 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Network Fusion of Large Language Models for Sentiment Analysis
Oct 30, 2025Large language models (LLMs) continue to advance, with an increasing number of domain-specific variants tailored for specialised tasks. However, these models often lack transparency and explainability, can be costly to fine-tune, require substantial prompt engineering, yield inconsistent results across domains, and impose significant adverse environmental impact due to their high computational demands. To address these challenges, we propose the Bayesian network LLM fusion (BNLF) framework, which integrates predictions from three LLMs, including FinBERT, RoBERTa, and BERTweet, through a probabilistic mechanism for sentiment analysis. BNLF performs late fusion by modelling the sentiment predictions from multiple LLMs as probabilistic nodes within a Bayesian network. Evaluated across three human-annotated financial corpora with distinct linguistic and contextual characteristics, BNLF demonstrates consistent gains of about six percent in accuracy over the baseline LLMs, underscoring its robustness to dataset variability and the effectiveness of probabilistic fusion for interpretable sentiment classification.
An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
Nov 09, 2024
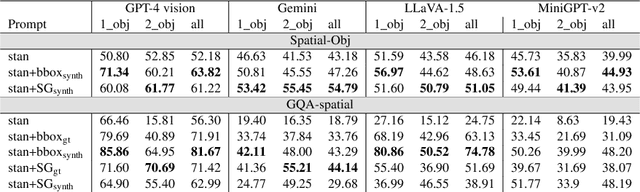

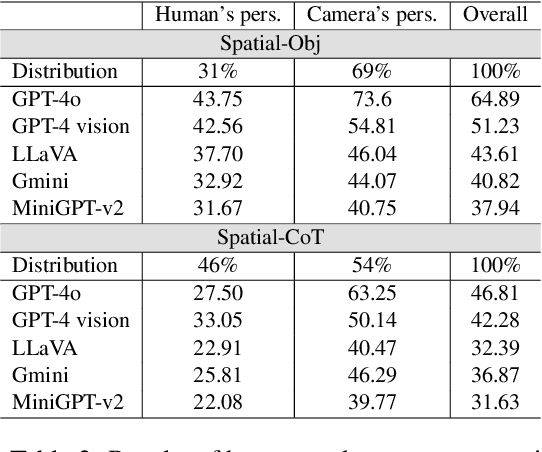
Large Multimodal Models (LMMs) have achieved strong performance across a range of vision and language tasks. However, their spatial reasoning capabilities are under-investigated. In this paper, we construct a novel VQA dataset, Spatial-MM, to comprehensively study LMMs' spatial understanding and reasoning capabilities. Our analyses on object-relationship and multi-hop reasoning reveal several important findings. Firstly, bounding boxes and scene graphs, even synthetic ones, can significantly enhance LMMs' spatial reasoning. Secondly, LMMs struggle more with questions posed from the human perspective than the camera perspective about the image. Thirdly, chain of thought (CoT) prompting does not improve model performance on complex multi-hop questions involving spatial relations. % Moreover, spatial reasoning steps are much less accurate than non-spatial ones across MLLMs. Lastly, our perturbation analysis on GQA-spatial reveals that LMMs are much stronger at basic object detection than complex spatial reasoning. We believe our benchmark dataset and in-depth analyses can spark further research on LMMs spatial reasoning. Spatial-MM benchmark is available at: https://github.com/FatemehShiri/Spatial-MM
Decompose, Enrich, and Extract! Schema-aware Event Extraction using LLMs
Jun 03, 2024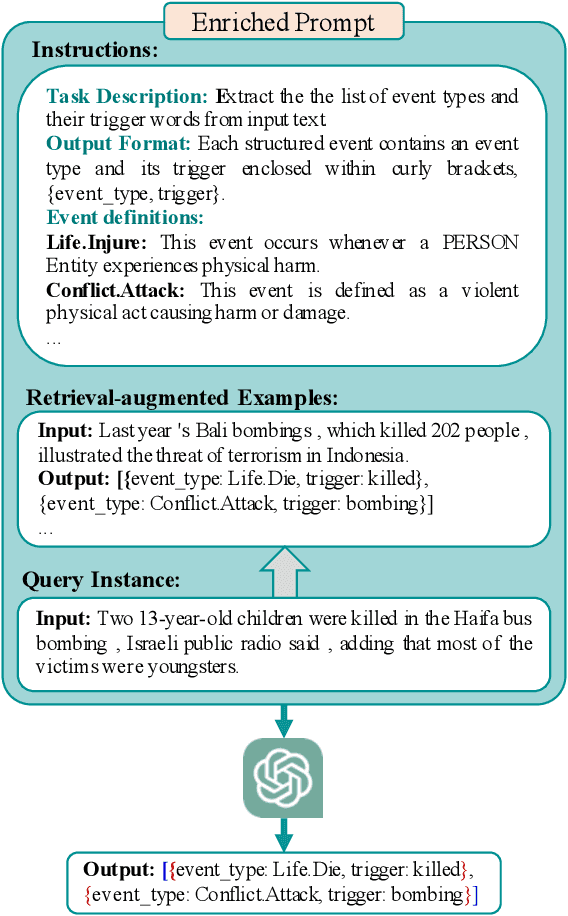
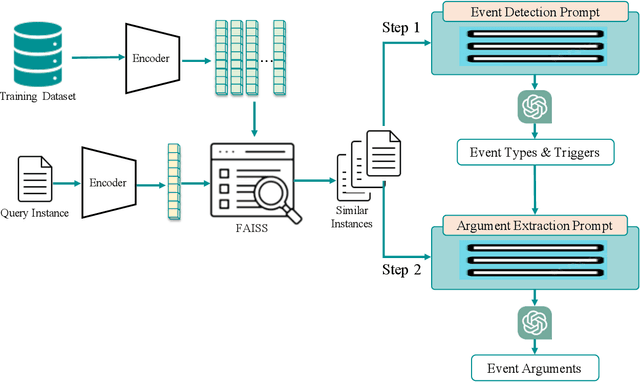


Large Language Models (LLMs) demonstrate significant capabilities in processing natural language data, promising efficient knowledge extraction from diverse textual sources to enhance situational awareness and support decision-making. However, concerns arise due to their susceptibility to hallucination, resulting in contextually inaccurate content. This work focuses on harnessing LLMs for automated Event Extraction, introducing a new method to address hallucination by decomposing the task into Event Detection and Event Argument Extraction. Moreover, the proposed method integrates dynamic schema-aware augmented retrieval examples into prompts tailored for each specific inquiry, thereby extending and adapting advanced prompting techniques such as Retrieval-Augmented Generation. Evaluation findings on prominent event extraction benchmarks and results from a synthesized benchmark illustrate the method's superior performance compared to baseline approaches.
Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs
Feb 17, 2024



Large language models (LLMs) demonstrate strong reasoning abilities when prompted to generate chain-of-thought (CoT) explanations alongside answers. However, previous research on evaluating LLMs has solely focused on answer accuracy, neglecting the correctness of the generated CoT. In this paper, we delve deeper into the CoT reasoning capabilities of LLMs in multi-hop question answering by utilizing knowledge graphs (KGs). We propose a novel discriminative and generative CoT evaluation paradigm to assess LLMs' knowledge of reasoning and the accuracy of the generated CoT. Through experiments conducted on 5 different families of LLMs across 2 multi-hop question-answering datasets, we find that LLMs possess sufficient knowledge to perform reasoning. However, there exists a significant disparity between answer accuracy and faithfulness of the CoT reasoning generated by LLMs, indicating that they often arrive at correct answers through incorrect reasoning.
Simultaneous Machine Translation with Large Language Models
Sep 13, 2023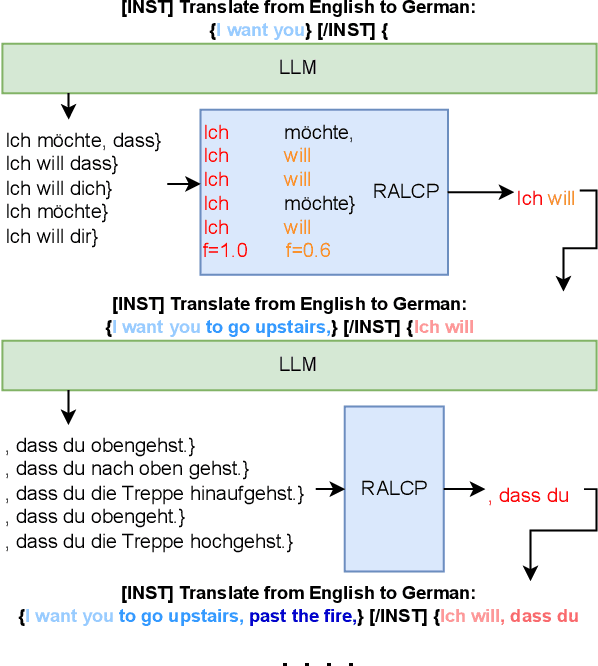


Large language models (LLM) have demonstrated their abilities to solve various natural language processing tasks through dialogue-based interactions. For instance, research indicates that LLMs can achieve competitive performance in offline machine translation tasks for high-resource languages. However, applying LLMs to simultaneous machine translation (SimulMT) poses many challenges, including issues related to the training-inference mismatch arising from different decoding patterns. In this paper, we explore the feasibility of utilizing LLMs for SimulMT. Building upon conventional approaches, we introduce a simple yet effective mixture policy that enables LLMs to engage in SimulMT without requiring additional training. Furthermore, after Supervised Fine-Tuning (SFT) on a mixture of full and prefix sentences, the model exhibits significant performance improvements. Our experiments, conducted with Llama2-7B-chat on nine language pairs from the MUST-C dataset, demonstrate that LLM can achieve translation quality and latency comparable to dedicated SimulMT models.
Language Independent Neuro-Symbolic Semantic Parsing for Form Understanding
May 08, 2023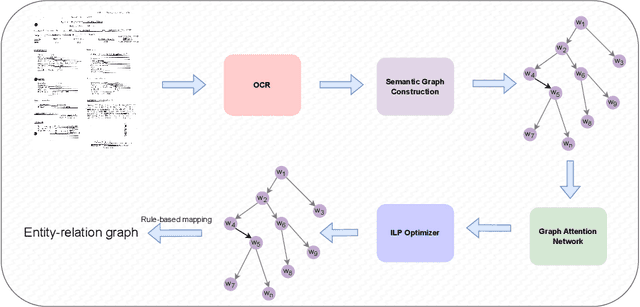
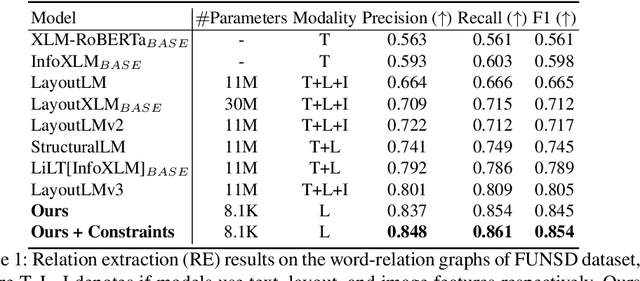
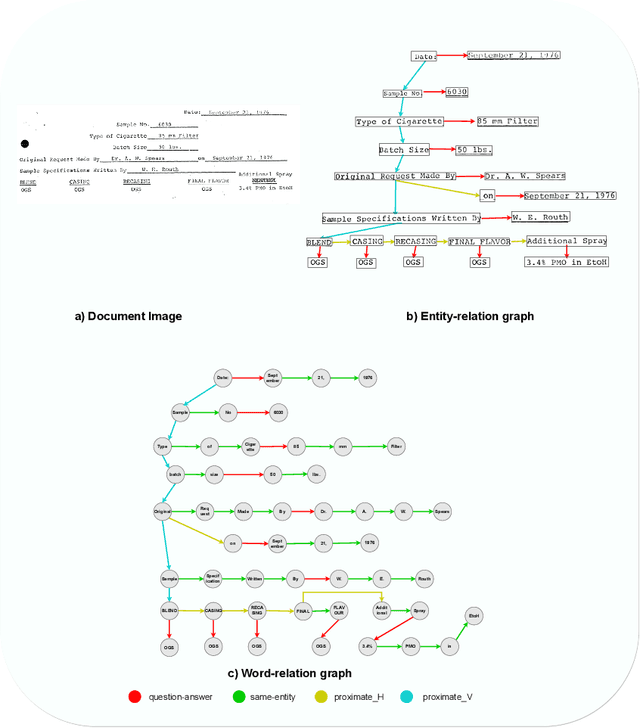
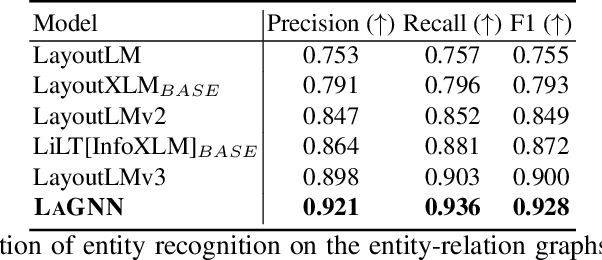
Recent works on form understanding mostly employ multimodal transformers or large-scale pre-trained language models. These models need ample data for pre-training. In contrast, humans can usually identify key-value pairings from a form only by looking at layouts, even if they don't comprehend the language used. No prior research has been conducted to investigate how helpful layout information alone is for form understanding. Hence, we propose a unique entity-relation graph parsing method for scanned forms called LAGNN, a language-independent Graph Neural Network model. Our model parses a form into a word-relation graph in order to identify entities and relations jointly and reduce the time complexity of inference. This graph is then transformed by deterministic rules into a fully connected entity-relation graph. Our model simply takes into account relative spacing between bounding boxes from layout information to facilitate easy transfer across languages. To further improve the performance of LAGNN, and achieve isomorphism between entity-relation graphs and word-relation graphs, we use integer linear programming (ILP) based inference. Code is publicly available at https://github.com/Bhanu068/LAGNN
Few-shot Domain-Adaptive Visually-fused Event Detection from Text
May 04, 2023



Incorporating auxiliary modalities such as images into event detection models has attracted increasing interest over the last few years. The complexity of natural language in describing situations has motivated researchers to leverage the related visual context to improve event detection performance. However, current approaches in this area suffer from data scarcity, where a large amount of labelled text-image pairs are required for model training. Furthermore, limited access to the visual context at inference time negatively impacts the performance of such models, which makes them practically ineffective in real-world scenarios. In this paper, we present a novel domain-adaptive visually-fused event detection approach that can be trained on a few labelled image-text paired data points. Specifically, we introduce a visual imaginator method that synthesises images from text in the absence of visual context. Moreover, the imaginator can be customised to a specific domain. In doing so, our model can leverage the capabilities of pre-trained vision-language models and can be trained in a few-shot setting. This also allows for effective inference where only single-modality data (i.e. text) is available. The experimental evaluation on the benchmark M2E2 dataset shows that our model outperforms existing state-of-the-art models, by up to 11 points.
Toward the Automated Construction of Probabilistic Knowledge Graphs for the Maritime Domain
May 04, 2023



International maritime crime is becoming increasingly sophisticated, often associated with wider criminal networks. Detecting maritime threats by means of fusing data purely related to physical movement (i.e., those generated by physical sensors, or hard data) is not sufficient. This has led to research and development efforts aimed at combining hard data with other types of data (especially human-generated or soft data). Existing work often assumes that input soft data is available in a structured format, or is focused on extracting certain relevant entities or concepts to accompany or annotate hard data. Much less attention has been given to extracting the rich knowledge about the situations of interest implicitly embedded in the large amount of soft data existing in unstructured formats (such as intelligence reports and news articles). In order to exploit the potentially useful and rich information from such sources, it is necessary to extract not only the relevant entities and concepts but also their semantic relations, together with the uncertainty associated with the extracted knowledge (i.e., in the form of probabilistic knowledge graphs). This will increase the accuracy of and confidence in, the extracted knowledge and facilitate subsequent reasoning and learning. To this end, we propose Maritime DeepDive, an initial prototype for the automated construction of probabilistic knowledge graphs from natural language data for the maritime domain. In this paper, we report on the current implementation of Maritime DeepDive, together with preliminary results on extracting probabilistic events from maritime piracy incidents. This pipeline was evaluated on a manually crafted gold standard, yielding promising results.
On Robustness of Prompt-based Semantic Parsing with Large Pre-trained Language Model: An Empirical Study on Codex
Feb 06, 2023



Semantic parsing is a technique aimed at constructing a structured representation of the meaning of a natural-language question. Recent advancements in few-shot language models trained on code have demonstrated superior performance in generating these representations compared to traditional unimodal language models, which are trained on downstream tasks. Despite these advancements, existing fine-tuned neural semantic parsers are susceptible to adversarial attacks on natural-language inputs. While it has been established that the robustness of smaller semantic parsers can be enhanced through adversarial training, this approach is not feasible for large language models in real-world scenarios, as it requires both substantial computational resources and expensive human annotation on in-domain semantic parsing data. This paper presents the first empirical study on the adversarial robustness of a large prompt-based language model of code, \codex. Our results demonstrate that the state-of-the-art (SOTA) code-language models are vulnerable to carefully crafted adversarial examples. To address this challenge, we propose methods for improving robustness without the need for significant amounts of labeled data or heavy computational resources.
Adaptive Population-based Simulated Annealing for Uncertain Resource Constrained Job Scheduling
Oct 31, 2022



Transporting ore from mines to ports is of significant interest in mining supply chains. These operations are commonly associated with growing costs and a lack of resources. Large mining companies are interested in optimally allocating their resources to reduce operational costs. This problem has been previously investigated in the literature as resource constrained job scheduling (RCJS). While a number of optimisation methods have been proposed to tackle the deterministic problem, the uncertainty associated with resource availability, an inevitable challenge in mining operations, has received less attention. RCJS with uncertainty is a hard combinatorial optimisation problem that cannot be solved efficiently with existing optimisation methods. This study proposes an adaptive population-based simulated annealing algorithm that can overcome the limitations of existing methods for RCJS with uncertainty including the premature convergence, the excessive number of hyper-parameters, and the inefficiency in coping with different uncertainty levels. This new algorithm is designed to effectively balance exploration and exploitation, by using a population, modifying the cooling schedule in the Metropolis-Hastings algorithm, and using an adaptive mechanism to select perturbation operators. The results show that the proposed algorithm outperforms existing methods across a wide range of benchmark RCJS instances and uncertainty levels. Moreover, new best known solutions are discovered for all but one problem instance across all uncertainty levels.