 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Generalised Kernel Covariance Measure
Apr 04, 2026We consider the problem of conditional independence (CI) testing and adopt a kernel-based approach. Kernel-based CI tests embed variables in reproducing kernel Hilbert spaces, regress their embeddings on the conditioning variables, and test the resulting residuals for marginal independence. This approach yields tests that are sensitive to a broad range of conditional dependencies. Existing methods, however, rely heavily on kernel ridge regression, which is computationally expensive when properly tuned and yields poorly calibrated tests when left untuned, which limits their practical usefulness. We propose the Generalised Kernel Covariance Measure (GKCM), a regression-model-agnostic kernel-based CI test that accommodates a broad class of regression estimators. Building on the Generalised Hilbertian Covariance Measure framework (Lundborg et al., 2022), we characterise conditions under which GKCM satisfies uniform asymptotic level guarantees. In simulations, GKCM paired with tree-based regression models frequently outperforms state-of-the-art CI tests across a diverse range of data-generating processes, achieving better type I error control and competitive or superior power.
Observationally Informed Adaptive Causal Experimental Design
Mar 04, 2026Randomized Controlled Trials (RCTs) represent the gold standard for causal inference yet remain a scarce resource. While large-scale observational data is often available, it is utilized only for retrospective fusion, and remains discarded in prospective trial design due to bias concerns. We argue this "tabula rasa" data acquisition strategy is fundamentally inefficient. In this work, we propose Active Residual Learning, a new paradigm that leverages the observational model as a foundational prior. This approach shifts the experimental focus from learning target causal quantities from scratch to efficiently estimating the residuals required to correct observational bias. To operationalize this, we introduce the R-Design framework. Theoretically, we establish two key advantages: (1) a structural efficiency gap, proving that estimating smooth residual contrasts admits strictly faster convergence rates than reconstructing full outcomes; and (2) information efficiency, where we quantify the redundancy in standard parameter-based acquisition (e.g., BALD), demonstrating that such baselines waste budget on task-irrelevant nuisance uncertainty. We propose R-EPIG (Residual Expected Predictive Information Gain), a unified criterion that directly targets the causal estimand, minimizing residual uncertainty for estimation or clarifying decision boundaries for policy. Experiments on synthetic and semi-synthetic benchmarks demonstrate that R-Design significantly outperforms baselines, confirming that repairing a biased model is far more efficient than learning one from scratch.
Instrumental and Proximal Causal Inference with Gaussian Processes
Mar 02, 2026Instrumental variable (IV) and proximal causal learning (Proxy) methods are central frameworks for causal inference in the presence of unobserved confounding. Despite substantial methodological advances, existing approaches rarely provide reliable epistemic uncertainty (EU) quantification. We address this gap through a Deconditional Gaussian Process (DGP) framework for uncertainty-aware causal learning. Our formulation recovers popular kernel estimators as the posterior mean, ensuring predictive precision, while the posterior variance yields principled and well-calibrated EU. Moreover, the probabilistic structure enables systematic model selection via marginal log-likelihood optimization. Empirical results demonstrate strong predictive performance alongside informative EU quantification, evaluated via empirical coverage frequencies and decision-aware accuracy rejection curves. Together, our approach provides a unified, practical solution for causal inference under unobserved confounding with reliable uncertainty.
Squared families: Searching beyond regular probability models
Mar 27, 2025
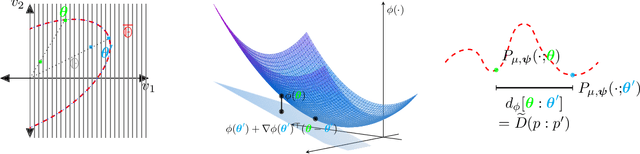
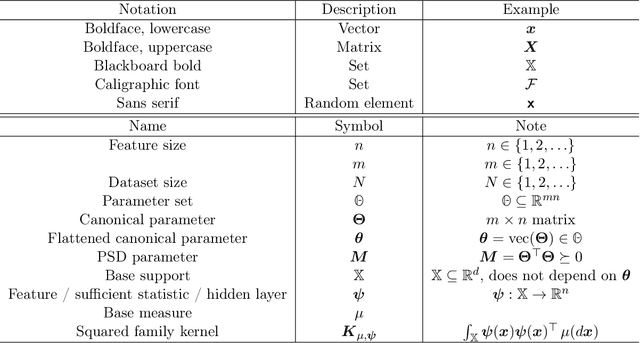
We introduce squared families, which are families of probability densities obtained by squaring a linear transformation of a statistic. Squared families are singular, however their singularity can easily be handled so that they form regular models. After handling the singularity, squared families possess many convenient properties. Their Fisher information is a conformal transformation of the Hessian metric induced from a Bregman generator. The Bregman generator is the normalising constant, and yields a statistical divergence on the family. The normalising constant admits a helpful parameter-integral factorisation, meaning that only one parameter-independent integral needs to be computed for all normalising constants in the family, unlike in exponential families. Finally, the squared family kernel is the only integral that needs to be computed for the Fisher information, statistical divergence and normalising constant. We then describe how squared families are special in the broader class of $g$-families, which are obtained by applying a sufficiently regular function $g$ to a linear transformation of a statistic. After removing special singularities, positively homogeneous families and exponential families are the only $g$-families for which the Fisher information is a conformal transformation of the Hessian metric, where the generator depends on the parameter only through the normalising constant. Even-order monomial families also admit parameter-integral factorisations, unlike exponential families. We study parameter estimation and density estimation in squared families, in the well-specified and misspecified settings. We use a universal approximation property to show that squared families can learn sufficiently well-behaved target densities at a rate of $\mathcal{O}(N^{-1/2})+C n^{-1/4}$, where $N$ is the number of datapoints, $n$ is the number of parameters, and $C$ is some constant.
Near-Optimal Approximations for Bayesian Inference in Function Space
Feb 25, 2025We propose a scalable inference algorithm for Bayes posteriors defined on a reproducing kernel Hilbert space (RKHS). Given a likelihood function and a Gaussian random element representing the prior, the corresponding Bayes posterior measure $\Pi_{\text{B}}$ can be obtained as the stationary distribution of an RKHS-valued Langevin diffusion. We approximate the infinite-dimensional Langevin diffusion via a projection onto the first $M$ components of the Kosambi-Karhunen-Lo\`eve expansion. Exploiting the thus obtained approximate posterior for these $M$ components, we perform inference for $\Pi_{\text{B}}$ by relying on the law of total probability and a sufficiency assumption. The resulting method scales as $O(M^3+JM^2)$, where $J$ is the number of samples produced from the posterior measure $\Pi_{\text{B}}$. Interestingly, the algorithm recovers the posterior arising from the sparse variational Gaussian process (SVGP) (see Titsias, 2009) as a special case, owed to the fact that the sufficiency assumption underlies both methods. However, whereas the SVGP is parametrically constrained to be a Gaussian process, our method is based on a non-parametric variational family $\mathcal{P}(\mathbb{R}^M)$ consisting of all probability measures on $\mathbb{R}^M$. As a result, our method is provably close to the optimal $M$-dimensional variational approximation of the Bayes posterior $\Pi_{\text{B}}$ in $\mathcal{P}(\mathbb{R}^M)$ for convex and Lipschitz continuous negative log likelihoods, and coincides with SVGP for the special case of a Gaussian error likelihood.
All Models Are Miscalibrated, But Some Less So: Comparing Calibration with Conditional Mean Operators
Feb 17, 2025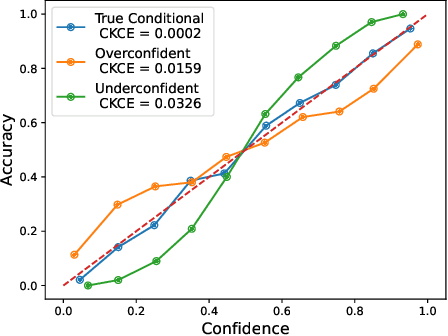
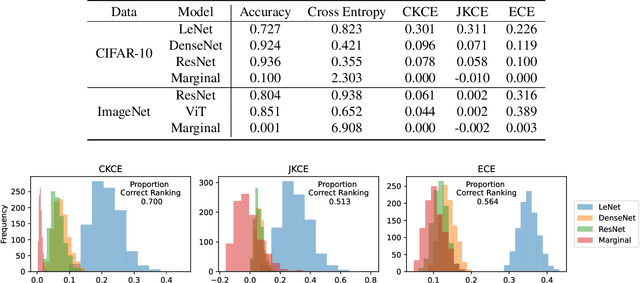
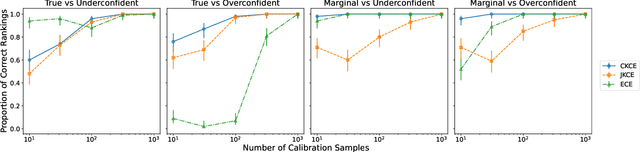
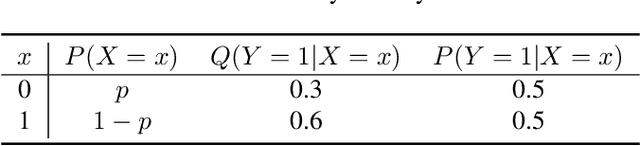
When working in a high-risk setting, having well calibrated probabilistic predictive models is a crucial requirement. However, estimators for calibration error are not always able to correctly distinguish which model is better calibrated. We propose the \emph{conditional kernel calibration error} (CKCE) which is based on the Hilbert-Schmidt norm of the difference between conditional mean operators. By working directly with the definition of strong calibration as the distance between conditional distributions, which we represent by their embeddings in reproducing kernel Hilbert spaces, the CKCE is less sensitive to the marginal distribution of predictive models. This makes it more effective for relative comparisons than previously proposed calibration metrics. Our experiments, using both synthetic and real data, show that CKCE provides a more consistent ranking of models by their calibration error and is more robust against distribution shift.
Indirect Query Bayesian Optimization with Integrated Feedback
Dec 18, 2024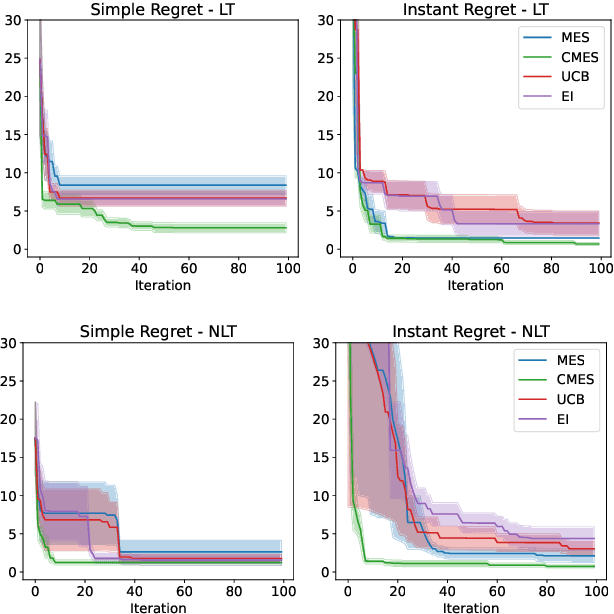
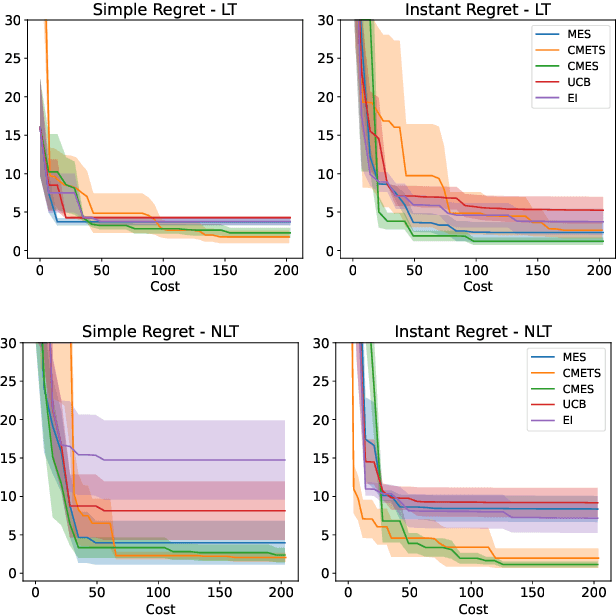
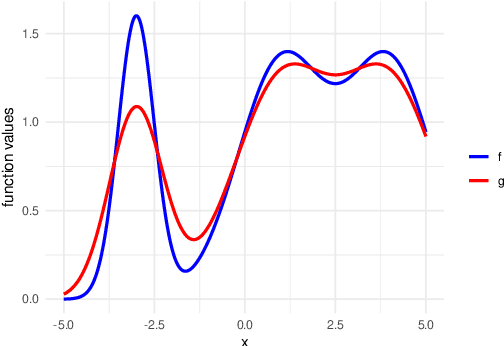
We develop the framework of Indirect Query Bayesian Optimization (IQBO), a new class of Bayesian optimization problems where the integrated feedback is given via a conditional expectation of the unknown function $f$ to be optimized. The underlying conditional distribution can be unknown and learned from data. The goal is to find the global optimum of $f$ by adaptively querying and observing in the space transformed by the conditional distribution. This is motivated by real-world applications where one cannot access direct feedback due to privacy, hardware or computational constraints. We propose the Conditional Max-Value Entropy Search (CMES) acquisition function to address this novel setting, and propose a hierarchical search algorithm to address the multi-resolution setting and improve the computational efficiency. We show regret bounds for our proposed methods and demonstrate the effectiveness of our approaches on simulated optimization tasks.
Label Distribution Learning using the Squared Neural Family on the Probability Simplex
Dec 10, 2024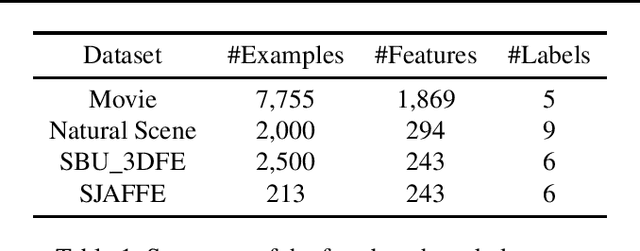
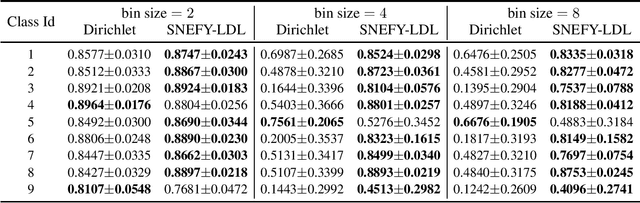
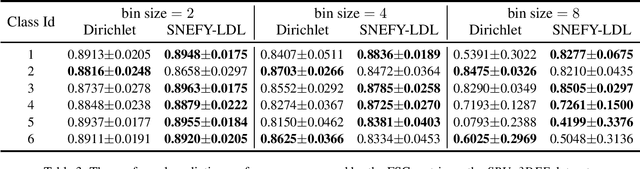
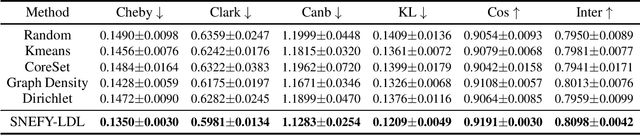
Label distribution learning (LDL) provides a framework wherein a distribution over categories rather than a single category is predicted, with the aim of addressing ambiguity in labeled data. Existing research on LDL mainly focuses on the task of point estimation, i.e., pinpointing an optimal distribution in the probability simplex conditioned on the input sample. In this paper, we estimate a probability distribution of all possible label distributions over the simplex, by unleashing the expressive power of the recently introduced Squared Neural Family (SNEFY). With the modeled distribution, label distribution prediction can be achieved by performing the expectation operation to estimate the mean of the distribution of label distributions. Moreover, more information about the label distribution can be inferred, such as the prediction reliability and uncertainties. We conduct extensive experiments on the label distribution prediction task, showing that our distribution modeling based method can achieve very competitive label distribution prediction performance compared with the state-of-the-art baselines. Additional experiments on active learning and ensemble learning demonstrate that our probabilistic approach can effectively boost the performance in these settings, by accurately estimating the prediction reliability and uncertainties.
An Overview of Causal Inference using Kernel Embeddings
Oct 30, 2024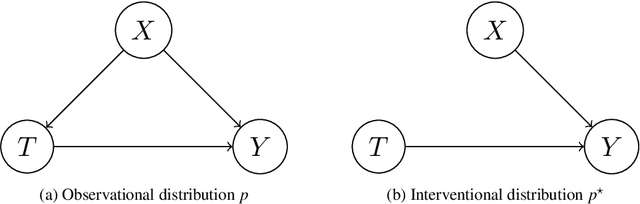
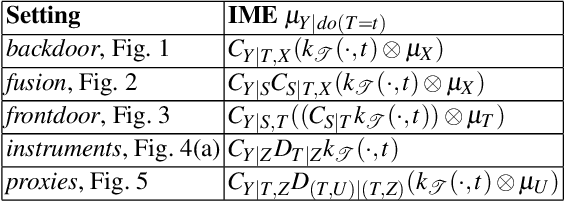
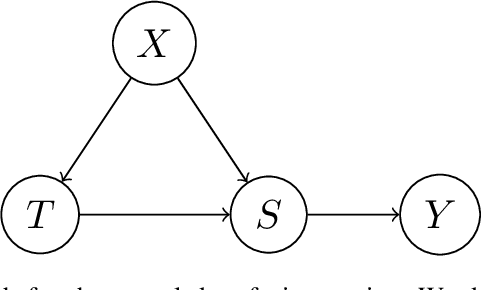
Kernel embeddings have emerged as a powerful tool for representing probability measures in a variety of statistical inference problems. By mapping probability measures into a reproducing kernel Hilbert space (RKHS), kernel embeddings enable flexible representations of complex relationships between variables. They serve as a mechanism for efficiently transferring the representation of a distribution downstream to other tasks, such as hypothesis testing or causal effect estimation. In the context of causal inference, the main challenges include identifying causal associations and estimating the average treatment effect from observational data, where confounding variables may obscure direct cause-and-effect relationships. Kernel embeddings provide a robust nonparametric framework for addressing these challenges. They allow for the representations of distributions of observational data and their seamless transformation into representations of interventional distributions to estimate relevant causal quantities. We overview recent research that leverages the expressiveness of kernel embeddings in tandem with causal inference.
Credal Two-Sample Tests of Epistemic Ignorance
Oct 16, 2024



We introduce credal two-sample testing, a new hypothesis testing framework for comparing credal sets -- convex sets of probability measures where each element captures aleatoric uncertainty and the set itself represents epistemic uncertainty that arises from the modeller's partial ignorance. Classical two-sample tests, which rely on comparing precise distributions, fail to address epistemic uncertainty due to partial ignorance. To bridge this gap, we generalise two-sample tests to compare credal sets, enabling reasoning for equality, inclusion, intersection, and mutual exclusivity, each offering unique insights into the modeller's epistemic beliefs. We formalise these tests as two-sample tests with nuisance parameters and introduce the first permutation-based solution for this class of problems, significantly improving upon existing methods. Our approach properly incorporates the modeller's epistemic uncertainty into hypothesis testing, leading to more robust and credible conclusions, with kernel-based implementations for real-world applications.