 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Generated or Human-Written? Comparing Review and Non-Review Papers on ArXiv
Jan 19, 2026ArXiv recently prohibited the upload of unpublished review papers to its servers in the Computer Science domain, citing a high prevalence of LLM-generated content in these categories. However, this decision was not accompanied by quantitative evidence. In this work, we investigate this claim by measuring the proportion of LLM-generated content in review vs. non-review research papers in recent years. Using two high-quality detection methods, we find a substantial increase in LLM-generated content across both review and non-review papers, with a higher prevalence in review papers. However, when considering the number of LLM-generated papers published in each category, the estimates of non-review LLM-generated papers are almost six times higher. Furthermore, we find that this policy will affect papers in certain domains far more than others, with the CS subdiscipline Computers & Society potentially facing cuts of 50%. Our analysis provides an evidence-based framework for evaluating such policy decisions, and we release our code to facilitate future investigations at: https://github.com/yanaiela/llm-review-arxiv.
Rewriting History: A Recipe for Interventional Analyses to Study Data Effects on Model Behavior
Oct 16, 2025We present an experimental recipe for studying the relationship between training data and language model (LM) behavior. We outline steps for intervening on data batches -- i.e., ``rewriting history'' -- and then retraining model checkpoints over that data to test hypotheses relating data to behavior. Our recipe breaks down such an intervention into stages that include selecting evaluation items from a benchmark that measures model behavior, matching relevant documents to those items, and modifying those documents before retraining and measuring the effects. We demonstrate the utility of our recipe through case studies on factual knowledge acquisition in LMs, using both cooccurrence statistics and information retrieval methods to identify documents that might contribute to knowledge learning. Our results supplement past observational analyses that link cooccurrence to model behavior, while demonstrating that extant methods for identifying relevant training documents do not fully explain an LM's ability to correctly answer knowledge questions. Overall, we outline a recipe that researchers can follow to test further hypotheses about how training data affects model behavior. Our code is made publicly available to promote future work.
On Linear Representations and Pretraining Data Frequency in Language Models
Apr 16, 2025Pretraining data has a direct impact on the behaviors and quality of language models (LMs), but we only understand the most basic principles of this relationship. While most work focuses on pretraining data's effect on downstream task behavior, we investigate its relationship to LM representations. Previous work has discovered that, in language models, some concepts are encoded `linearly' in the representations, but what factors cause these representations to form? We study the connection between pretraining data frequency and models' linear representations of factual relations. We find evidence that the formation of linear representations is strongly connected to pretraining term frequencies; specifically for subject-relation-object fact triplets, both subject-object co-occurrence frequency and in-context learning accuracy for the relation are highly correlated with linear representations. This is the case across all phases of pretraining. In OLMo-7B and GPT-J, we discover that a linear representation consistently (but not exclusively) forms when the subjects and objects within a relation co-occur at least 1k and 2k times, respectively, regardless of when these occurrences happen during pretraining. Finally, we train a regression model on measurements of linear representation quality in fully-trained LMs that can predict how often a term was seen in pretraining. Our model achieves low error even on inputs from a different model with a different pretraining dataset, providing a new method for estimating properties of the otherwise-unknown training data of closed-data models. We conclude that the strength of linear representations in LMs contains signal about the models' pretraining corpora that may provide new avenues for controlling and improving model behavior: particularly, manipulating the models' training data to meet specific frequency thresholds.
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
Better Aligned with Survey Respondents or Training Data? Unveiling Political Leanings of LLMs on U.S. Supreme Court Cases
Feb 25, 2025The increased adoption of Large Language Models (LLMs) and their potential to shape public opinion have sparked interest in assessing these models' political leanings. Building on previous research that compared LLMs and human opinions and observed political bias in system responses, we take a step further to investigate the underlying causes of such biases by empirically examining how the values and biases embedded in training corpora shape model outputs. Specifically, we propose a method to quantitatively evaluate political leanings embedded in the large pretraining corpora. Subsequently we investigate to whom are the LLMs' political leanings more aligned with, their pretrainig corpora or the surveyed human opinions. As a case study, we focus on probing the political leanings of LLMs in 32 U.S. Supreme Court cases, addressing contentious topics such as abortion and voting rights. Our findings reveal that LLMs strongly reflect the political leanings in their training data, and no strong correlation is observed with their alignment to human opinions as expressed in surveys. These results underscore the importance of responsible curation of training data and the need for robust evaluation metrics to ensure LLMs' alignment with human-centered values.
GRADE: Quantifying Sample Diversity in Text-to-Image Models
Oct 29, 2024



Text-to-image (T2I) models are remarkable at generating realistic images based on textual descriptions. However, textual prompts are inherently underspecified: they do not specify all possible attributes of the required image. This raises two key questions: Do T2I models generate diverse outputs on underspecified prompts? How can we automatically measure diversity? We propose GRADE: Granular Attribute Diversity Evaluation, an automatic method for quantifying sample diversity. GRADE leverages the world knowledge embedded in large language models and visual question-answering systems to identify relevant concept-specific axes of diversity (e.g., ``shape'' and ``color'' for the concept ``cookie''). It then estimates frequency distributions of concepts and their attributes and quantifies diversity using (normalized) entropy. GRADE achieves over 90% human agreement while exhibiting weak correlation to commonly used diversity metrics. We use GRADE to measure the overall diversity of 12 T2I models using 400 concept-attribute pairs, revealing that all models display limited variation. Further, we find that these models often exhibit default behaviors, a phenomenon where the model consistently generates concepts with the same attributes (e.g., 98% of the cookies are round). Finally, we demonstrate that a key reason for low diversity is due to underspecified captions in training data. Our work proposes a modern, semantically-driven approach to measure sample diversity and highlights the stunning homogeneity in outputs by T2I models.
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
Oct 24, 2024



Learning from human feedback has enabled the alignment of language models (LMs) with human preferences. However, directly collecting human preferences can be expensive, time-consuming, and can have high variance. An appealing alternative is to distill preferences from LMs as a source of synthetic annotations as they are more consistent, cheaper, and scale better than human annotation; however, they are also prone to biases and errors. In this work, we introduce a routing framework that combines inputs from humans and LMs to achieve better annotation quality, while reducing the total cost of human annotation. The crux of our approach is to identify preference instances that will benefit from human annotations. We formulate this as an optimization problem: given a preference dataset and an evaluation metric, we train a performance prediction model to predict a reward model's performance on an arbitrary combination of human and LM annotations and employ a routing strategy that selects a combination that maximizes predicted performance. We train the performance prediction model on MultiPref, a new preference dataset with 10K instances paired with human and LM labels. We show that the selected hybrid mixture of LM and direct human preferences using our routing framework achieves better reward model performance compared to using either one exclusively. We simulate selective human preference collection on three other datasets and show that our method generalizes well to all three. We analyze features from the routing model to identify characteristics of instances that can benefit from human feedback, e.g., prompts with a moderate safety concern or moderate intent complexity. We release the dataset, annotation platform, and source code used in this study to foster more efficient and accurate preference collection in the future.
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024
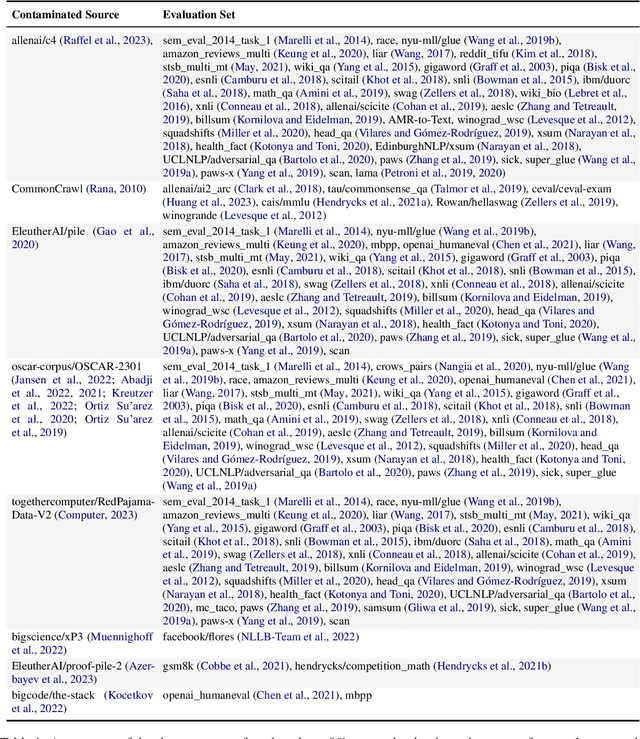
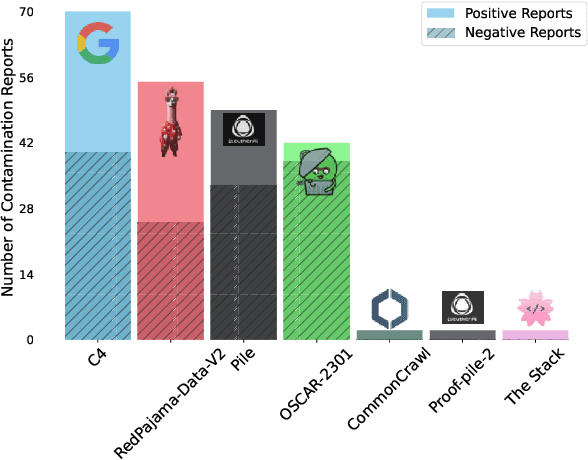
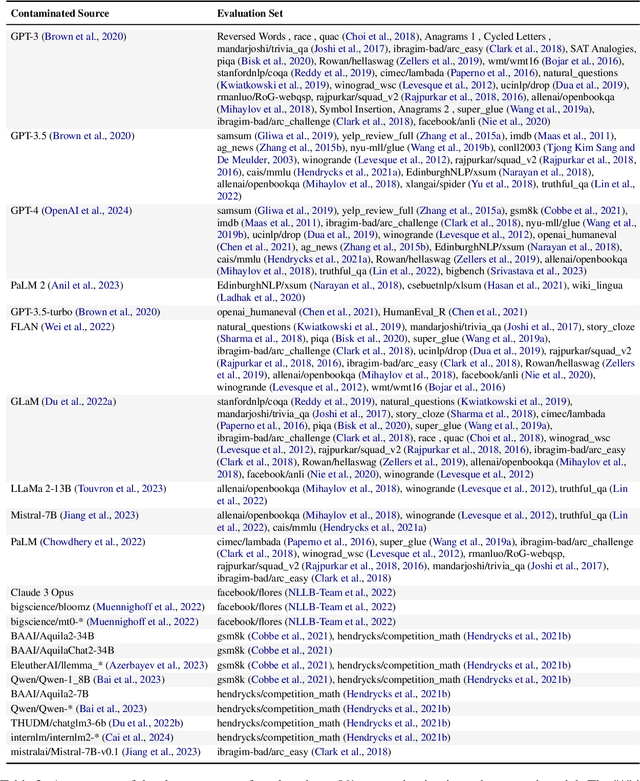
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Jul 20, 2024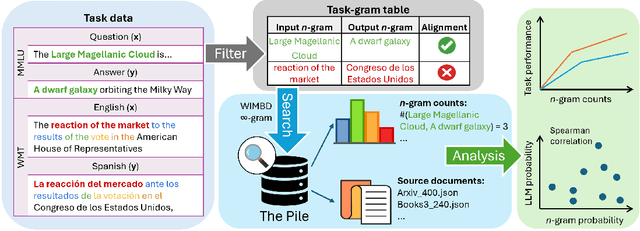
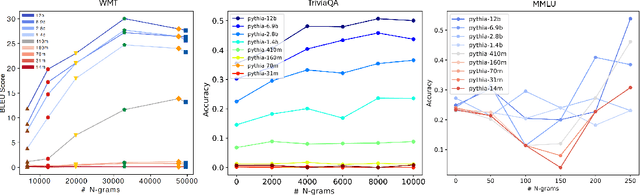
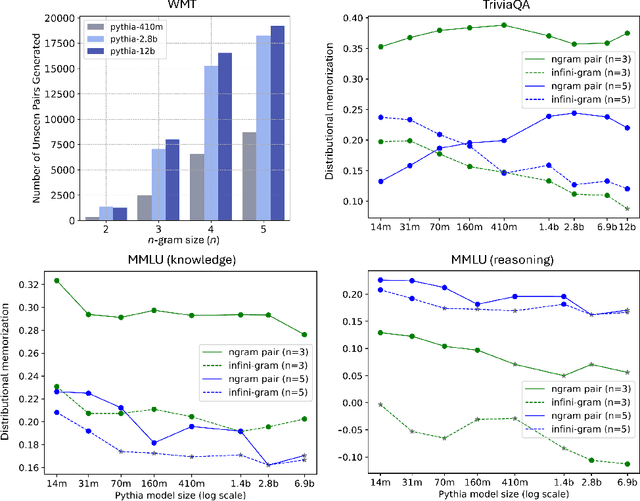
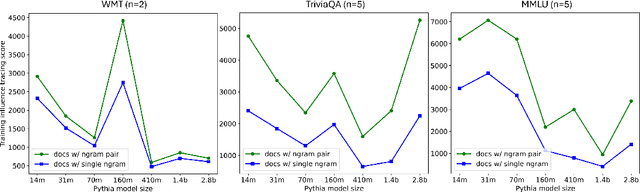
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.