 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILSIC: Corpora for Identifying Indian Legal Statutes from Queries by Laypeople
Jan 31, 2026Legal Statute Identification (LSI) for a given situation is one of the most fundamental tasks in Legal NLP. This task has traditionally been modeled using facts from court judgments as input queries, due to their abundance. However, in practical settings, the input queries are likely to be informal and asked by laypersons, or non-professionals. While a few laypeople LSI datasets exist, there has been little research to explore the differences between court and laypeople data for LSI. In this work, we create ILSIC, a corpus of laypeople queries covering 500+ statutes from Indian law. Additionally, the corpus also contains court case judgements to enable researchers to effectively compare between court and laypeople data for LSI. We conducted extensive experiments on our corpus, including benchmarking over the laypeople dataset using zero and few-shot inference, retrieval-augmented generation and supervised fine-tuning. We observe that models trained purely on court judgements are ineffective during test on laypeople queries, while transfer learning from court to laypeople data can be beneficial in certain scenarios. We also conducted fine-grained analyses of our results in terms of categories of queries and frequency of statutes.
A Computational Approach to Visual Metonymy
Jan 25, 2026Images often communicate more than they literally depict: a set of tools can suggest an occupation and a cultural artifact can suggest a tradition. This kind of indirect visual reference, known as visual metonymy, invites viewers to recover a target concept via associated cues rather than explicit depiction. In this work, we present the first computational investigation of visual metonymy. We introduce a novel pipeline grounded in semiotic theory that leverages large language models and text-to-image models to generate metonymic visual representations. Using this framework, we construct ViMET, the first visual metonymy dataset comprising 2,000 multiple-choice questions to evaluate the cognitive reasoning abilities in multimodal language models. Experimental results on our dataset reveal a significant gap between human performance (86.9%) and state-of-the-art vision-language models (65.9%), highlighting limitations in machines' ability to interpret indirect visual references. Our dataset is publicly available at: https://github.com/cincynlp/ViMET.
Do LLM hallucination detectors suffer from low-resource effect?
Jan 23, 2026LLMs, while outperforming humans in a wide range of tasks, can still fail in unanticipated ways. We focus on two pervasive failure modes: (i) hallucinations, where models produce incorrect information about the world, and (ii) the low-resource effect, where the models show impressive performance in high-resource languages like English but the performance degrades significantly in low-resource languages like Bengali. We study the intersection of these issues and ask: do hallucination detectors suffer from the low-resource effect? We conduct experiments on five tasks across three domains (factual recall, STEM, and Humanities). Experiments with four LLMs and three hallucination detectors reveal a curious finding: As expected, the task accuracies in low-resource languages experience large drops (compared to English). However, the drop in detectors' accuracy is often several times smaller than the drop in task accuracy. Our findings suggest that even in low-resource languages, the internal mechanisms of LLMs might encode signals about their uncertainty. Further, the detectors are robust within language (even for non-English) and in multilingual setups, but not in cross-lingual settings without in-language supervision.
Evaluating the Impact of Verbal Multiword Expressions on Machine Translation
Aug 24, 2025Verbal multiword expressions (VMWEs) present significant challenges for natural language processing due to their complex and often non-compositional nature. While machine translation models have seen significant improvement with the advent of language models in recent years, accurately translating these complex linguistic structures remains an open problem. In this study, we analyze the impact of three VMWE categories -- verbal idioms, verb-particle constructions, and light verb constructions -- on machine translation quality from English to multiple languages. Using both established multiword expression datasets and sentences containing these language phenomena extracted from machine translation datasets, we evaluate how state-of-the-art translation systems handle these expressions. Our experimental results consistently show that VMWEs negatively affect translation quality. We also propose an LLM-based paraphrasing approach that replaces these expressions with their literal counterparts, demonstrating significant improvement in translation quality for verbal idioms and verb-particle constructions.
Brevity is the soul of sustainability: Characterizing LLM response lengths
Jun 10, 2025



A significant portion of the energy consumed by Large Language Models (LLMs) arises from their inference processes; hence developing energy-efficient methods for inference is crucial. While several techniques exist for inference optimization, output compression remains relatively unexplored, with only a few preliminary efforts addressing this aspect. In this work, we first benchmark 12 decoder-only LLMs across 5 datasets, revealing that these models often produce responses that are substantially longer than necessary. We then conduct a comprehensive quality assessment of LLM responses, formally defining six information categories present in LLM responses. We show that LLMs often tend to include redundant or additional information besides the minimal answer. To address this issue of long responses by LLMs, we explore several simple and intuitive prompt-engineering strategies. Empirical evaluation shows that appropriate prompts targeting length reduction and controlling information content can achieve significant energy optimization between 25-60\% by reducing the response length while preserving the quality of LLM responses.
Label-semantics Aware Generative Approach for Domain-Agnostic Multilabel Classification
Jun 07, 2025



The explosion of textual data has made manual document classification increasingly challenging. To address this, we introduce a robust, efficient domain-agnostic generative model framework for multi-label text classification. Instead of treating labels as mere atomic symbols, our approach utilizes predefined label descriptions and is trained to generate these descriptions based on the input text. During inference, the generated descriptions are matched to the pre-defined labels using a finetuned sentence transformer. We integrate this with a dual-objective loss function, combining cross-entropy loss and cosine similarity of the generated sentences with the predefined target descriptions, ensuring both semantic alignment and accuracy. Our proposed model LAGAMC stands out for its parameter efficiency and versatility across diverse datasets, making it well-suited for practical applications. We demonstrate the effectiveness of our proposed model by achieving new state-of-the-art performances across all evaluated datasets, surpassing several strong baselines. We achieve improvements of 13.94% in Micro-F1 and 24.85% in Macro-F1 compared to the closest baseline across all datasets.
ConMeC: A Dataset for Metonymy Resolution with Common Nouns
Feb 10, 2025



Metonymy plays an important role in our daily communication. People naturally think about things using their most salient properties or commonly related concepts. For example, by saying "The bus decided to skip our stop today," we actually mean that the bus driver made the decision, not the bus. Prior work on metonymy resolution has mainly focused on named entities. However, metonymy involving common nouns (such as desk, baby, and school) is also a frequent and challenging phenomenon. We argue that NLP systems should be capable of identifying the metonymic use of common nouns in context. We create a new metonymy dataset ConMeC, which consists of 6,000 sentences, where each sentence is paired with a target common noun and annotated by humans to indicate whether that common noun is used metonymically or not in that context. We also introduce a chain-of-thought based prompting method for detecting metonymy using large language models (LLMs). We evaluate our LLM-based pipeline, as well as a supervised BERT model on our dataset and three other metonymy datasets. Our experimental results demonstrate that LLMs could achieve performance comparable to the supervised BERT model on well-defined metonymy categories, while still struggling with instances requiring nuanced semantic understanding. Our dataset is publicly available at: https://github.com/SaptGhosh/ConMeC.
Towards Sustainable NLP: Insights from Benchmarking Inference Energy in Large Language Models
Feb 08, 2025



Large language models (LLMs) are increasingly recognized for their exceptional generative capabilities and versatility across various tasks. However, the high inference costs associated with these models have not received adequate attention, particularly when compared to the focus on training costs in existing research. In response to this gap, our study conducts a comprehensive benchmarking of LLM inference energy across a wide range of NLP tasks, where we analyze the impact of different models, tasks, prompts, and system-related factors on inference energy. Specifically, our experiments reveal several interesting insights, including strong correlation of inference energy with output token length and response time. Also, we find that quantization and optimal batch sizes, along with targeted prompt phrases, can significantly reduce energy usage. This study is the first to thoroughly benchmark LLM inference across such a diverse range of aspects, providing insights and offering several recommendations for improving energy efficiency in model deployment.
ICPR 2024 Competition on Multilingual Claim-Span Identification
Nov 29, 2024A lot of claims are made in social media posts, which may contain misinformation or fake news. Hence, it is crucial to identify claims as a first step towards claim verification. Given the huge number of social media posts, the task of identifying claims needs to be automated. This competition deals with the task of 'Claim Span Identification' in which, given a text, parts / spans that correspond to claims are to be identified. This task is more challenging than the traditional binary classification of text into claim or not-claim, and requires state-of-the-art methods in Pattern Recognition, Natural Language Processing and Machine Learning. For this competition, we used a newly developed dataset called HECSI containing about 8K posts in English and about 8K posts in Hindi with claim-spans marked by human annotators. This paper gives an overview of the competition, and the solutions developed by the participating teams.
AI-Native Multi-Access Future Networks -- The REASON Architecture
Nov 25, 2024

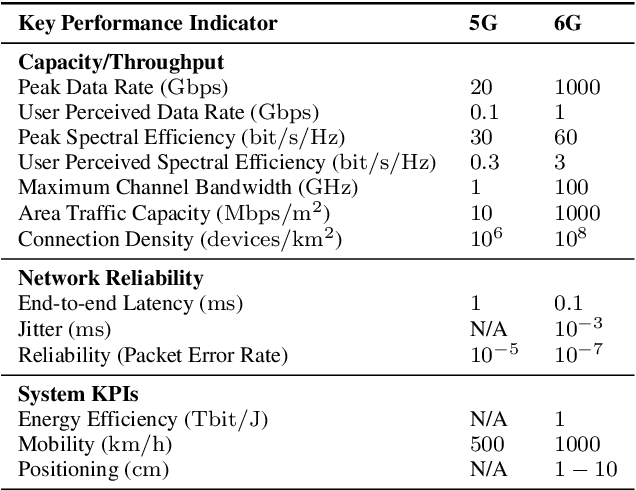
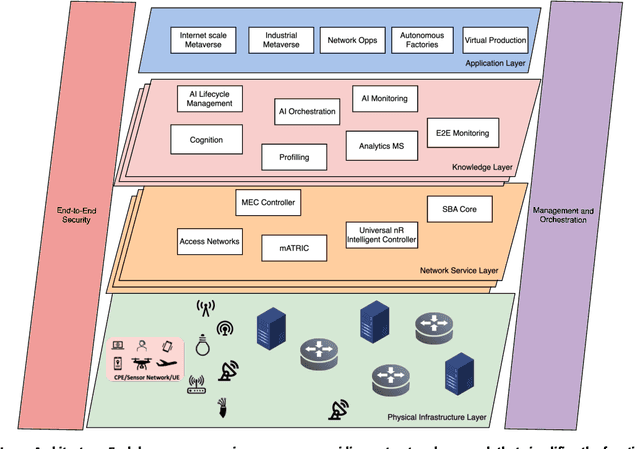
The development of the sixth generation of communication networks (6G) has been gaining momentum over the past years, with a target of being introduced by 2030. Several initiatives worldwide are developing innovative solutions and setting the direction for the key features of these networks. Some common emerging themes are the tight integration of AI, the convergence of multiple access technologies and sustainable operation, aiming to meet stringent performance and societal requirements. To that end, we are introducing REASON - Realising Enabling Architectures and Solutions for Open Networks. The REASON project aims to address technical challenges in future network deployments, such as E2E service orchestration, sustainability, security and trust management, and policy management, utilising AI-native principles, considering multiple access technologies and cloud-native solutions. This paper presents REASON's architecture and the identified requirements for future networks. The architecture is meticulously designed for modularity, interoperability, scalability, simplified troubleshooting, flexibility, and enhanced security, taking into consideration current and future standardisation efforts, and the ease of implementation and training. It is structured into four horizontal layers: Physical Infrastructure, Network Service, Knowledge, and End-User Application, complemented by two vertical layers: Management and Orchestration, and E2E Security. This layered approach ensures a robust, adaptable framework to support the diverse and evolving requirements of 6G networks, fostering innovation and facilitating seamless integration of advanced technologies.