 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Quantization Benefits of Residual-Free Transformers
May 25, 2026Large-scale transformer training and deployment are increasingly constrained by the transfer of activations, gradients, and optimizer states across accelerators. Low-bit quantization offers a natural remedy, but transformer activations are often heavy-tailed and outlier-dominated, making simple quantization highly lossy. We show that this difficulty is not only a property of the quantizer, but also of the architecture. Specifically, residual connections can drive transformer activations away from Gaussianity during training. Using controlled comparisons between residual and residual-free transformers, we demonstrate that this effect leads to substantially higher quantization error and accuracy degradation at low precision in residual models. We explain the phenomenon through an excess kurtosis analysis, showing that residual mixing can amplify non-Gaussianity, whereas dense mixing in residual-free contracts non-Gaussianity. We then show that residual-free transformers can be made trainable using orthogonal initialization, spectral or second-order optimization, and depth-aware scaling of attention temperature. In language tasks, while there is a small drop in full precision performance, these models retain near-Gaussian activations and exhibit significantly improved robustness to low-bit quantization. Our results identify an accuracy--compressibility trade-off in transformer design and motivate architecture-level approaches to quantization-friendly foundation models.
Different Statistical Perspectives for Understanding Generalisation in Graph Neural Networks
May 25, 2026Graph Neural Networks (GNN) are currently the most popular approach for learning and prediction on graph-structured data and are deployed in various fields, from social network analysis to drug discovery. However, there is limited mathematical understanding of the performance of GNNs. We discuss the various perspectives used to study statistical generalisation in GNNs. We identify three broad frameworks. The first approach, rooted in learning theory, relies on uniform convergence bounds and the complexity of the hypothesis class of specific GNN architectures. This approach also builds on the expressivity of GNNs, typically studied through the lens of graph isomorphism tests. The second principle is to simplify the neural architecture by analysing GNNs under the asymptotics of infinitely many parameters or infinite graph size. This approach approximates GNNs using Gaussian processes, neural tangent kernels or graphon neural network operators, which allow studying the generalisation or stability of trained GNNs. The third framework studies GNNs under random graph models, often the contextual stochastic block model, and derives non-asymptotic error rates using tools from high-dimensional statistics. We highlight some key theoretical results and discuss a few limitations and open research questions for each perspective.
Exact Certification of Neural Networks and Partition Aggregation Ensembles against Label Poisoning
Apr 13, 2026Label-flipping attacks, which corrupt training labels to induce misclassifications at inference, remain a major threat to supervised learning models. This drives the need for robustness certificates that provide formal guarantees about a model's robustness under adversarially corrupted labels. Existing certification frameworks rely on ensemble techniques such as smoothing or partition-aggregation, but treat the corresponding base classifiers as black boxes, yielding overly conservative guarantees. We introduce EnsembleCert, the first certification framework for partition-aggregation ensembles that utilizes white-box knowledge of the base classifiers. Concretely, EnsembleCert yields tighter guarantees than black-box approaches by aggregating per-partition white-box certificates to compute ensemble-level guarantees in polynomial time. To extract white-box knowledge from the base classifiers efficiently, we develop ScaLabelCert, a method that leverages the equivalence between sufficiently wide neural networks and kernel methods using the neural tangent kernel. ScaLabelCert yields the first exact, polynomial-time calculable certificate for neural networks against label-flipping attacks. EnsembleCert is either on par, or significantly outperforms the existing partition-based black box certificates. Exemplary, on CIFAR-10, our method can certify upto +26.5% more label flips in median over the test set compared to the existing black-box approach while requiring 100 times fewer partitions, thus, challenging the prevailing notion that heavy partitioning is a necessity for strong certified robustness.
Robustness Certificates for Neural Networks against Adversarial Attacks
Dec 24, 2025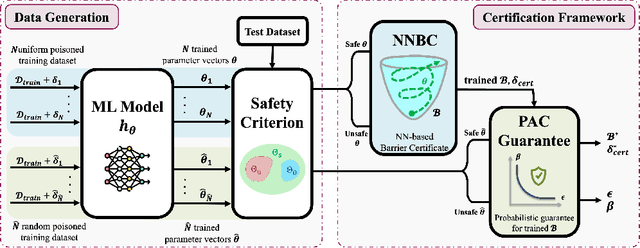
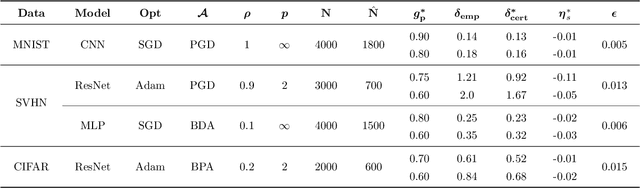
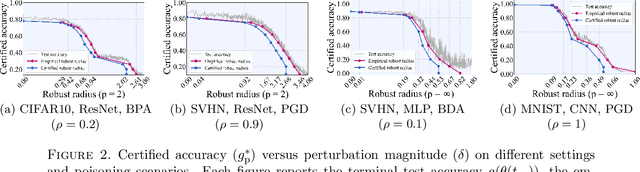
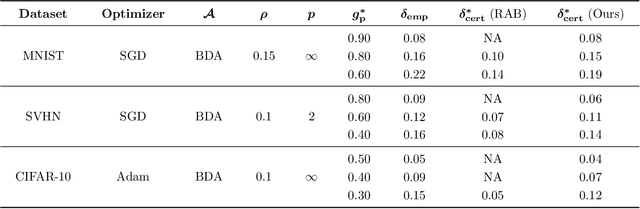
The increasing use of machine learning in safety-critical domains amplifies the risk of adversarial threats, especially data poisoning attacks that corrupt training data to degrade performance or induce unsafe behavior. Most existing defenses lack formal guarantees or rely on restrictive assumptions about the model class, attack type, extent of poisoning, or point-wise certification, limiting their practical reliability. This paper introduces a principled formal robustness certification framework that models gradient-based training as a discrete-time dynamical system (dt-DS) and formulates poisoning robustness as a formal safety verification problem. By adapting the concept of barrier certificates (BCs) from control theory, we introduce sufficient conditions to certify a robust radius ensuring that the terminal model remains safe under worst-case ${\ell}_p$-norm based poisoning. To make this practical, we parameterize BCs as neural networks trained on finite sets of poisoned trajectories. We further derive probably approximately correct (PAC) bounds by solving a scenario convex program (SCP), which yields a confidence lower bound on the certified robustness radius generalizing beyond the training set. Importantly, our framework also extends to certification against test-time attacks, making it the first unified framework to provide formal guarantees in both training and test-time attack settings. Experiments on MNIST, SVHN, and CIFAR-10 show that our approach certifies non-trivial perturbation budgets while being model-agnostic and requiring no prior knowledge of the attack or contamination level.
Generalization Certificates for Adversarially Robust Bayesian Linear Regression
Feb 20, 2025
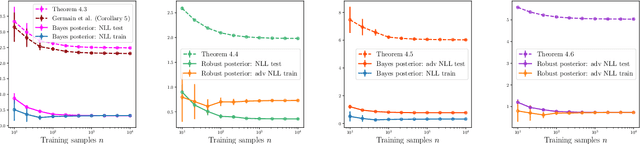
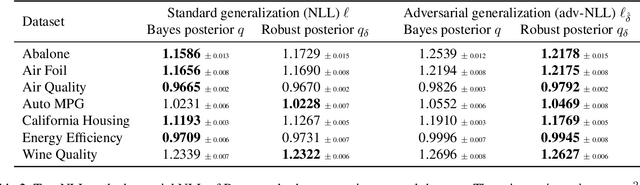
Adversarial robustness of machine learning models is critical to ensuring reliable performance under data perturbations. Recent progress has been on point estimators, and this paper considers distributional predictors. First, using the link between exponential families and Bregman divergences, we formulate an adversarial Bregman divergence loss as an adversarial negative log-likelihood. Using the geometric properties of Bregman divergences, we compute the adversarial perturbation for such models in closed-form. Second, under such losses, we introduce \emph{adversarially robust posteriors}, by exploiting the optimization-centric view of generalized Bayesian inference. Third, we derive the \emph{first} rigorous generalization certificates in the context of an adversarial extension of Bayesian linear regression by leveraging the PAC-Bayesian framework. Finally, experiments on real and synthetic datasets demonstrate the superior robustness of the derived adversarially robust posterior over Bayes posterior, and also validate our theoretical guarantees.
Cluster Specific Representation Learning
Dec 04, 2024Representation learning aims to extract meaningful lower-dimensional embeddings from data, known as representations. Despite its widespread application, there is no established definition of a ``good'' representation. Typically, the representation quality is evaluated based on its performance in downstream tasks such as clustering, de-noising, etc. However, this task-specific approach has a limitation where a representation that performs well for one task may not necessarily be effective for another. This highlights the need for a more agnostic formulation, which is the focus of our work. We propose a downstream-agnostic formulation: when inherent clusters exist in the data, the representations should be specific to each cluster. Under this idea, we develop a meta-algorithm that jointly learns cluster-specific representations and cluster assignments. As our approach is easy to integrate with any representation learning framework, we demonstrate its effectiveness in various setups, including Autoencoders, Variational Autoencoders, Contrastive learning models, and Restricted Boltzmann Machines. We qualitatively compare our cluster-specific embeddings to standard embeddings and downstream tasks such as de-noising and clustering. While our method slightly increases runtime and parameters compared to the standard model, the experiments clearly show that it extracts the inherent cluster structures in the data, resulting in improved performance in relevant applications.
Exact Certification of (Graph) Neural Networks Against Label Poisoning
Nov 30, 2024



Machine learning models are highly vulnerable to label flipping, i.e., the adversarial modification (poisoning) of training labels to compromise performance. Thus, deriving robustness certificates is important to guarantee that test predictions remain unaffected and to understand worst-case robustness behavior. However, for Graph Neural Networks (GNNs), the problem of certifying label flipping has so far been unsolved. We change this by introducing an exact certification method, deriving both sample-wise and collective certificates. Our method leverages the Neural Tangent Kernel (NTK) to capture the training dynamics of wide networks enabling us to reformulate the bilevel optimization problem representing label flipping into a Mixed-Integer Linear Program (MILP). We apply our method to certify a broad range of GNN architectures in node classification tasks. Thereby, concerning the worst-case robustness to label flipping: $(i)$ we establish hierarchies of GNNs on different benchmark graphs; $(ii)$ quantify the effect of architectural choices such as activations, depth and skip-connections; and surprisingly, $(iii)$ uncover a novel phenomenon of the robustness plateauing for intermediate perturbation budgets across all investigated datasets and architectures. While we focus on GNNs, our certificates are applicable to sufficiently wide NNs in general through their NTK. Thus, our work presents the first exact certificate to a poisoning attack ever derived for neural networks, which could be of independent interest.
Provable Robustness of (Graph) Neural Networks Against Data Poisoning and Backdoor Attacks
Jul 15, 2024
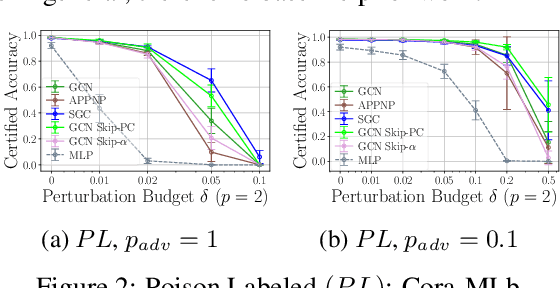
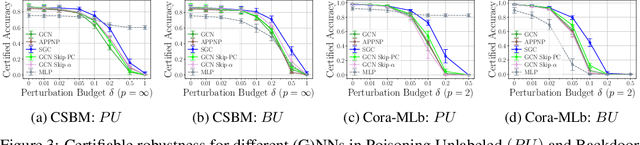
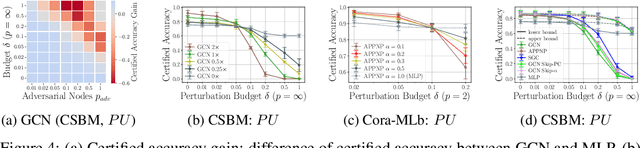
Generalization of machine learning models can be severely compromised by data poisoning, where adversarial changes are applied to the training data, as well as backdoor attacks that additionally manipulate the test data. These vulnerabilities have led to interest in certifying (i.e., proving) that such changes up to a certain magnitude do not affect test predictions. We, for the first time, certify Graph Neural Networks (GNNs) against poisoning and backdoor attacks targeting the node features of a given graph. Our certificates are white-box and based upon $(i)$ the neural tangent kernel, which characterizes the training dynamics of sufficiently wide networks; and $(ii)$ a novel reformulation of the bilevel optimization problem describing poisoning as a mixed-integer linear program. Consequently, we leverage our framework to provide fundamental insights into the role of graph structure and its connectivity on the worst-case robustness behavior of convolution-based and PageRank-based GNNs. We note that our framework is more general and constitutes the first approach to derive white-box poisoning certificates for NNs, which can be of independent interest beyond graph-related tasks.
Fast Adaptive Test-Time Defense with Robust Features
Jul 21, 2023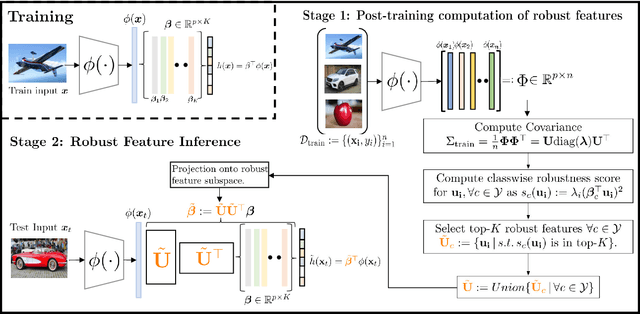

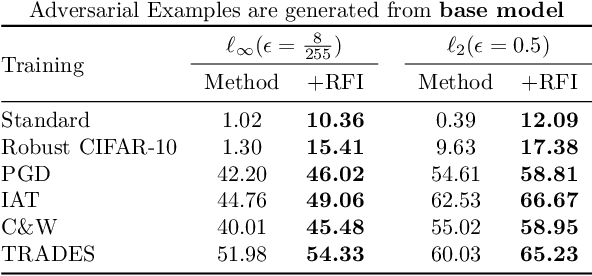
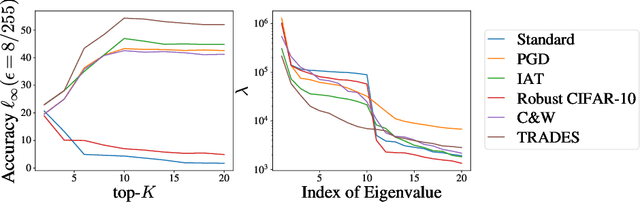
Adaptive test-time defenses are used to improve the robustness of deep neural networks to adversarial examples. However, existing methods significantly increase the inference time due to additional optimization on the model parameters or the input at test time. In this work, we propose a novel adaptive test-time defense strategy that is easy to integrate with any existing (robust) training procedure without additional test-time computation. Based on the notion of robustness of features that we present, the key idea is to project the trained models to the most robust feature space, thereby reducing the vulnerability to adversarial attacks in non-robust directions. We theoretically show that the top eigenspace of the feature matrix are more robust for a generalized additive model and support our argument for a large width neural network with the Neural Tangent Kernel (NTK) equivalence. We conduct extensive experiments on CIFAR-10 and CIFAR-100 datasets for several robustness benchmarks, including the state-of-the-art methods in RobustBench, and observe that the proposed method outperforms existing adaptive test-time defenses at much lower computation costs.
Kernels, Data & Physics
Jul 05, 2023Lecture notes from the course given by Professor Julia Kempe at the summer school "Statistical physics of Machine Learning" in Les Houches. The notes discuss the so-called NTK approach to problems in machine learning, which consists of gaining an understanding of generally unsolvable problems by finding a tractable kernel formulation. The notes are mainly focused on practical applications such as data distillation and adversarial robustness, examples of inductive bias are also discussed.