 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation with Strategic Agents via Local Disclosure
Jun 05, 2026We study off-policy evaluation (OPE) under strategic behavior where decision subjects (or agents) respond to a decision maker's policy by strategically modifying their covariates. Such behavior induces a policy-dependent covariate shift, breaking the standard assumption in existing methods that covariates are exogenous to the policy. Related work addresses this challenge by imposing strong assumptions such as repeated interactions or full knowledge of agents' response behavior, substantially limiting its applicability to OPE. In contrast, we consider a one-shot OPE setting where the decision maker has only partial knowledge of the agents' response behavior. Our key insight is that disclosing local information through post-hoc explanations reveals agents' pre-strategic covariates prior to adaptation, mitigating the information loss induced by strategic behavior. Leveraging this structure, we estimate a statistical model for the agents' responses and construct a doubly robust estimator for policy value. By assuming that the agents' cost sensitivity follows a conditional log-normal distribution, we establish consistency of the proposed estimator and validate our approach empirically. More broadly, our results highlight how interaction design can mitigate information asymmetry by revealing otherwise hidden structure in agents' strategic responses.
QuadraSHAP: Stable and Scalable Shapley Values for Product Games via Gauss-Legendre Quadrature
May 07, 2026We study the efficient computation of Shapley values for \emph{product games} -- cooperative games in which the coalition value factorizes as a product of per-player terms. Such games arise in machine learning explainability whenever the value function inherits a multiplicative structure from the underlying model, as in kernel methods with product kernels and tree-based models. Our key result is that the Shapley value of each player in a product game admits an exact one-dimensional integral representation: the weighted sum over exponentially many feature coalitions collapses to the integral of a degree-$(d-1)$ polynomial over $[0,1]$, where $d$ is the total number of features. This yields a Gauss--Legendre quadrature scheme that is \emph{provably exact} whenever the number of nodes satisfies $m_q \geq \lceil d/2 \rceil$, and otherwise provides a \emph{near-exact} approximation with error provably decaying geometrically in $m_q$. In practice, a few hundred nodes can achieve highly precise estimates even with thousands of features. Building on this formulation, we derive a numerically stable implementation via log-space evaluation, together with an efficient parallel implementation based on associative scan primitives that achieves $O(d\,m_q)$ total work and $O(\log d)$ parallel time. Experiments show that \textsc{QuadraSHAP} is the fastest numerically stable method across all tested configurations.
Quantification of Credal Uncertainty: A Distance-Based Approach
Mar 28, 2026Credal sets, i.e., closed convex sets of probability measures, provide a natural framework to represent aleatoric and epistemic uncertainty in machine learning. Yet how to quantify these two types of uncertainty for a given credal set, particularly in multiclass classification, remains underexplored. In this paper, we propose a distance-based approach to quantify total, aleatoric, and epistemic uncertainty for credal sets. Concretely, we introduce a family of such measures within the framework of Integral Probability Metrics (IPMs). The resulting quantities admit clear semantic interpretations, satisfy natural theoretical desiderata, and remain computationally tractable for common choices of IPMs. We instantiate the framework with the total variation distance and obtain simple, efficient uncertainty measures for multiclass classification. In the binary case, this choice recovers established uncertainty measures, for which a principled multiclass generalization has so far been missing. Empirical results confirm practical usefulness, with favorable performance at low computational cost.
Verbalizing LLM's Higher-order Uncertainty via Imprecise Probabilities
Mar 11, 2026Despite the growing demand for eliciting uncertainty from large language models (LLMs), empirical evidence suggests that LLM behavior is not always adequately captured by the elicitation techniques developed under the classical probabilistic uncertainty framework. This mismatch leads to systematic failure modes, particularly in settings that involve ambiguous question-answering, in-context learning, and self-reflection. To address this, we propose novel prompt-based uncertainty elicitation techniques grounded in \emph{imprecise probabilities}, a principled framework for repesenting and eliciting higher-order uncertainty. Here, first-order uncertainty captures uncertainty over possible responses to a prompt, while second-order uncertainty (uncertainty about uncertainty) quantifies indeterminacy in the underlying probability model itself. We introduce general-purpose prompting and post-processing procedures to directly elicit and quantify both orders of uncertainty, and demonstrate their effectiveness across diverse settings. Our approach enables more faithful uncertainty reporting from LLMs, improving credibility and supporting downstream decision-making.
Incentive Aware AI Regulations: A Credal Characterisation
Mar 05, 2026While high-stakes ML applications demand strict regulations, strategic ML providers often evade them to lower development costs. To address this challenge, we cast AI regulation as a mechanism design problem under uncertainty and introduce regulation mechanisms: a framework that maps empirical evidence from models to a license for some market share. The providers can select from a set of licenses, effectively forcing them to bet on their model's ability to fulfil regulation. We aim at regulation mechanisms that achieve perfect market outcome, i.e. (a) drive non-compliant providers to self-exclude, and (b) ensure participation from compliant providers. We prove that a mechanism has perfect market outcome if and only if the set of non-compliant distributions forms a credal set, i.e., a closed, convex set of probability measures. This result connects mechanism design and imprecise probability by establishing a duality between regulation mechanisms and the set of non-compliant distributions. We also demonstrate these mechanisms in practice via experiments on regulating use of spurious features for prediction and fairness. Our framework provides new insights at the intersection of mechanism design and imprecise probability, offering a foundation for development of enforceable AI regulations.
Instrumental and Proximal Causal Inference with Gaussian Processes
Mar 02, 2026Instrumental variable (IV) and proximal causal learning (Proxy) methods are central frameworks for causal inference in the presence of unobserved confounding. Despite substantial methodological advances, existing approaches rarely provide reliable epistemic uncertainty (EU) quantification. We address this gap through a Deconditional Gaussian Process (DGP) framework for uncertainty-aware causal learning. Our formulation recovers popular kernel estimators as the posterior mean, ensuring predictive precision, while the posterior variance yields principled and well-calibrated EU. Moreover, the probabilistic structure enables systematic model selection via marginal log-likelihood optimization. Empirical results demonstrate strong predictive performance alongside informative EU quantification, evaluated via empirical coverage frequencies and decision-aware accuracy rejection curves. Together, our approach provides a unified, practical solution for causal inference under unobserved confounding with reliable uncertainty.
Performative Learning Theory
Feb 04, 2026Performative predictions influence the very outcomes they aim to forecast. We study performative predictions that affect a sample (e.g., only existing users of an app) and/or the whole population (e.g., all potential app users). This raises the question of how well models generalize under performativity. For example, how well can we draw insights about new app users based on existing users when both of them react to the app's predictions? We address this question by embedding performative predictions into statistical learning theory. We prove generalization bounds under performative effects on the sample, on the population, and on both. A key intuition behind our proofs is that in the worst case, the population negates predictions, while the sample deceptively fulfills them. We cast such self-negating and self-fulfilling predictions as min-max and min-min risk functionals in Wasserstein space, respectively. Our analysis reveals a fundamental trade-off between performatively changing the world and learning from it: the more a model affects data, the less it can learn from it. Moreover, our analysis results in a surprising insight on how to improve generalization guarantees by retraining on performatively distorted samples. We illustrate our bounds in a case study on prediction-informed assignments of unemployed German residents to job trainings, drawing upon administrative labor market records from 1975 to 2017 in Germany.
Lost in Aggregation: The Causal Interpretation of the IV Estimand
Jan 17, 2026Instrumental variable based estimation of a causal effect has emerged as a standard approach to mitigate confounding bias in the social sciences and epidemiology, where conducting randomized experiments can be too costly or impossible. However, justifying the validity of the instrument often poses a significant challenge. In this work, we highlight a problem generally neglected in arguments for instrumental variable validity: the presence of an ''aggregate treatment variable'', where the treatment (e.g., education, GDP, caloric intake) is composed of finer-grained components that each may have a different effect on the outcome. We show that the causal effect of an aggregate treatment is generally ambiguous, as it depends on how interventions on the aggregate are instantiated at the component level, formalized through the aggregate-constrained component intervention distribution. We then characterize conditions on the interventional distribution and the aggregate setting under which standard instrumental variable estimators identify the aggregate effect. The contrived nature of these conditions implies major limitations on the interpretation of instrumental variable estimates based on aggregate treatments and highlights the need for a broader justificatory base for the exclusion restriction in such settings.
When Do Credal Sets Stabilize? Fixed-Point Theorems for Credal Set Updates
Oct 06, 2025Many machine learning algorithms rely on iterative updates of uncertainty representations, ranging from variational inference and expectation-maximization, to reinforcement learning, continual learning, and multi-agent learning. In the presence of imprecision and ambiguity, credal sets -- closed, convex sets of probability distributions -- have emerged as a popular framework for representing imprecise probabilistic beliefs. Under such imprecision, many learning problems in imprecise probabilistic machine learning (IPML) may be viewed as processes involving successive applications of update rules on credal sets. This naturally raises the question of whether this iterative process converges to stable fixed points -- or, more generally, under what conditions on the updating mechanism such fixed points exist, and whether they can be attained. We provide the first analysis of this problem and illustrate our findings using Credal Bayesian Deep Learning as a concrete example. Our work demonstrates that incorporating imprecision into the learning process not only enriches the representation of uncertainty, but also reveals structural conditions under which stability emerges, thereby offering new insights into the dynamics of iterative learning under imprecision.
Exact Shapley Attributions in Quadratic-time for FANOVA Gaussian Processes
Aug 20, 2025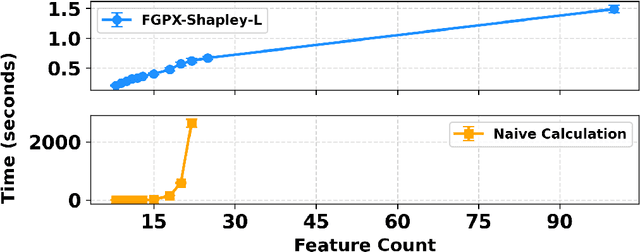



Shapley values are widely recognized as a principled method for attributing importance to input features in machine learning. However, the exact computation of Shapley values scales exponentially with the number of features, severely limiting the practical application of this powerful approach. The challenge is further compounded when the predictive model is probabilistic - as in Gaussian processes (GPs) - where the outputs are random variables rather than point estimates, necessitating additional computational effort in modeling higher-order moments. In this work, we demonstrate that for an important class of GPs known as FANOVA GP, which explicitly models all main effects and interactions, *exact* Shapley attributions for both local and global explanations can be computed in *quadratic time*. For local, instance-wise explanations, we define a stochastic cooperative game over function components and compute the exact stochastic Shapley value in quadratic time only, capturing both the expected contribution and uncertainty. For global explanations, we introduce a deterministic, variance-based value function and compute exact Shapley values that quantify each feature's contribution to the model's overall sensitivity. Our methods leverage a closed-form (stochastic) M\"{o}bius representation of the FANOVA decomposition and introduce recursive algorithms, inspired by Newton's identities, to efficiently compute the mean and variance of Shapley values. Our work enhances the utility of explainable AI, as demonstrated by empirical studies, by providing more scalable, axiomatically sound, and uncertainty-aware explanations for predictions generated by structured probabilistic models.