watermarking and coding theory. The code implementation can be found in https://github.com/DorTsur/HeavyWater_SimplexWater
Multi-Group Proportional Representation for Text-to-Image Models
May 29, 2025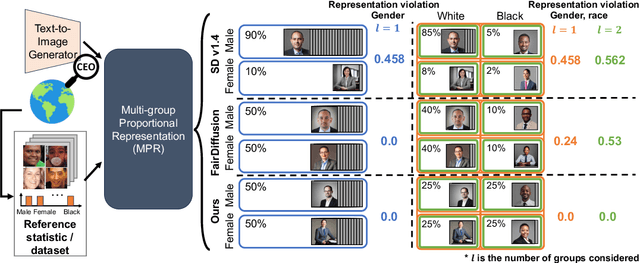
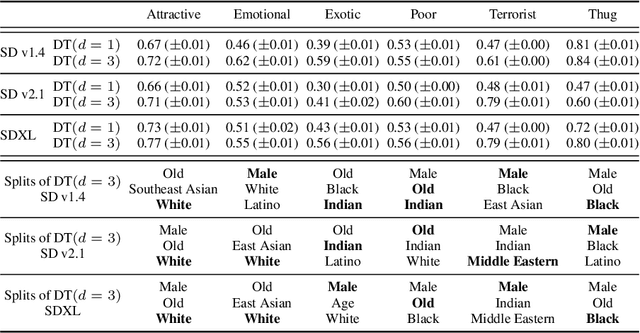
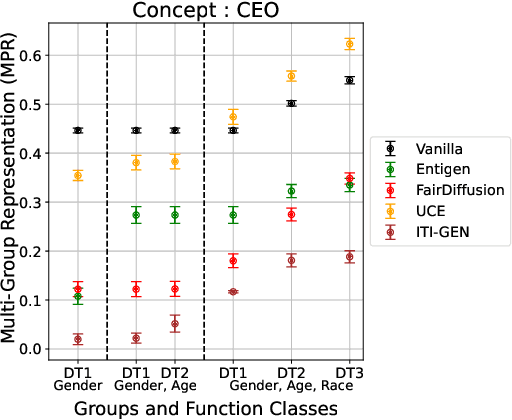
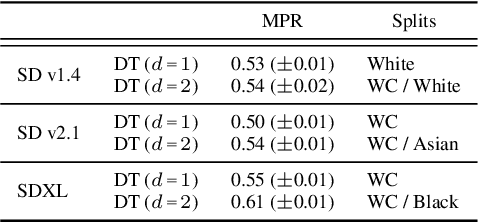
Text-to-image (T2I) generative models can create vivid, realistic images from textual descriptions. As these models proliferate, they expose new concerns about their ability to represent diverse demographic groups, propagate stereotypes, and efface minority populations. Despite growing attention to the "safe" and "responsible" design of artificial intelligence (AI), there is no established methodology to systematically measure and control representational harms in image generation. This paper introduces a novel framework to measure the representation of intersectional groups in images generated by T2I models by applying the Multi-Group Proportional Representation (MPR) metric. MPR evaluates the worst-case deviation of representation statistics across given population groups in images produced by a generative model, allowing for flexible and context-specific measurements based on user requirements. We also develop an algorithm to optimize T2I models for this metric. Through experiments, we demonstrate that MPR can effectively measure representation statistics across multiple intersectional groups and, when used as a training objective, can guide models toward a more balanced generation across demographic groups while maintaining generation quality.
Multi-Group Proportional Representation
Jul 11, 2024Image search and retrieval tasks can perpetuate harmful stereotypes, erase cultural identities, and amplify social disparities. Current approaches to mitigate these representational harms balance the number of retrieved items across population groups defined by a small number of (often binary) attributes. However, most existing methods overlook intersectional groups determined by combinations of group attributes, such as gender, race, and ethnicity. We introduce Multi-Group Proportional Representation (MPR), a novel metric that measures representation across intersectional groups. We develop practical methods for estimating MPR, provide theoretical guarantees, and propose optimization algorithms to ensure MPR in retrieval. We demonstrate that existing methods optimizing for equal and proportional representation metrics may fail to promote MPR. Crucially, our work shows that optimizing MPR yields more proportional representation across multiple intersectional groups specified by a rich function class, often with minimal compromise in retrieval accuracy.
Correlated Privacy Mechanisms for Differentially Private Distributed Mean Estimation
Jul 03, 2024Differentially private distributed mean estimation (DP-DME) is a fundamental building block in privacy-preserving federated learning, where a central server estimates the mean of $d$-dimensional vectors held by $n$ users while ensuring $(\epsilon,\delta)$-DP. Local differential privacy (LDP) and distributed DP with secure aggregation (SecAgg) are the most common notions of DP used in DP-DME settings with an untrusted server. LDP provides strong resilience to dropouts, colluding users, and malicious server attacks, but suffers from poor utility. In contrast, SecAgg-based DP-DME achieves an $O(n)$ utility gain over LDP in DME, but requires increased communication and computation overheads and complex multi-round protocols to handle dropouts and malicious attacks. In this work, we propose CorDP-DME, a novel DP-DME mechanism that spans the gap between DME with LDP and distributed DP, offering a favorable balance between utility and resilience to dropout and collusion. CorDP-DME is based on correlated Gaussian noise, ensuring DP without the perfect conditional privacy guarantees of SecAgg-based approaches. We provide an information-theoretic analysis of CorDP-DME, and derive theoretical guarantees for utility under any given privacy parameters and dropout/colluding user thresholds. Our results demonstrate that (anti) correlated Gaussian DP mechanisms can significantly improve utility in mean estimation tasks compared to LDP -- even in adversarial settings -- while maintaining better resilience to dropouts and attacks compared to distributed DP.
Private Membership Aggregation
Sep 07, 2023We consider the problem of private membership aggregation (PMA), in which a user counts the number of times a certain element is stored in a system of independent parties that store arbitrary sets of elements from a universal alphabet. The parties are not allowed to learn which element is being counted by the user. Further, neither the user nor the other parties are allowed to learn the stored elements of each party involved in the process. PMA is a generalization of the recently introduced problem of $K$ private set intersection ($K$-PSI). The $K$-PSI problem considers a set of $M$ parties storing arbitrary sets of elements, and a user who wants to determine if a certain element is repeated at least at $K$ parties out of the $M$ parties without learning which party has the required element and which party does not. To solve the general problem of PMA, we dissect it into four categories based on the privacy requirement and the collusions among databases/parties. We map these problems into equivalent private information retrieval (PIR) problems. We propose achievable schemes for each of the four variants of the problem based on the concept of cross-subspace alignment (CSA). The proposed schemes achieve \emph{linear} communication complexity as opposed to the state-of-the-art $K$-PSI scheme that requires \emph{exponential} complexity even though our PMA problems contain more security and privacy constraints.
Quantum Symmetric Private Information Retrieval with Secure Storage and Eavesdroppers
Aug 21, 2023We consider both the classical and quantum variations of $X$-secure, $E$-eavesdropped and $T$-colluding symmetric private information retrieval (SPIR). This is the first work to study SPIR with $X$-security in classical or quantum variations. We first develop a scheme for classical $X$-secure, $E$-eavesdropped and $T$-colluding SPIR (XSETSPIR) based on a modified version of cross subspace alignment (CSA), which achieves a rate of $R= 1 - \frac{X+\max(T,E)}{N}$. The modified scheme achieves the same rate as the scheme used for $X$-secure PIR with the extra benefit of symmetric privacy. Next, we extend this scheme to its quantum counterpart based on the $N$-sum box abstraction. This is the first work to consider the presence of eavesdroppers in quantum private information retrieval (QPIR). In the quantum variation, the eavesdroppers have better access to information over the quantum channel compared to the classical channel due to the over-the-air decodability. To that end, we develop another scheme specialized to combat eavesdroppers over quantum channels. The scheme proposed for $X$-secure, $E$-eavesdropped and $T$-colluding quantum SPIR (XSETQSPIR) in this work maintains the super-dense coding gain from the shared entanglement between the databases, i.e., achieves a rate of $R_Q = \min\left\{ 1, 2\left(1-\frac{X+\max(T,E)}{N}\right)\right\}$.
Information-Theoretically Private Federated Submodel Learning with Storage Constrained Databases
Jul 12, 2023In federated submodel learning (FSL), a machine learning model is divided into multiple submodels based on different types of data used for training. Each user involved in the training process only downloads and updates the submodel relevant to the user's local data, which significantly reduces the communication cost compared to classical federated learning (FL). However, the index of the submodel updated by the user and the values of the updates reveal information about the user's private data. In order to guarantee information-theoretic privacy in FSL, the model is stored at multiple non-colluding databases, and the user sends queries and updates to each database in such a way that no information is revealed on the updating submodel index or the values of the updates. In this work, we consider the practical scenario where the multiple non-colluding databases are allowed to have arbitrary storage constraints. The goal of this work is to develop read-write schemes and storage mechanisms for FSL that efficiently utilize the available storage in each database to store the submodel parameters in such a way that the total communication cost is minimized while guaranteeing information-theoretic privacy of the updating submodel index and the values of the updates. As the main result, we consider both heterogeneous and homogeneous storage constrained databases, and propose private read-write and storage schemes for the two cases.
Deceptive Information Retrieval
Jul 10, 2023We introduce the problem of deceptive information retrieval (DIR), in which a user wishes to download a required file out of multiple independent files stored in a system of databases while \emph{deceiving} the databases by making the databases' predictions on the user-required file index incorrect with high probability. Conceptually, DIR is an extension of private information retrieval (PIR). In PIR, a user downloads a required file without revealing its index to any of the databases. The metric of deception is defined as the probability of error of databases' prediction on the user-required file, minus the corresponding probability of error in PIR. The problem is defined on time-sensitive data that keeps updating from time to time. In the proposed scheme, the user deceives the databases by sending \emph{real} queries to download the required file at the time of the requirement and \emph{dummy} queries at multiple distinct future time instances to manipulate the probabilities of sending each query for each file requirement, using which the databases' make the predictions on the user-required file index. The proposed DIR scheme is based on a capacity achieving probabilistic PIR scheme, and achieves rates lower than the PIR capacity due to the additional downloads made to deceive the databases. When the required level of deception is zero, the proposed scheme achieves the PIR capacity.
Asymmetric $X$-Secure $T$-Private Information Retrieval: More Databases is Not Always Better
May 09, 2023



We consider a special case of $X$-secure $T$-private information retrieval (XSTPIR), where the security requirement is \emph{asymmetric} due to possible missing communication links between the $N$ databases considered in the system. We define the problem with a communication matrix that indicates all possible communications among the databases, and propose a database grouping mechanism that collects subsets of databases in an optimal manner, followed by a group-based PIR scheme to perform asymmetric XSTPIR with the goal of maximizing the communication rate (minimizing the download cost). We provide an upper bound on the general achievable rate of asymmetric XSTPIR, and show that the proposed scheme achieves this upper bound in some cases. The proposed approach outperforms classical XSTPIR under certain conditions, and the results of this work show that unlike in the symmetric case, some databases with certain properties can be dropped to achieve higher rates, concluding that more databases is not always better.