 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Energy Savings with Speculative Decoding Strategies
Feb 09, 2026Speculative decoding has emerged as an effective method to reduce latency and inference cost of LLM inferences. However, there has been inadequate attention towards the energy requirements of these models. To address this gap, this paper presents a comprehensive survey of energy requirements of speculative decoding strategies, with detailed analysis on how various factors -- model size and family, speculative decoding strategies, and dataset characteristics -- influence the energy optimizations.
Brevity is the soul of sustainability: Characterizing LLM response lengths
Jun 10, 2025



A significant portion of the energy consumed by Large Language Models (LLMs) arises from their inference processes; hence developing energy-efficient methods for inference is crucial. While several techniques exist for inference optimization, output compression remains relatively unexplored, with only a few preliminary efforts addressing this aspect. In this work, we first benchmark 12 decoder-only LLMs across 5 datasets, revealing that these models often produce responses that are substantially longer than necessary. We then conduct a comprehensive quality assessment of LLM responses, formally defining six information categories present in LLM responses. We show that LLMs often tend to include redundant or additional information besides the minimal answer. To address this issue of long responses by LLMs, we explore several simple and intuitive prompt-engineering strategies. Empirical evaluation shows that appropriate prompts targeting length reduction and controlling information content can achieve significant energy optimization between 25-60\% by reducing the response length while preserving the quality of LLM responses.
Towards Sustainable NLP: Insights from Benchmarking Inference Energy in Large Language Models
Feb 08, 2025



Large language models (LLMs) are increasingly recognized for their exceptional generative capabilities and versatility across various tasks. However, the high inference costs associated with these models have not received adequate attention, particularly when compared to the focus on training costs in existing research. In response to this gap, our study conducts a comprehensive benchmarking of LLM inference energy across a wide range of NLP tasks, where we analyze the impact of different models, tasks, prompts, and system-related factors on inference energy. Specifically, our experiments reveal several interesting insights, including strong correlation of inference energy with output token length and response time. Also, we find that quantization and optimal batch sizes, along with targeted prompt phrases, can significantly reduce energy usage. This study is the first to thoroughly benchmark LLM inference across such a diverse range of aspects, providing insights and offering several recommendations for improving energy efficiency in model deployment.
Offsetting Unequal Competition through RL-assisted Incentive Schemes
Jan 05, 2022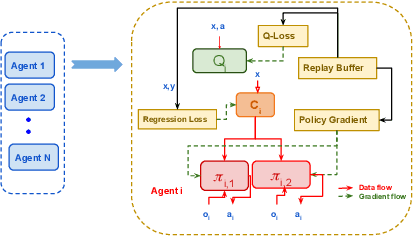

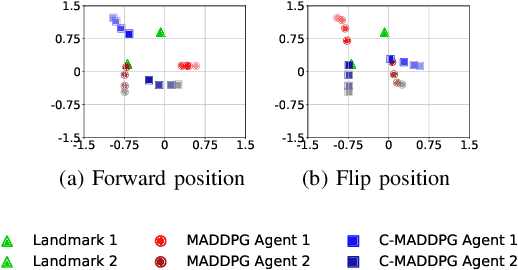

This paper investigates the dynamics of competition among organizations with unequal expertise. Multi-agent reinforcement learning has been used to simulate and understand the impact of various incentive schemes designed to offset such inequality. We design Touch-Mark, a game based on well-known multi-agent-particle-environment, where two teams (weak, strong) with unequal but changing skill levels compete against each other. For training such a game, we propose a novel controller assisted multi-agent reinforcement learning algorithm \our\, which empowers each agent with an ensemble of policies along with a supervised controller that by selectively partitioning the sample space, triggers intelligent role division among the teammates. Using C-MADDPG as an underlying framework, we propose an incentive scheme for the weak team such that the final rewards of both teams become the same. We find that in spite of the incentive, the final reward of the weak team falls short of the strong team. On inspecting, we realize that an overall incentive scheme for the weak team does not incentivize the weaker agents within that team to learn and improve. To offset this, we now specially incentivize the weaker player to learn and as a result, observe that the weak team beyond an initial phase performs at par with the stronger team. The final goal of the paper has been to formulate a dynamic incentive scheme that continuously balances the reward of the two teams. This is achieved by devising an incentive scheme enriched with an RL agent which takes minimum information from the environment.
Demarcating Endogenous and Exogenous Opinion Dynamics: An Experimental Design Approach
Feb 11, 2021
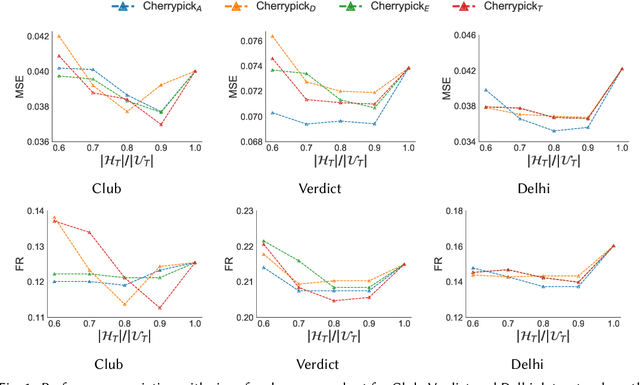
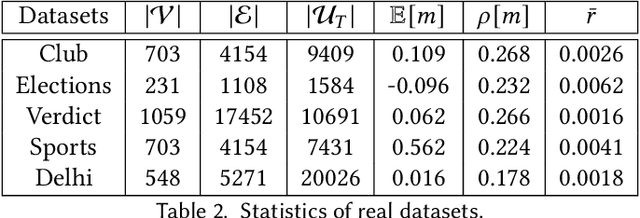

The networked opinion diffusion in online social networks (OSN) is often governed by the two genres of opinions - endogenous opinions that are driven by the influence of social contacts among users, and exogenous opinions which are formed by external effects like news, feeds etc. Accurate demarcation of endogenous and exogenous messages offers an important cue to opinion modeling, thereby enhancing its predictive performance. In this paper, we design a suite of unsupervised classification methods based on experimental design approaches, in which, we aim to select the subsets of events which minimize different measures of mean estimation error. In more detail, we first show that these subset selection tasks are NP-Hard. Then we show that the associated objective functions are weakly submodular, which allows us to cast efficient approximation algorithms with guarantees. Finally, we validate the efficacy of our proposal on various real-world datasets crawled from Twitter as well as diverse synthetic datasets. Our experiments range from validating prediction performance on unsanitized and sanitized events to checking the effect of selecting optimal subsets of various sizes. Through various experiments, we have found that our method offers a significant improvement in accuracy in terms of opinion forecasting, against several competitors.
* 25 Pages, Accepted in ACM TKDD, 2021
Regression Under Human Assistance
Sep 18, 2019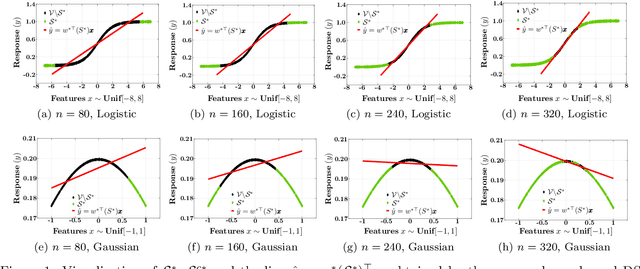
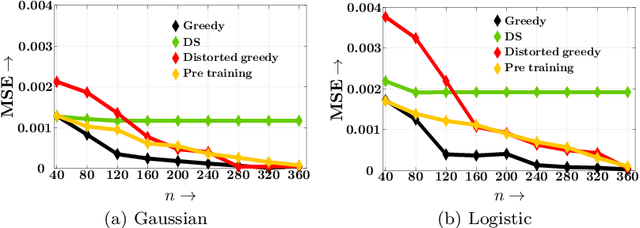
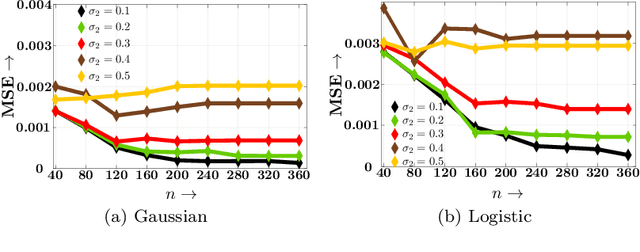
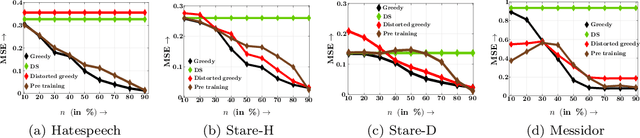
Decisions are increasingly taken by both humans and machine learning models. However, machine learning models are currently trained for full automation-they are not aware that some of the decisions may still be taken by humans. In this paper, we take a first step towards making machine learning models aware of the presence of human decision-makers. More specifically, we first introduce the problem of ridge regression under human assistance and show that it is NP-hard. Then, we derive an alternative representation of the corresponding objective function as a difference of nondecreasing submodular functions. Building on this representation, we further show that the objective is nondecreasing and satisfies \xi-submodularity, a recently introduced notion of approximate submodularity. These properties allow simple and efficient greedy algorithm to enjoy approximation guarantees at solving the problem. Experiments on synthetic and real-world data from two important applications-medical diagnoses and content moderation-demonstrate that the greedy algorithm beats several competitive baselines.
Generative Maximum Entropy Learning for Multiclass Classification
Dec 30, 2013Maximum entropy approach to classification is very well studied in applied statistics and machine learning and almost all the methods that exists in literature are discriminative in nature. In this paper, we introduce a maximum entropy classification method with feature selection for large dimensional data such as text datasets that is generative in nature. To tackle the curse of dimensionality of large data sets, we employ conditional independence assumption (Naive Bayes) and we perform feature selection simultaneously, by enforcing a `maximum discrimination' between estimated class conditional densities. For two class problems, in the proposed method, we use Jeffreys ($J$) divergence to discriminate the class conditional densities. To extend our method to the multi-class case, we propose a completely new approach by considering a multi-distribution divergence: we replace Jeffreys divergence by Jensen-Shannon ($JS$) divergence to discriminate conditional densities of multiple classes. In order to reduce computational complexity, we employ a modified Jensen-Shannon divergence ($JS_{GM}$), based on AM-GM inequality. We show that the resulting divergence is a natural generalization of Jeffreys divergence to a multiple distributions case. As far as the theoretical justifications are concerned we show that when one intends to select the best features in a generative maximum entropy approach, maximum discrimination using $J-$divergence emerges naturally in binary classification. Performance and comparative study of the proposed algorithms have been demonstrated on large dimensional text and gene expression datasets that show our methods scale up very well with large dimensional datasets.