 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Linear and Overcomplete Regimes: A Mean-Field Analysis of Bottleneck Autoencoders
Jun 05, 2026Autoencoders (AEs) learn low-dimensional representations by mapping data into a latent space while minimizing reconstruction error. Despite their empirical success, theoretical understanding remains limited and largely restricted to linear models or settings without a bottleneck. In this work, we study nonlinear AEs with a fixed finite-dimensional bottleneck in the mean-field (MF) regime. We derive explicit MF learning dynamics for both encoder and decoder, providing a tractable characterization of training in the nonlinear setting. We show that, over finite time horizons, the empirical risk of finite-width networks trained with stochastic gradient descent closely tracks the MF risk trajectory with high probability. At optimality, we further establish that the finite-width risk converges to the MF optimum, demonstrating that finite networks are sufficiently expressive to approximate the infinite-width solution.
Gaussian mixtures and non-parametric likelihoods through the lens of statistical mechanics
Mar 24, 2026In this work, we investigate Gaussian Mixture Models ({\it abbrv} GMM) and the related problem of non parametric maximum likelihood estimation ({\it abbrv} NPMLE) from the perspective of statistical mechanics. In particular, we establish stability guarantees for the NPMLE procedure that extend well beyond the state of the art. Crucially, we obtain guarantees on the Kullback-Leibler divergence between NPMLE estimators and the ground truth, a type of result which has been known to be challenging in the literature on this problem. In particular, we provide high probability upper bounds on the KL divergence between the NPMLE and the true density that are of the order of $\min\big\{\frac{(\log n)^{d+2}}{n} , \frac{\log n}{\sqrt n}\big\}$, which cover a wide range of scenarios for the comparative sizes of $n$ and $d$. We obtain similar guarantees for approximate solutions to the NPMLE problem, addressing realistic situations wherein optimization algorithms need to be stopped in finite time, allowing access only to approximations to the true NPMLE. A technical cornerstone of our approach is an analysis of the function class complexity of logarithms of gaussian mixture densities, which is able to handle their unboundedness, and could be of wider interest. We also establish correspondences between stability phenomena in the NPMLE problem and concepts from chaos and multiple valleys in random energy landscapes of statistical mechanics models. We believe that these correspondences may be useful for a wide variety of random optimization problems in statistics and machine learning, especially the connections to the the technical ingredients of concentration phenomena and Langevin dynamics for these models.
Recovering Imbalanced Clusters via Gradient-Based Projection Pursuit
Feb 04, 2025



Projection Pursuit is a classic exploratory technique for finding interesting projections of a dataset. We propose a method for recovering projections containing either Imbalanced Clusters or a Bernoulli-Rademacher distribution using a gradient-based technique to optimize the projection index. As sample complexity is a major limiting factor in Projection Pursuit, we analyze our algorithm's sample complexity within a Planted Vector setting where we can observe that Imbalanced Clusters can be recovered more easily than balanced ones. Additionally, we give a generalized result that works for a variety of data distributions and projection indices. We compare these results to computational lower bounds in the Low-Degree-Polynomial Framework. Finally, we experimentally evaluate our method's applicability to real-world data using FashionMNIST and the Human Activity Recognition Dataset, where our algorithm outperforms others when only a few samples are available.
Representation Learning Dynamics of Self-Supervised Models
Sep 05, 2023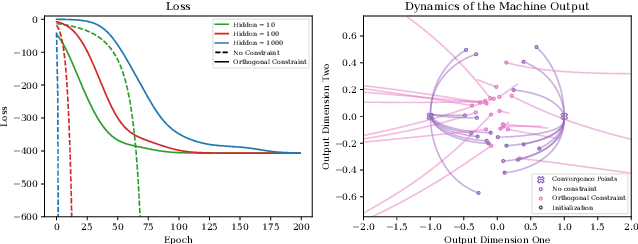
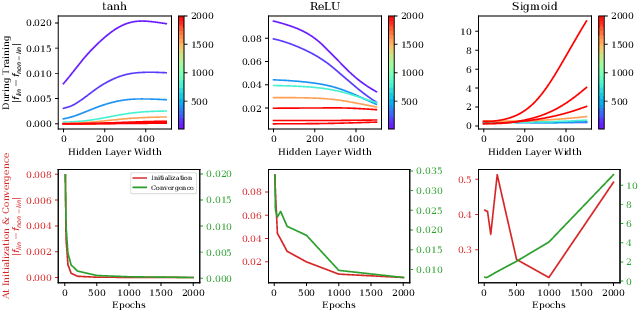
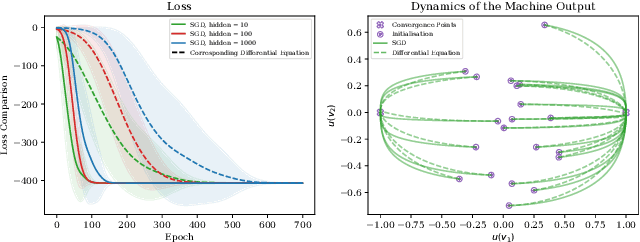
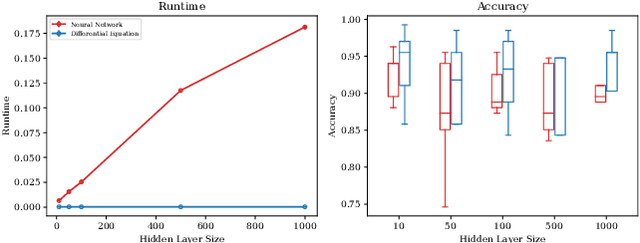
Self-Supervised Learning (SSL) is an important paradigm for learning representations from unlabelled data, and SSL with neural networks has been highly successful in practice. However current theoretical analysis of SSL is mostly restricted to generalisation error bounds. In contrast, learning dynamics often provide a precise characterisation of the behaviour of neural networks based models but, so far, are mainly known in supervised settings. In this paper, we study the learning dynamics of SSL models, specifically representations obtained by minimising contrastive and non-contrastive losses. We show that a naive extension of the dymanics of multivariate regression to SSL leads to learning trivial scalar representations that demonstrates dimension collapse in SSL. Consequently, we formulate SSL objectives with orthogonality constraints on the weights, and derive the exact (network width independent) learning dynamics of the SSL models trained using gradient descent on the Grassmannian manifold. We also argue that the infinite width approximation of SSL models significantly deviate from the neural tangent kernel approximations of supervised models. We numerically illustrate the validity of our theoretical findings, and discuss how the presented results provide a framework for further theoretical analysis of contrastive and non-contrastive SSL.
Wasserstein Projection Pursuit of Non-Gaussian Signals
Feb 24, 2023We consider the general dimensionality reduction problem of locating in a high-dimensional data cloud, a $k$-dimensional non-Gaussian subspace of interesting features. We use a projection pursuit approach -- we search for mutually orthogonal unit directions which maximise the 2-Wasserstein distance of the empirical distribution of data-projections along these directions from a standard Gaussian. Under a generative model, where there is a underlying (unknown) low-dimensional non-Gaussian subspace, we prove rigorous statistical guarantees on the accuracy of approximating this unknown subspace by the directions found by our projection pursuit approach. Our results operate in the regime where the data dimensionality is comparable to the sample size, and thus supplement the recent literature on the non-feasibility of locating interesting directions via projection pursuit in the complementary regime where the data dimensionality is much larger than the sample size.
Improved Representation Learning Through Tensorized Autoencoders
Dec 02, 2022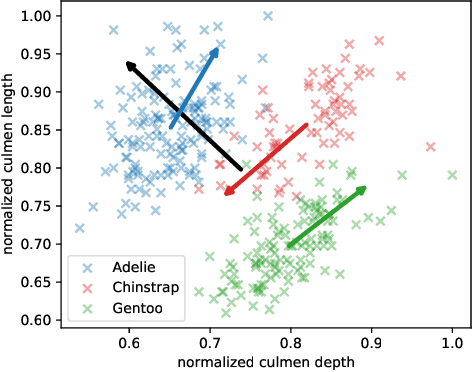
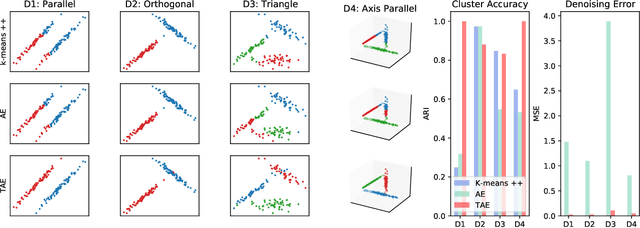
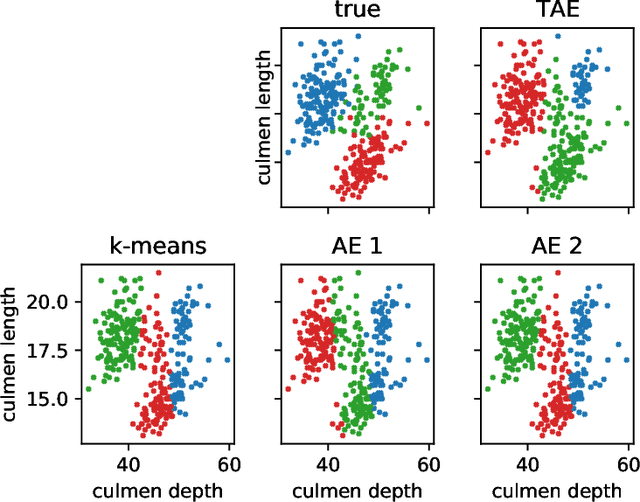
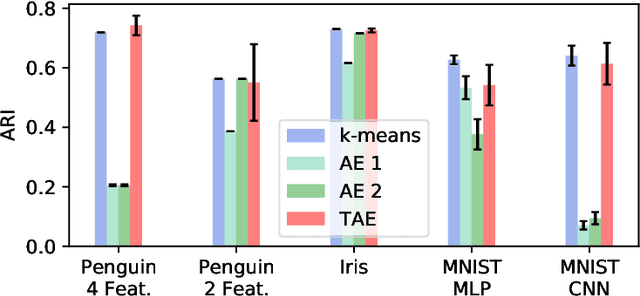
The central question in representation learning is what constitutes a good or meaningful representation. In this work we argue that if we consider data with inherent cluster structures, where clusters can be characterized through different means and covariances, those data structures should be represented in the embedding as well. While Autoencoders (AE) are widely used in practice for unsupervised representation learning, they do not fulfil the above condition on the embedding as they obtain a single representation of the data. To overcome this we propose a meta-algorithm that can be used to extend an arbitrary AE architecture to a tensorized version (TAE) that allows for learning cluster-specific embeddings while simultaneously learning the cluster assignment. For the linear setting we prove that TAE can recover the principle components of the different clusters in contrast to principle component of the entire data recovered by a standard AE. We validated this on planted models and for general, non-linear and convolutional AEs we empirically illustrate that tensorizing the AE is beneficial in clustering and de-noising tasks.