 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALM: Mask Augmentation based Local Matching for Food-Recipe Retrieval
May 18, 2023
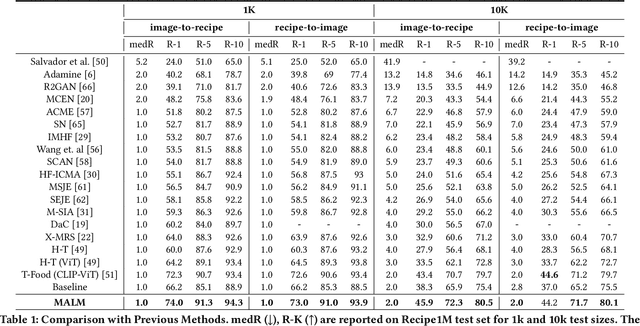
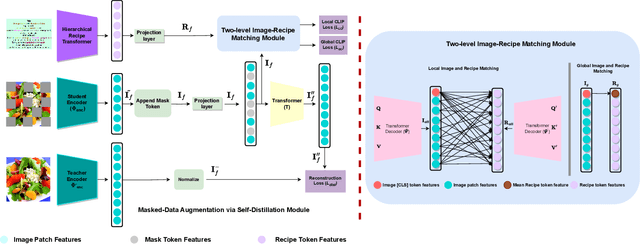

Image-to-recipe retrieval is a challenging vision-to-language task of significant practical value. The main challenge of the task lies in the ultra-high redundancy in the long recipe and the large variation reflected in both food item combination and food item appearance. A de-facto idea to address this task is to learn a shared feature embedding space in which a food image is aligned better to its paired recipe than other recipes. However, such supervised global matching is prone to supervision collapse, i.e., only partial information that is necessary for distinguishing training pairs can be identified, while other information that is potentially useful in generalization could be lost. To mitigate such a problem, we propose a mask-augmentation-based local matching network (MALM), where an image-text matching module and a masked self-distillation module benefit each other mutually to learn generalizable cross-modality representations. On one hand, we perform local matching between the tokenized representations of image and text to locate fine-grained cross-modality correspondence explicitly. We involve representations of masked image patches in this process to alleviate overfitting resulting from local matching especially when some food items are underrepresented. On the other hand, predicting the hidden representations of the masked patches through self-distillation helps to learn general-purpose image representations that are expected to generalize better. And the multi-task nature of the model enables the representations of masked patches to be text-aware and thus facilitates the lost information reconstruction. Experimental results on Recipe1M dataset show our method can clearly outperform state-of-the-art (SOTA) methods. Our code will be available at https://github.com/MyFoodChoice/MALM_Mask_Augmentation_based_Local_Matching-_for-_Food_Recipe_Retrieval
Automatic Radiology Report Generation by Learning with Increasingly Hard Negatives
May 11, 2023Automatic radiology report generation is challenging as medical images or reports are usually similar to each other due to the common content of anatomy. This makes a model hard to capture the uniqueness of individual images and is prone to producing undesired generic or mismatched reports. This situation calls for learning more discriminative features that could capture even fine-grained mismatches between images and reports. To achieve this, this paper proposes a novel framework to learn discriminative image and report features by distinguishing them from their closest peers, i.e., hard negatives. Especially, to attain more discriminative features, we gradually raise the difficulty of such a learning task by creating increasingly hard negative reports for each image in the feature space during training, respectively. By treating the increasingly hard negatives as auxiliary variables, we formulate this process as a min-max alternating optimisation problem. At each iteration, conditioned on a given set of hard negative reports, image and report features are learned as usual by minimising the loss functions related to report generation. After that, a new set of harder negative reports will be created by maximising a loss reflecting image-report alignment. By solving this optimisation, we attain a model that can generate more specific and accurate reports. It is noteworthy that our framework enhances discriminative feature learning without introducing extra network weights. Also, in contrast to the existing way of generating hard negatives, our framework extends beyond the granularity of the dataset by generating harder samples out of the training set. Experimental study on benchmark datasets verifies the efficacy of our framework and shows that it can serve as a plug-in to readily improve existing medical report generation models.
Language Independent Neuro-Symbolic Semantic Parsing for Form Understanding
May 08, 2023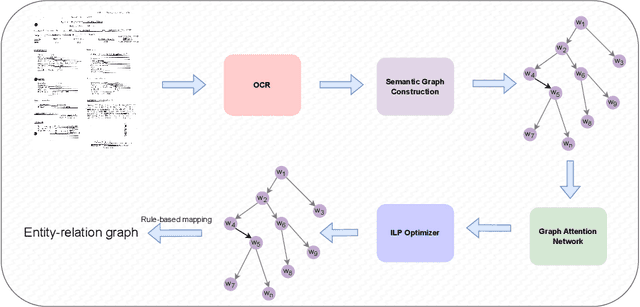
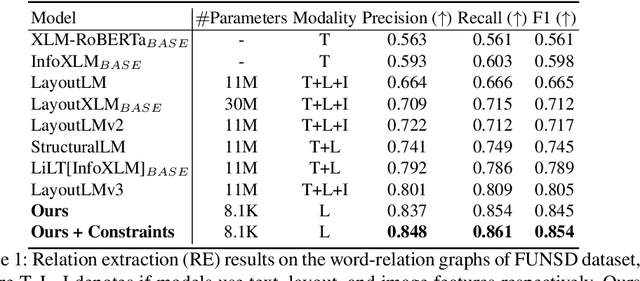
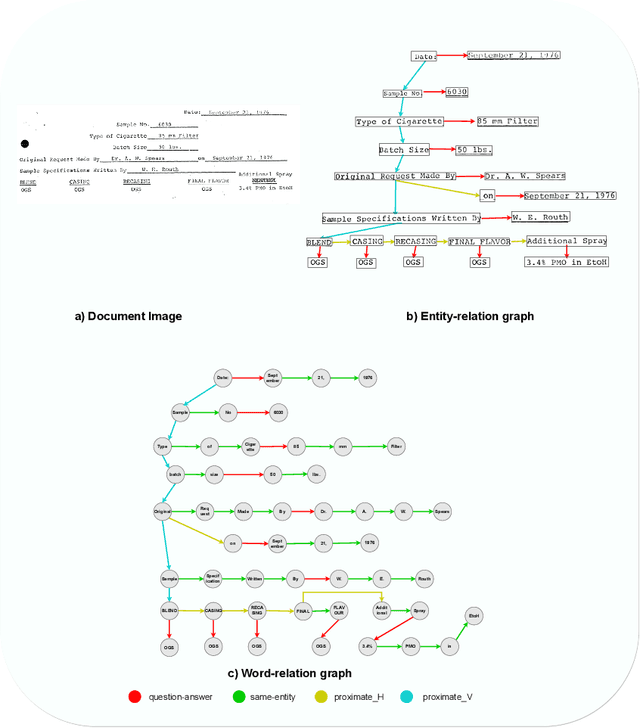
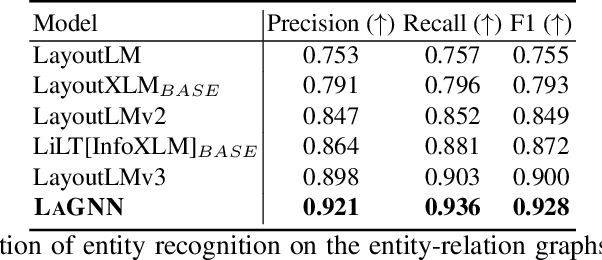
Recent works on form understanding mostly employ multimodal transformers or large-scale pre-trained language models. These models need ample data for pre-training. In contrast, humans can usually identify key-value pairings from a form only by looking at layouts, even if they don't comprehend the language used. No prior research has been conducted to investigate how helpful layout information alone is for form understanding. Hence, we propose a unique entity-relation graph parsing method for scanned forms called LAGNN, a language-independent Graph Neural Network model. Our model parses a form into a word-relation graph in order to identify entities and relations jointly and reduce the time complexity of inference. This graph is then transformed by deterministic rules into a fully connected entity-relation graph. Our model simply takes into account relative spacing between bounding boxes from layout information to facilitate easy transfer across languages. To further improve the performance of LAGNN, and achieve isomorphism between entity-relation graphs and word-relation graphs, we use integer linear programming (ILP) based inference. Code is publicly available at https://github.com/Bhanu068/LAGNN
Leveraging Language Foundation Models for Human Mobility Forecasting
Sep 14, 2022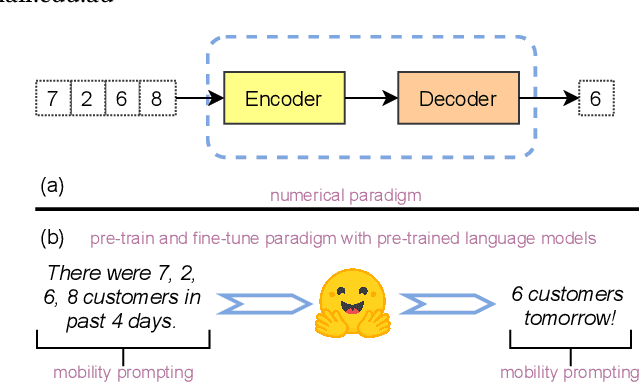

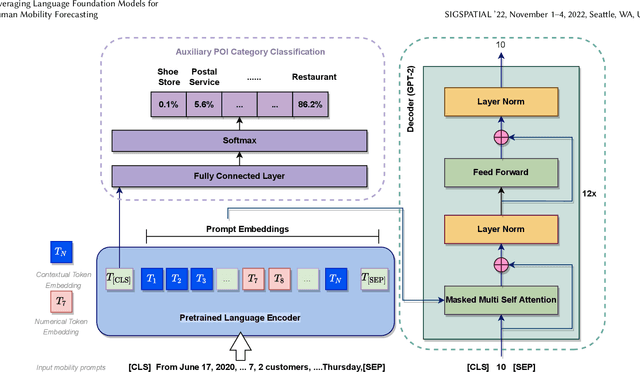

In this paper, we propose a novel pipeline that leverages language foundation models for temporal sequential pattern mining, such as for human mobility forecasting tasks. For example, in the task of predicting Place-of-Interest (POI) customer flows, typically the number of visits is extracted from historical logs, and only the numerical data are used to predict visitor flows. In this research, we perform the forecasting task directly on the natural language input that includes all kinds of information such as numerical values and contextual semantic information. Specific prompts are introduced to transform numerical temporal sequences into sentences so that existing language models can be directly applied. We design an AuxMobLCast pipeline for predicting the number of visitors in each POI, integrating an auxiliary POI category classification task with the encoder-decoder architecture. This research provides empirical evidence of the effectiveness of the proposed AuxMobLCast pipeline to discover sequential patterns in mobility forecasting tasks. The results, evaluated on three real-world datasets, demonstrate that pre-trained language foundation models also have good performance in forecasting temporal sequences. This study could provide visionary insights and lead to new research directions for predicting human mobility.