 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtDAT: A Unified Framework for Protein Sequence Design from Any Protein Text Description
Dec 05, 2024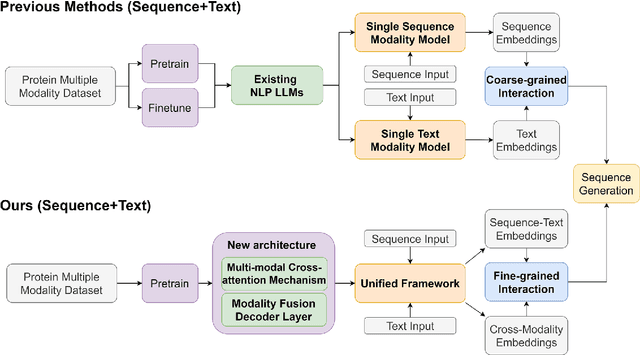
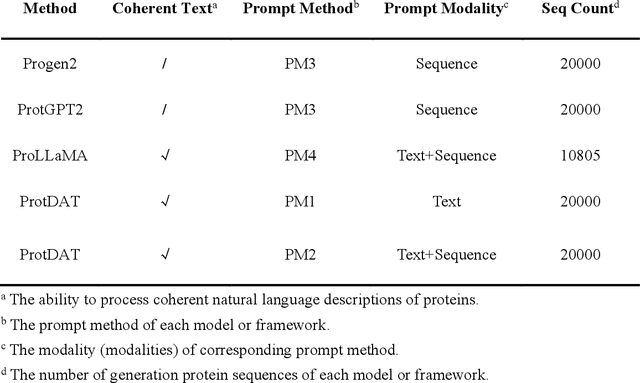
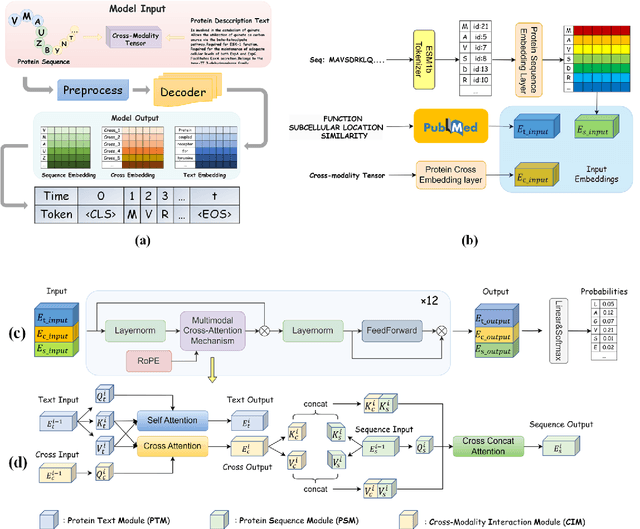
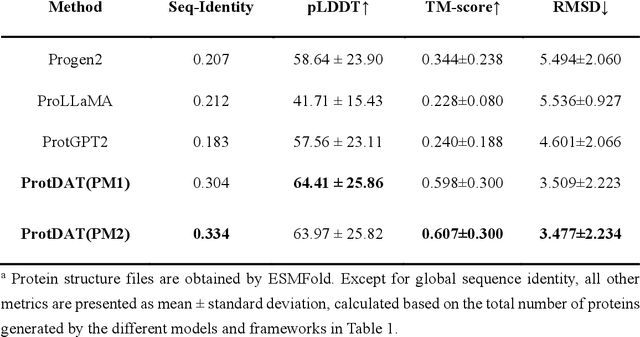
Protein design has become a critical method in advancing significant potential for various applications such as drug development and enzyme engineering. However, protein design methods utilizing large language models with solely pretraining and fine-tuning struggle to capture relationships in multi-modal protein data. To address this, we propose ProtDAT, a de novo fine-grained framework capable of designing proteins from any descriptive protein text input. ProtDAT builds upon the inherent characteristics of protein data to unify sequences and text as a cohesive whole rather than separate entities. It leverages an innovative multi-modal cross-attention, integrating protein sequences and textual information for a foundational level and seamless integration. Experimental results demonstrate that ProtDAT achieves the state-of-the-art performance in protein sequence generation, excelling in rationality, functionality, structural similarity, and validity. On 20,000 text-sequence pairs from Swiss-Prot, it improves pLDDT by 6%, TM-score by 0.26, and reduces RMSD by 1.2 {\AA}, highlighting its potential to advance protein design.
An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
Nov 09, 2024
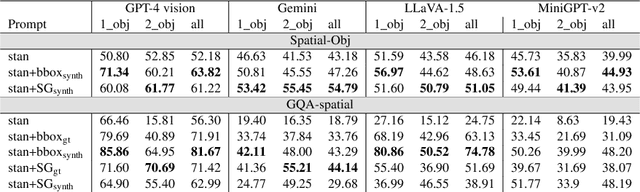

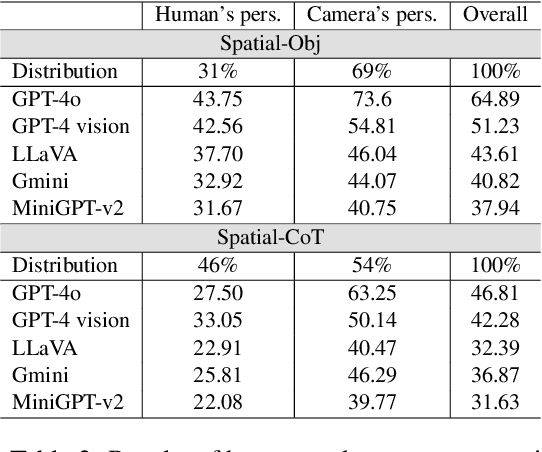
Large Multimodal Models (LMMs) have achieved strong performance across a range of vision and language tasks. However, their spatial reasoning capabilities are under-investigated. In this paper, we construct a novel VQA dataset, Spatial-MM, to comprehensively study LMMs' spatial understanding and reasoning capabilities. Our analyses on object-relationship and multi-hop reasoning reveal several important findings. Firstly, bounding boxes and scene graphs, even synthetic ones, can significantly enhance LMMs' spatial reasoning. Secondly, LMMs struggle more with questions posed from the human perspective than the camera perspective about the image. Thirdly, chain of thought (CoT) prompting does not improve model performance on complex multi-hop questions involving spatial relations. % Moreover, spatial reasoning steps are much less accurate than non-spatial ones across MLLMs. Lastly, our perturbation analysis on GQA-spatial reveals that LMMs are much stronger at basic object detection than complex spatial reasoning. We believe our benchmark dataset and in-depth analyses can spark further research on LMMs spatial reasoning. Spatial-MM benchmark is available at: https://github.com/FatemehShiri/Spatial-MM
Bayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks
Jul 30, 2024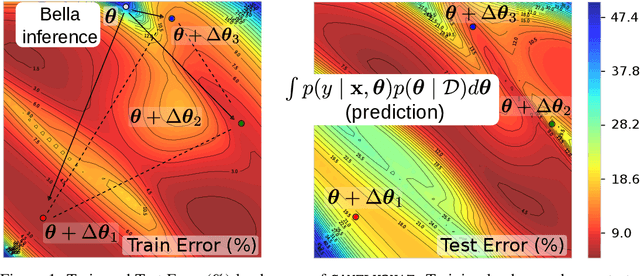

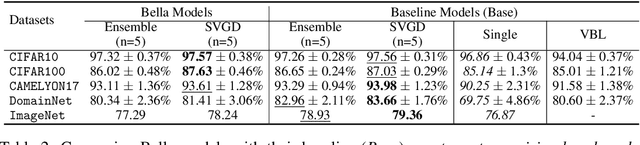

Computational complexity of Bayesian learning is impeding its adoption in practical, large-scale tasks. Despite demonstrations of significant merits such as improved robustness and resilience to unseen or out-of-distribution inputs over their non- Bayesian counterparts, their practical use has faded to near insignificance. In this study, we introduce an innovative framework to mitigate the computational burden of Bayesian neural networks (BNNs). Our approach follows the principle of Bayesian techniques based on deep ensembles, but significantly reduces their cost via multiple low-rank perturbations of parameters arising from a pre-trained neural network. Both vanilla version of ensembles as well as more sophisticated schemes such as Bayesian learning with Stein Variational Gradient Descent (SVGD), previously deemed impractical for large models, can be seamlessly implemented within the proposed framework, called Bayesian Low-Rank LeArning (Bella). In a nutshell, i) Bella achieves a dramatic reduction in the number of trainable parameters required to approximate a Bayesian posterior; and ii) it not only maintains, but in some instances, surpasses the performance of conventional Bayesian learning methods and non-Bayesian baselines. Our results with large-scale tasks such as ImageNet, CAMELYON17, DomainNet, VQA with CLIP, LLaVA demonstrate the effectiveness and versatility of Bella in building highly scalable and practical Bayesian deep models for real-world applications.
DeSIQ: Towards an Unbiased, Challenging Benchmark for Social Intelligence Understanding
Oct 24, 2023



Social intelligence is essential for understanding and reasoning about human expressions, intents and interactions. One representative benchmark for its study is Social Intelligence Queries (Social-IQ), a dataset of multiple-choice questions on videos of complex social interactions. We define a comprehensive methodology to study the soundness of Social-IQ, as the soundness of such benchmark datasets is crucial to the investigation of the underlying research problem. Our analysis reveals that Social-IQ contains substantial biases, which can be exploited by a moderately strong language model to learn spurious correlations to achieve perfect performance without being given the context or even the question. We introduce DeSIQ, a new challenging dataset, constructed by applying simple perturbations to Social-IQ. Our empirical analysis shows DeSIQ significantly reduces the biases in the original Social-IQ dataset. Furthermore, we examine and shed light on the effect of model size, model style, learning settings, commonsense knowledge, and multi-modality on the new benchmark performance. Our new dataset, observations and findings open up important research questions for the study of social intelligence.
Complex Reading Comprehension Through Question Decomposition
Nov 07, 2022
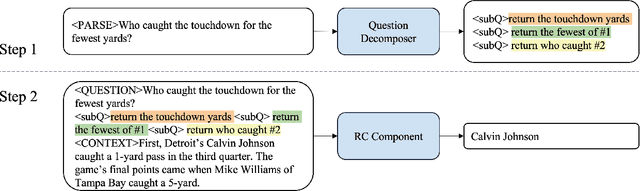
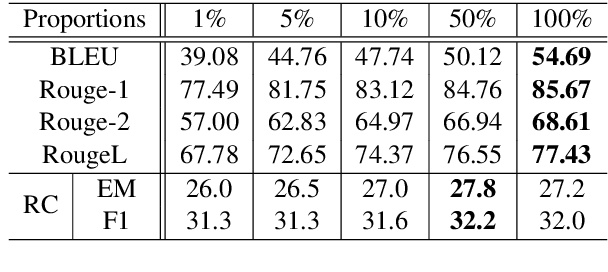
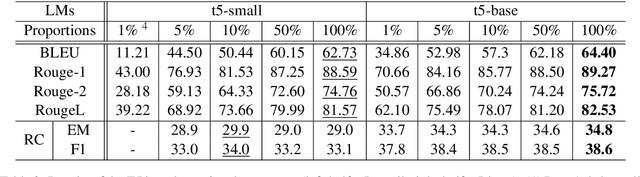
Multi-hop reading comprehension requires not only the ability to reason over raw text but also the ability to combine multiple evidence. We propose a novel learning approach that helps language models better understand difficult multi-hop questions and perform "complex, compositional" reasoning. Our model first learns to decompose each multi-hop question into several sub-questions by a trainable question decomposer. Instead of answering these sub-questions, we directly concatenate them with the original question and context, and leverage a reading comprehension model to predict the answer in a sequence-to-sequence manner. By using the same language model for these two components, our best seperate/unified t5-base variants outperform the baseline by 7.2/6.1 absolute F1 points on a hard subset of DROP dataset.
Teaching Neural Module Networks to Do Arithmetic
Oct 06, 2022
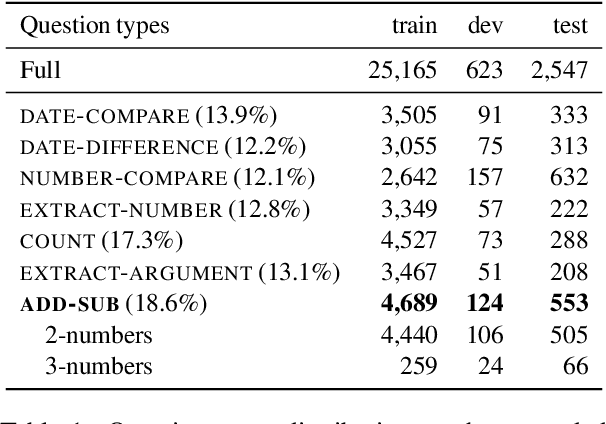


Answering complex questions that require multi-step multi-type reasoning over raw text is challenging, especially when conducting numerical reasoning. Neural Module Networks(NMNs), follow the programmer-interpreter framework and design trainable modules to learn different reasoning skills. However, NMNs only have limited reasoning abilities, and lack numerical reasoning capability. We up-grade NMNs by: (a) bridging the gap between its interpreter and the complex questions; (b) introducing addition and subtraction modules that perform numerical reasoning over numbers. On a subset of DROP, experimental results show that our proposed methods enhance NMNs' numerical reasoning skills by 17.7% improvement of F1 score and significantly outperform previous state-of-the-art models.
Improving Numerical Reasoning Skills in the Modular Approach for Complex Question Answering on Text
Sep 06, 2021
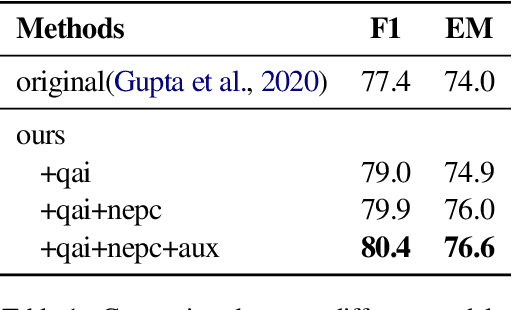
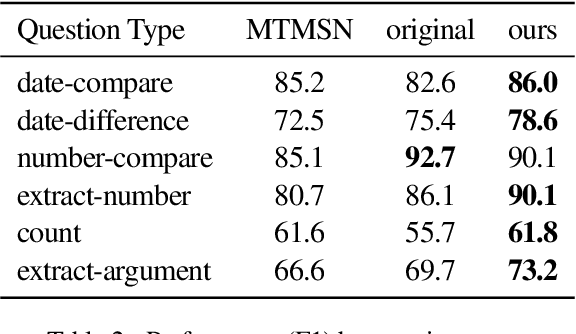

Numerical reasoning skills are essential for complex question answering (CQA) over text. It requires opertaions including counting, comparison, addition and subtraction. A successful approach to CQA on text, Neural Module Networks (NMNs), follows the programmer-interpreter paradigm and leverages specialised modules to perform compositional reasoning. However, the NMNs framework does not consider the relationship between numbers and entities in both questions and paragraphs. We propose effective techniques to improve NMNs' numerical reasoning capabilities by making the interpreter question-aware and capturing the relationship between entities and numbers. On the same subset of the DROP dataset for CQA on text, experimental results show that our additions outperform the original NMNs by 3.0 points for the overall F1 score.
Understanding Unnatural Questions Improves Reasoning over Text
Oct 19, 2020

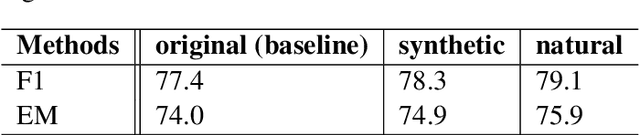
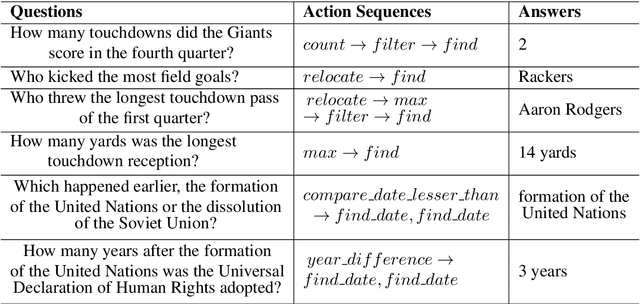
Complex question answering (CQA) over raw text is a challenging task. A prominent approach to this task is based on the programmer-interpreter framework, where the programmer maps the question into a sequence of reasoning actions which is then executed on the raw text by the interpreter. Learning an effective CQA model requires large amounts of human-annotated data,consisting of the ground-truth sequence of reasoning actions, which is time-consuming and expensive to collect at scale. In this paper, we address the challenge of learning a high-quality programmer (parser) by projecting natural human-generated questions into unnatural machine-generated questions which are more convenient to parse. We firstly generate synthetic (question,action sequence) pairs by a data generator, and train a semantic parser that associates synthetic questions with their corresponding action sequences. To capture the diversity when applied tonatural questions, we learn a projection model to map natural questions into their most similar unnatural questions for which the parser can work well. Without any natural training data, our projection model provides high-quality action sequences for the CQA task. Experimental results show that the QA model trained exclusively with synthetic data generated by our method outperforms its state-of-the-art counterpart trained on human-labeled data.