 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexGenie: Automated Generation of Structured Reports for European Court of Human Rights Case Law
Mar 05, 2025Analyzing large volumes of case law to uncover evolving legal principles, across multiple cases, on a given topic is a demanding task for legal professionals. Structured topical reports provide an effective solution by summarizing key issues, principles, and judgments, enabling comprehensive legal analysis on a particular topic. While prior works have advanced query-based individual case summarization, none have extended to automatically generating multi-case structured reports. To address this, we introduce LexGenie, an automated LLM-based pipeline designed to create structured reports using the entire body of case law on user-specified topics within the European Court of Human Rights jurisdiction. LexGenie retrieves, clusters, and organizes relevant passages by topic to generate a structured outline and cohesive content for each section. Expert evaluation confirms LexGenie's utility in producing structured reports that enhance efficient, scalable legal analysis.
Better Aligned with Survey Respondents or Training Data? Unveiling Political Leanings of LLMs on U.S. Supreme Court Cases
Feb 25, 2025The increased adoption of Large Language Models (LLMs) and their potential to shape public opinion have sparked interest in assessing these models' political leanings. Building on previous research that compared LLMs and human opinions and observed political bias in system responses, we take a step further to investigate the underlying causes of such biases by empirically examining how the values and biases embedded in training corpora shape model outputs. Specifically, we propose a method to quantitatively evaluate political leanings embedded in the large pretraining corpora. Subsequently we investigate to whom are the LLMs' political leanings more aligned with, their pretrainig corpora or the surveyed human opinions. As a case study, we focus on probing the political leanings of LLMs in 32 U.S. Supreme Court cases, addressing contentious topics such as abortion and voting rights. Our findings reveal that LLMs strongly reflect the political leanings in their training data, and no strong correlation is observed with their alignment to human opinions as expressed in surveys. These results underscore the importance of responsible curation of training data and the need for robust evaluation metrics to ensure LLMs' alignment with human-centered values.
Towards Supporting Legal Argumentation with NLP: Is More Data Really All You Need?
Jun 16, 2024Modeling legal reasoning and argumentation justifying decisions in cases has always been central to AI & Law, yet contemporary developments in legal NLP have increasingly focused on statistically classifying legal conclusions from text. While conceptually simpler, these approaches often fall short in providing usable justifications connecting to appropriate legal concepts. This paper reviews both traditional symbolic works in AI & Law and recent advances in legal NLP, and distills possibilities of integrating expert-informed knowledge to strike a balance between scalability and explanation in symbolic vs. data-driven approaches. We identify open challenges and discuss the potential of modern NLP models and methods that integrate
ChronosLex: Time-aware Incremental Training for Temporal Generalization of Legal Classification Tasks
May 23, 2024



This study investigates the challenges posed by the dynamic nature of legal multi-label text classification tasks, where legal concepts evolve over time. Existing models often overlook the temporal dimension in their training process, leading to suboptimal performance of those models over time, as they treat training data as a single homogeneous block. To address this, we introduce ChronosLex, an incremental training paradigm that trains models on chronological splits, preserving the temporal order of the data. However, this incremental approach raises concerns about overfitting to recent data, prompting an assessment of mitigation strategies using continual learning and temporal invariant methods. Our experimental results over six legal multi-label text classification datasets reveal that continual learning methods prove effective in preventing overfitting thereby enhancing temporal generalizability, while temporal invariant methods struggle to capture these dynamics of temporal shifts.
CuSINeS: Curriculum-driven Structure Induced Negative Sampling for Statutory Article Retrieval
Mar 31, 2024In this paper, we introduce CuSINeS, a negative sampling approach to enhance the performance of Statutory Article Retrieval (SAR). CuSINeS offers three key contributions. Firstly, it employs a curriculum-based negative sampling strategy guiding the model to focus on easier negatives initially and progressively tackle more difficult ones. Secondly, it leverages the hierarchical and sequential information derived from the structural organization of statutes to evaluate the difficulty of samples. Lastly, it introduces a dynamic semantic difficulty assessment using the being-trained model itself, surpassing conventional static methods like BM25, adapting the negatives to the model's evolving competence. Experimental results on a real-world expert-annotated SAR dataset validate the effectiveness of CuSINeS across four different baselines, demonstrating its versatility.
Mind Your Neighbours: Leveraging Analogous Instances for Rhetorical Role Labeling for Legal Documents
Mar 31, 2024
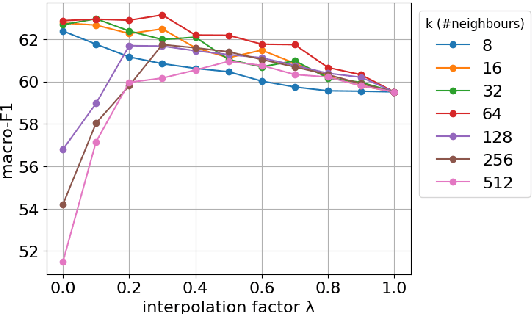

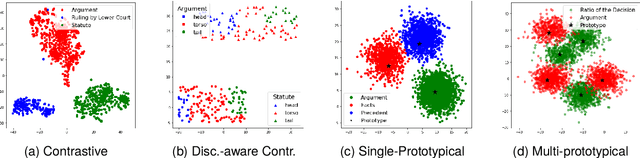
Rhetorical Role Labeling (RRL) of legal judgments is essential for various tasks, such as case summarization, semantic search and argument mining. However, it presents challenges such as inferring sentence roles from context, interrelated roles, limited annotated data, and label imbalance. This study introduces novel techniques to enhance RRL performance by leveraging knowledge from semantically similar instances (neighbours). We explore inference-based and training-based approaches, achieving remarkable improvements in challenging macro-F1 scores. For inference-based methods, we explore interpolation techniques that bolster label predictions without re-training. While in training-based methods, we integrate prototypical learning with our novel discourse-aware contrastive method that work directly on embedding spaces. Additionally, we assess the cross-domain applicability of our methods, demonstrating their effectiveness in transferring knowledge across diverse legal domains.
ECtHR-PCR: A Dataset for Precedent Understanding and Prior Case Retrieval in the European Court of Human Rights
Mar 31, 2024
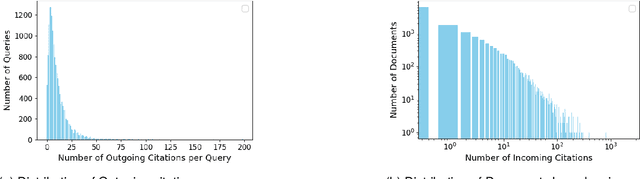


In common law jurisdictions, legal practitioners rely on precedents to construct arguments, in line with the doctrine of \emph{stare decisis}. As the number of cases grow over the years, prior case retrieval (PCR) has garnered significant attention. Besides lacking real-world scale, existing PCR datasets do not simulate a realistic setting, because their queries use complete case documents while only masking references to prior cases. The query is thereby exposed to legal reasoning not yet available when constructing an argument for an undecided case as well as spurious patterns left behind by citation masks, potentially short-circuiting a comprehensive understanding of case facts and legal principles. To address these limitations, we introduce a PCR dataset based on judgements from the European Court of Human Rights (ECtHR), which explicitly separate facts from arguments and exhibit precedential practices, aiding us to develop this PCR dataset to foster systems' comprehensive understanding. We benchmark different lexical and dense retrieval approaches with various negative sampling strategies, adapting them to deal with long text sequences using hierarchical variants. We found that difficulty-based negative sampling strategies were not effective for the PCR task, highlighting the need for investigation into domain-specific difficulty criteria. Furthermore, we observe performance of the dense models degrade with time and calls for further research into temporal adaptation of retrieval models. Additionally, we assess the influence of different views , Halsbury's and Goodhart's, in practice in ECtHR jurisdiction using PCR task.
Query-driven Relevant Paragraph Extraction from Legal Judgments
Mar 31, 2024



Legal professionals often grapple with navigating lengthy legal judgements to pinpoint information that directly address their queries. This paper focus on this task of extracting relevant paragraphs from legal judgements based on the query. We construct a specialized dataset for this task from the European Court of Human Rights (ECtHR) using the case law guides. We assess the performance of current retrieval models in a zero-shot way and also establish fine-tuning benchmarks using various models. The results highlight the significant gap between fine-tuned and zero-shot performance, emphasizing the challenge of handling distribution shift in the legal domain. We notice that the legal pre-training handles distribution shift on the corpus side but still struggles on query side distribution shift, with unseen legal queries. We also explore various Parameter Efficient Fine-Tuning (PEFT) methods to evaluate their practicality within the context of information retrieval, shedding light on the effectiveness of different PEFT methods across diverse configurations with pre-training and model architectures influencing the choice of PEFT method.
LexAbSumm: Aspect-based Summarization of Legal Decisions
Mar 31, 2024Legal professionals frequently encounter long legal judgments that hold critical insights for their work. While recent advances have led to automated summarization solutions for legal documents, they typically provide generic summaries, which may not meet the diverse information needs of users. To address this gap, we introduce LexAbSumm, a novel dataset designed for aspect-based summarization of legal case decisions, sourced from the European Court of Human Rights jurisdiction. We evaluate several abstractive summarization models tailored for longer documents on LexAbSumm, revealing a challenge in conditioning these models to produce aspect-specific summaries. We release LexAbSum to facilitate research in aspect-based summarization for legal domain.
Beyond Borders: Investigating Cross-Jurisdiction Transfer in Legal Case Summarization
Mar 28, 2024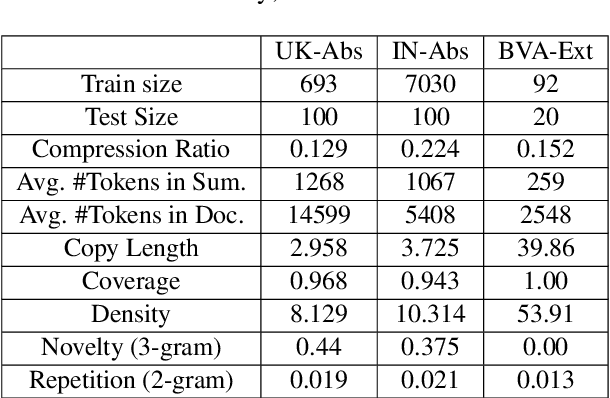
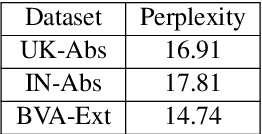
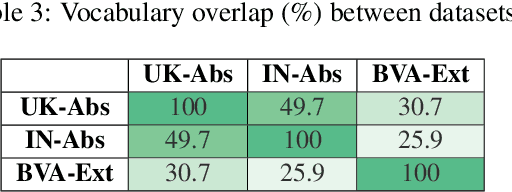
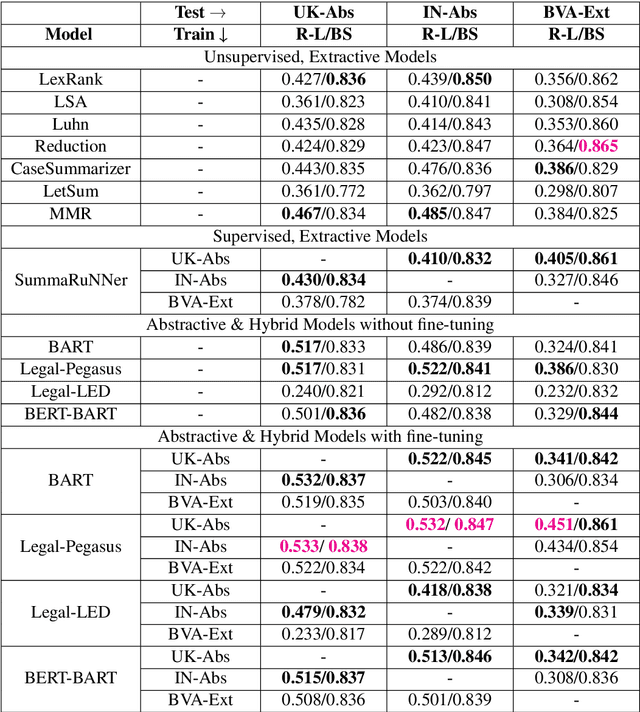
Legal professionals face the challenge of managing an overwhelming volume of lengthy judgments, making automated legal case summarization crucial. However, prior approaches mainly focused on training and evaluating these models within the same jurisdiction. In this study, we explore the cross-jurisdictional generalizability of legal case summarization models.Specifically, we explore how to effectively summarize legal cases of a target jurisdiction where reference summaries are not available. In particular, we investigate whether supplementing models with unlabeled target jurisdiction corpus and extractive silver summaries obtained from unsupervised algorithms on target data enhances transfer performance. Our comprehensive study on three datasets from different jurisdictions highlights the role of pre-training in improving transfer performance. We shed light on the pivotal influence of jurisdictional similarity in selecting optimal source datasets for effective transfer. Furthermore, our findings underscore that incorporating unlabeled target data yields improvements in general pre-trained models, with additional gains when silver summaries are introduced. This augmentation is especially valuable when dealing with extractive datasets and scenarios featuring limited alignment between source and target jurisdictions. Our study provides key insights for developing adaptable legal case summarization systems, transcending jurisdictional boundaries.