 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferent Statistical Perspectives for Understanding Generalisation in Graph Neural Networks
May 25, 2026Graph Neural Networks (GNN) are currently the most popular approach for learning and prediction on graph-structured data and are deployed in various fields, from social network analysis to drug discovery. However, there is limited mathematical understanding of the performance of GNNs. We discuss the various perspectives used to study statistical generalisation in GNNs. We identify three broad frameworks. The first approach, rooted in learning theory, relies on uniform convergence bounds and the complexity of the hypothesis class of specific GNN architectures. This approach also builds on the expressivity of GNNs, typically studied through the lens of graph isomorphism tests. The second principle is to simplify the neural architecture by analysing GNNs under the asymptotics of infinitely many parameters or infinite graph size. This approach approximates GNNs using Gaussian processes, neural tangent kernels or graphon neural network operators, which allow studying the generalisation or stability of trained GNNs. The third framework studies GNNs under random graph models, often the contextual stochastic block model, and derives non-asymptotic error rates using tools from high-dimensional statistics. We highlight some key theoretical results and discuss a few limitations and open research questions for each perspective.
Exact Certification of Neural Networks and Partition Aggregation Ensembles against Label Poisoning
Apr 13, 2026Label-flipping attacks, which corrupt training labels to induce misclassifications at inference, remain a major threat to supervised learning models. This drives the need for robustness certificates that provide formal guarantees about a model's robustness under adversarially corrupted labels. Existing certification frameworks rely on ensemble techniques such as smoothing or partition-aggregation, but treat the corresponding base classifiers as black boxes, yielding overly conservative guarantees. We introduce EnsembleCert, the first certification framework for partition-aggregation ensembles that utilizes white-box knowledge of the base classifiers. Concretely, EnsembleCert yields tighter guarantees than black-box approaches by aggregating per-partition white-box certificates to compute ensemble-level guarantees in polynomial time. To extract white-box knowledge from the base classifiers efficiently, we develop ScaLabelCert, a method that leverages the equivalence between sufficiently wide neural networks and kernel methods using the neural tangent kernel. ScaLabelCert yields the first exact, polynomial-time calculable certificate for neural networks against label-flipping attacks. EnsembleCert is either on par, or significantly outperforms the existing partition-based black box certificates. Exemplary, on CIFAR-10, our method can certify upto +26.5% more label flips in median over the test set compared to the existing black-box approach while requiring 100 times fewer partitions, thus, challenging the prevailing notion that heavy partitioning is a necessity for strong certified robustness.
Gaussian Process Limit Reveals Structural Benefits of Graph Transformers
Mar 18, 2026Graph transformers are the state-of-the-art for learning from graph-structured data and are empirically known to avoid several pitfalls of message-passing architectures. However, there is limited theoretical analysis on why these models perform well in practice. In this work, we prove that attention-based architectures have structural benefits over graph convolutional networks in the context of node-level prediction tasks. Specifically, we study the neural network gaussian process limits of graph transformers (GAT, Graphormer, Specformer) with infinite width and infinite heads, and derive the node-level and edge-level kernels across the layers. Our results characterise how the node features and the graph structure propagate through the graph attention layers. As a specific example, we prove that graph transformers structurally preserve community information and maintain discriminative node representations even in deep layers, thereby preventing oversmoothing. We provide empirical evidence on synthetic and real-world graphs that validate our theoretical insights, such as integrating informative priors and positional encoding can improve performance of deep graph transformers.
Nonparametric Kernel Clustering with Bandit Feedback
Jan 12, 2026Clustering with bandit feedback refers to the problem of partitioning a set of items, where the clustering algorithm can sequentially query the items to receive noisy observations. The problem is formally posed as the task of partitioning the arms of an N-armed stochastic bandit according to their underlying distributions, grouping two arms together if and only if they share the same distribution, using samples collected sequentially and adaptively. This setting has gained attention in recent years due to its applicability in recommendation systems and crowdsourcing. Existing works on clustering with bandit feedback rely on a strong assumption that the underlying distributions are sub-Gaussian. As a consequence, the existing methods mainly cover settings with linearly-separable clusters, which has little practical relevance. We introduce a framework of ``nonparametric clustering with bandit feedback'', where the underlying arm distributions are not constrained to any parametric, and hence, it is applicable for active clustering of real-world datasets. We adopt a kernel-based approach, which allows us to reformulate the nonparametric problem as the task of clustering the arms according to their kernel mean embeddings in a reproducing kernel Hilbert space (RKHS). Building on this formulation, we introduce the KABC algorithm with theoretical correctness guarantees and analyze its sampling budget. We introduce a notion of signal-to-noise ratio for this problem that depends on the maximum mean discrepancy (MMD) between the arm distributions and on their variance in the RKHS. Our algorithm is adaptive to this unknown quantity: it does not require it as an input yet achieves instance-dependent guarantees.
Robustness Certificates for Neural Networks against Adversarial Attacks
Dec 24, 2025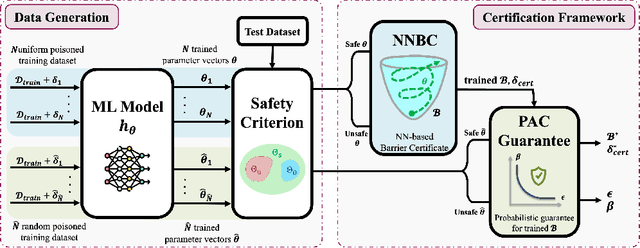
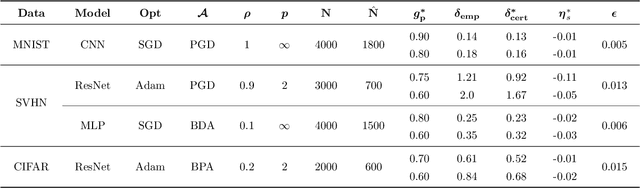
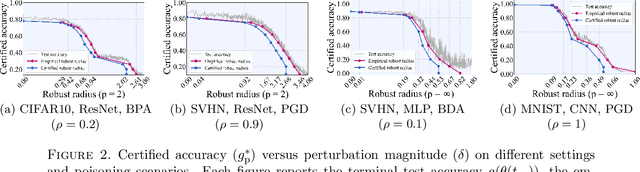
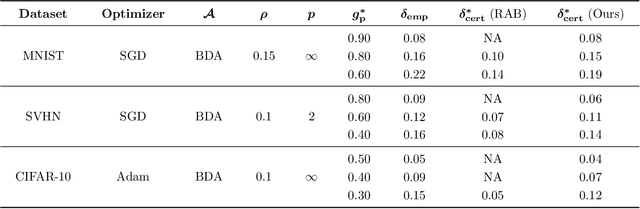
The increasing use of machine learning in safety-critical domains amplifies the risk of adversarial threats, especially data poisoning attacks that corrupt training data to degrade performance or induce unsafe behavior. Most existing defenses lack formal guarantees or rely on restrictive assumptions about the model class, attack type, extent of poisoning, or point-wise certification, limiting their practical reliability. This paper introduces a principled formal robustness certification framework that models gradient-based training as a discrete-time dynamical system (dt-DS) and formulates poisoning robustness as a formal safety verification problem. By adapting the concept of barrier certificates (BCs) from control theory, we introduce sufficient conditions to certify a robust radius ensuring that the terminal model remains safe under worst-case ${\ell}_p$-norm based poisoning. To make this practical, we parameterize BCs as neural networks trained on finite sets of poisoned trajectories. We further derive probably approximately correct (PAC) bounds by solving a scenario convex program (SCP), which yields a confidence lower bound on the certified robustness radius generalizing beyond the training set. Importantly, our framework also extends to certification against test-time attacks, making it the first unified framework to provide formal guarantees in both training and test-time attack settings. Experiments on MNIST, SVHN, and CIFAR-10 show that our approach certifies non-trivial perturbation budgets while being model-agnostic and requiring no prior knowledge of the attack or contamination level.
Impact of Bottleneck Layers and Skip Connections on the Generalization of Linear Denoising Autoencoders
May 30, 2025


Modern deep neural networks exhibit strong generalization even in highly overparameterized regimes. Significant progress has been made to understand this phenomenon in the context of supervised learning, but for unsupervised tasks such as denoising, several open questions remain. While some recent works have successfully characterized the test error of the linear denoising problem, they are limited to linear models (one-layer network). In this work, we focus on two-layer linear denoising autoencoders trained under gradient flow, incorporating two key ingredients of modern deep learning architectures: A low-dimensional bottleneck layer that effectively enforces a rank constraint on the learned solution, as well as the possibility of a skip connection that bypasses the bottleneck. We derive closed-form expressions for all critical points of this model under product regularization, and in particular describe its global minimizer under the minimum-norm principle. From there, we derive the test risk formula in the overparameterized regime, both for models with and without skip connections. Our analysis reveals two interesting phenomena: Firstly, the bottleneck layer introduces an additional complexity measure akin to the classical bias-variance trade-off -- increasing the bottleneck width reduces bias but introduces variance, and vice versa. Secondly, skip connection can mitigate the variance in denoising autoencoders -- especially when the model is mildly overparameterized. We further analyze the impact of skip connections in denoising autoencoder using random matrix theory and support our claims with numerical evidence.
Generalization Certificates for Adversarially Robust Bayesian Linear Regression
Feb 20, 2025
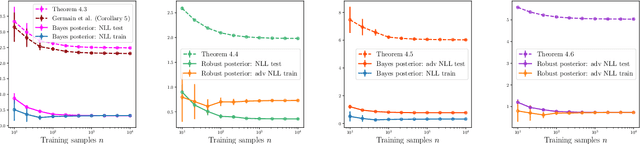
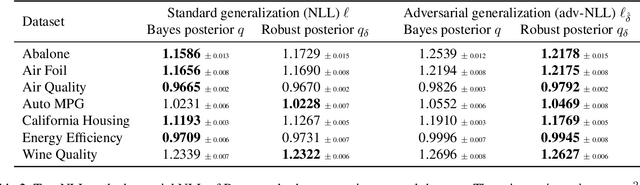
Adversarial robustness of machine learning models is critical to ensuring reliable performance under data perturbations. Recent progress has been on point estimators, and this paper considers distributional predictors. First, using the link between exponential families and Bregman divergences, we formulate an adversarial Bregman divergence loss as an adversarial negative log-likelihood. Using the geometric properties of Bregman divergences, we compute the adversarial perturbation for such models in closed-form. Second, under such losses, we introduce \emph{adversarially robust posteriors}, by exploiting the optimization-centric view of generalized Bayesian inference. Third, we derive the \emph{first} rigorous generalization certificates in the context of an adversarial extension of Bayesian linear regression by leveraging the PAC-Bayesian framework. Finally, experiments on real and synthetic datasets demonstrate the superior robustness of the derived adversarially robust posterior over Bayes posterior, and also validate our theoretical guarantees.
Attention Learning is Needed to Efficiently Learn Parity Function
Feb 11, 2025

Transformers, with their attention mechanisms, have emerged as the state-of-the-art architectures of sequential modeling and empirically outperform feed-forward neural networks (FFNNs) across many fields, such as natural language processing and computer vision. However, their generalization ability, particularly for low-sensitivity functions, remains less studied. We bridge this gap by analyzing transformers on the $k$-parity problem. Daniely and Malach (NeurIPS 2020) show that FFNNs with one hidden layer and $O(nk^7 \log k)$ parameters can learn $k$-parity, where the input length $n$ is typically much larger than $k$. In this paper, we prove that FFNNs require at least $\Omega(n)$ parameters to learn $k$-parity, while transformers require only $O(k)$ parameters, surpassing the theoretical lower bound needed by FFNNs. We further prove that this parameter efficiency cannot be achieved with fixed attention heads. Our work establishes transformers as theoretically superior to FFNNs in learning parity function, showing how their attention mechanisms enable parameter-efficient generalization in functions with low sensitivity.
Recovering Imbalanced Clusters via Gradient-Based Projection Pursuit
Feb 04, 2025



Projection Pursuit is a classic exploratory technique for finding interesting projections of a dataset. We propose a method for recovering projections containing either Imbalanced Clusters or a Bernoulli-Rademacher distribution using a gradient-based technique to optimize the projection index. As sample complexity is a major limiting factor in Projection Pursuit, we analyze our algorithm's sample complexity within a Planted Vector setting where we can observe that Imbalanced Clusters can be recovered more easily than balanced ones. Additionally, we give a generalized result that works for a variety of data distributions and projection indices. We compare these results to computational lower bounds in the Low-Degree-Polynomial Framework. Finally, we experimentally evaluate our method's applicability to real-world data using FashionMNIST and the Human Activity Recognition Dataset, where our algorithm outperforms others when only a few samples are available.
Tight PAC-Bayesian Risk Certificates for Contrastive Learning
Dec 05, 2024
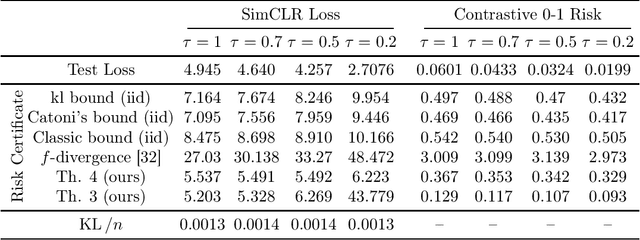
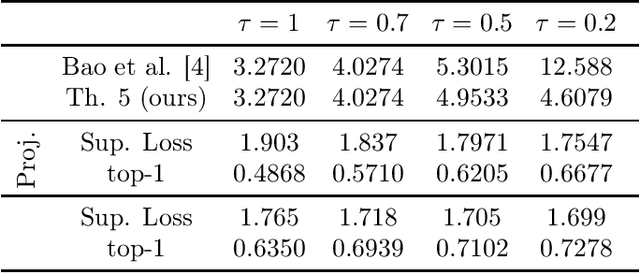
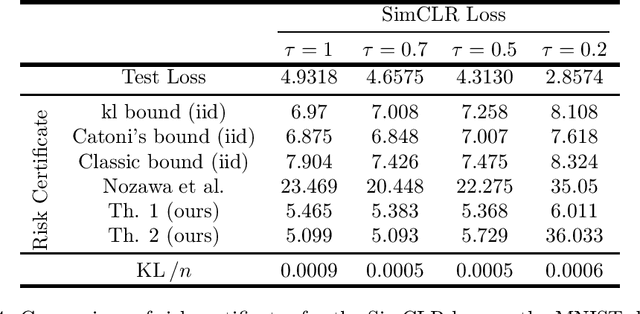
Contrastive representation learning is a modern paradigm for learning representations of unlabeled data via augmentations -- precisely, contrastive models learn to embed semantically similar pairs of samples (positive pairs) closer than independently drawn samples (negative samples). In spite of its empirical success and widespread use in foundation models, statistical theory for contrastive learning remains less explored. Recent works have developed generalization error bounds for contrastive losses, but the resulting risk certificates are either vacuous (certificates based on Rademacher complexity or $f$-divergence) or require strong assumptions about samples that are unreasonable in practice. The present paper develops non-vacuous PAC-Bayesian risk certificates for contrastive representation learning, considering the practical considerations of the popular SimCLR framework. Notably, we take into account that SimCLR reuses positive pairs of augmented data as negative samples for other data, thereby inducing strong dependence and making classical PAC or PAC-Bayesian bounds inapplicable. We further refine existing bounds on the downstream classification loss by incorporating SimCLR-specific factors, including data augmentation and temperature scaling, and derive risk certificates for the contrastive zero-one risk. The resulting bounds for contrastive loss and downstream prediction are much tighter than those of previous risk certificates, as demonstrated by experiments on CIFAR-10.