 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic and probabilistic neural surrogates of global hybrid-Vlasov simulations
Jan 21, 2026Hybrid-Vlasov simulations resolve ion-kinetic effects for modeling the solar wind-magnetosphere interaction, but even 5D (2D + 3V) simulations are computationally expensive. We show that graph-based machine learning emulators can learn the spatiotemporal evolution of electromagnetic fields and lower order moments of ion velocity distribution in the near-Earth space environment from four 5D Vlasiator runs performed with identical steady solar wind conditions. The initial ion number density is systematically varied, while the grid spacing is held constant, to scan the ratio of the characteristic ion skin depth to the numerical grid size. Using a graph neural network architecture operating on the 2D spatial simulation grid comprising 670k cells, we demonstrate that both a deterministic forecasting model (Graph-FM) and a probabilistic ensemble forecasting model (Graph-EFM) based on a latent variable formulation are capable of producing accurate predictions of future plasma states. A divergence penalty is incorporated during training to encourage divergence-freeness in the magnetic fields and improve physical consistency. For the probabilistic model, a continuous ranked probability score objective is added to improve the calibration of the ensemble forecasts. When trained, the emulators achieve more than two orders of magnitude speedup in generating the next time step relative to the original simulation on a single GPU compared to 100 CPUs for the Vlasiator runs, while closely matching physical magnetospheric response of the different runs. These results demonstrate that machine learning offers a way to make hybrid-Vlasov simulation tractable for real-time use while providing forecast uncertainty.
Does Privacy Always Harm Fairness? Data-Dependent Trade-offs via Chernoff Information Neural Estimation
Jan 20, 2026Fairness and privacy are two vital pillars of trustworthy machine learning. Despite extensive research on these individual topics, the relationship between fairness and privacy has received significantly less attention. In this paper, we utilize the information-theoretic measure Chernoff Information to highlight the data-dependent nature of the relationship among the triad of fairness, privacy, and accuracy. We first define Noisy Chernoff Difference, a tool that allows us to analyze the relationship among the triad simultaneously. We then show that for synthetic data, this value behaves in 3 distinct ways (depending on the distribution of the data). We highlight the data distributions involved in these cases and explore their fairness and privacy implications. Additionally, we show that Noisy Chernoff Difference acts as a proxy for the steepness of the fairness-accuracy curves. Finally, we propose a method for estimating Chernoff Information on data from unknown distributions and utilize this framework to examine the triad dynamic on real datasets. This work builds towards a unified understanding of the fairness-privacy-accuracy relationship and highlights its data-dependent nature.
CosmoFlow: Scale-Aware Representation Learning for Cosmology with Flow Matching
Jul 16, 2025Generative machine learning models have been demonstrated to be able to learn low dimensional representations of data that preserve information required for downstream tasks. In this work, we demonstrate that flow matching based generative models can learn compact, semantically rich latent representations of field level cold dark matter (CDM) simulation data without supervision. Our model, CosmoFlow, learns representations 32x smaller than the raw field data, usable for field level reconstruction, synthetic data generation, and parameter inference. Our model also learns interpretable representations, in which different latent channels correspond to features at different cosmological scales.
Gone With the Bits: Revealing Racial Bias in Low-Rate Neural Compression for Facial Images
May 05, 2025Neural compression methods are gaining popularity due to their superior rate-distortion performance over traditional methods, even at extremely low bitrates below 0.1 bpp. As deep learning architectures, these models are prone to bias during the training process, potentially leading to unfair outcomes for individuals in different groups. In this paper, we present a general, structured, scalable framework for evaluating bias in neural image compression models. Using this framework, we investigate racial bias in neural compression algorithms by analyzing nine popular models and their variants. Through this investigation, we first demonstrate that traditional distortion metrics are ineffective in capturing bias in neural compression models. Next, we highlight that racial bias is present in all neural compression models and can be captured by examining facial phenotype degradation in image reconstructions. We then examine the relationship between bias and realism in the decoded images and demonstrate a trade-off across models. Finally, we show that utilizing a racially balanced training set can reduce bias but is not a sufficient bias mitigation strategy. We additionally show the bias can be attributed to compression model bias and classification model bias. We believe that this work is a first step towards evaluating and eliminating bias in neural image compression models.
When Machine Learning Gets Personal: Understanding Fairness of Personalized Models
Feb 05, 2025



Personalization in machine learning involves tailoring models to individual users by incorporating personal attributes such as demographic or medical data. While personalization can improve prediction accuracy, it may also amplify biases and reduce explainability. This work introduces a unified framework to evaluate the impact of personalization on both prediction accuracy and explanation quality across classification and regression tasks. We derive novel upper bounds for the number of personal attributes that can be used to reliably validate benefits of personalization. Our analysis uncovers key trade-offs. We show that regression models can potentially utilize more personal attributes than classification models. We also demonstrate that improvements in prediction accuracy due to personalization do not necessarily translate to enhanced explainability -- underpinning the importance to evaluate both metrics when personalizing machine learning models in critical settings such as healthcare. Validated with a real-world dataset, this framework offers practical guidance for balancing accuracy, fairness, and interpretability in personalized models.
Mix from Failure: Confusion-Pairing Mixup for Long-Tailed Recognition
Nov 12, 2024



Long-tailed image recognition is a computer vision problem considering a real-world class distribution rather than an artificial uniform. Existing methods typically detour the problem by i) adjusting a loss function, ii) decoupling classifier learning, or iii) proposing a new multi-head architecture called experts. In this paper, we tackle the problem from a different perspective to augment a training dataset to enhance the sample diversity of minority classes. Specifically, our method, namely Confusion-Pairing Mixup (CP-Mix), estimates the confusion distribution of the model and handles the data deficiency problem by augmenting samples from confusion pairs in real-time. In this way, CP-Mix trains the model to mitigate its weakness and distinguish a pair of classes it frequently misclassifies. In addition, CP-Mix utilizes a novel mixup formulation to handle the bias in decision boundaries that originated from the imbalanced dataset. Extensive experiments demonstrate that CP-Mix outperforms existing methods for long-tailed image recognition and successfully relieves the confusion of the classifier.
LLMs are Biased Teachers: Evaluating LLM Bias in Personalized Education
Oct 17, 2024



With the increasing adoption of large language models (LLMs) in education, concerns about inherent biases in these models have gained prominence. We evaluate LLMs for bias in the personalized educational setting, specifically focusing on the models' roles as "teachers". We reveal significant biases in how models generate and select educational content tailored to different demographic groups, including race, ethnicity, sex, gender, disability status, income, and national origin. We introduce and apply two bias score metrics--Mean Absolute Bias (MAB) and Maximum Difference Bias (MDB)--to analyze 9 open and closed state-of-the-art LLMs. Our experiments, which utilize over 17,000 educational explanations across multiple difficulty levels and topics, uncover that models perpetuate both typical and inverted harmful stereotypes.
Correlated Privacy Mechanisms for Differentially Private Distributed Mean Estimation
Jul 03, 2024Differentially private distributed mean estimation (DP-DME) is a fundamental building block in privacy-preserving federated learning, where a central server estimates the mean of $d$-dimensional vectors held by $n$ users while ensuring $(\epsilon,\delta)$-DP. Local differential privacy (LDP) and distributed DP with secure aggregation (SecAgg) are the most common notions of DP used in DP-DME settings with an untrusted server. LDP provides strong resilience to dropouts, colluding users, and malicious server attacks, but suffers from poor utility. In contrast, SecAgg-based DP-DME achieves an $O(n)$ utility gain over LDP in DME, but requires increased communication and computation overheads and complex multi-round protocols to handle dropouts and malicious attacks. In this work, we propose CorDP-DME, a novel DP-DME mechanism that spans the gap between DME with LDP and distributed DP, offering a favorable balance between utility and resilience to dropout and collusion. CorDP-DME is based on correlated Gaussian noise, ensuring DP without the perfect conditional privacy guarantees of SecAgg-based approaches. We provide an information-theoretic analysis of CorDP-DME, and derive theoretical guarantees for utility under any given privacy parameters and dropout/colluding user thresholds. Our results demonstrate that (anti) correlated Gaussian DP mechanisms can significantly improve utility in mean estimation tasks compared to LDP -- even in adversarial settings -- while maintaining better resilience to dropouts and attacks compared to distributed DP.
A Survey on Data Selection for Language Models
Mar 08, 2024A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
Differentially Private Secure Multiplication: Hiding Information in the Rubble of Noise
Sep 28, 2023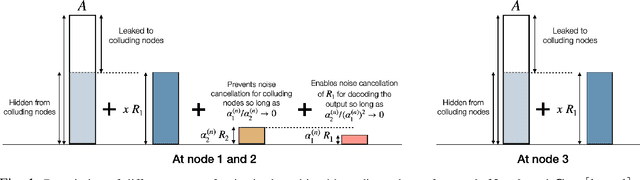

We consider the problem of private distributed multi-party multiplication. It is well-established that Shamir secret-sharing coding strategies can enable perfect information-theoretic privacy in distributed computation via the celebrated algorithm of Ben Or, Goldwasser and Wigderson (the "BGW algorithm"). However, perfect privacy and accuracy require an honest majority, that is, $N \geq 2t+1$ compute nodes are required to ensure privacy against any $t$ colluding adversarial nodes. By allowing for some controlled amount of information leakage and approximate multiplication instead of exact multiplication, we study coding schemes for the setting where the number of honest nodes can be a minority, that is $N< 2t+1.$ We develop a tight characterization privacy-accuracy trade-off for cases where $N < 2t+1$ by measuring information leakage using {differential} privacy instead of perfect privacy, and using the mean squared error metric for accuracy. A novel technical aspect is an intricately layered noise distribution that merges ideas from differential privacy and Shamir secret-sharing at different layers.