 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Text-Guided Brain Tumor Segmentation via Sub-Region-Aware Prompts
Mar 22, 2026Brain tumor segmentation remains challenging because the three standard sub-regions, i.e., whole tumor (WT), tumor core (TC), and enhancing tumor (ET), often exhibit ambiguous visual boundaries. Integrating radiological description texts with imaging has shown promise. However, most multimodal approaches typically compress a report into a single global text embedding shared across all sub-regions, overlooking their distinct clinical characteristics. We propose TextCSP (text-modulated soft cascade architecture), a hierarchical text-guided framework that builds on the TextBraTS baseline with three novel components: (1) a text-modulated soft cascade decoder that predicts WT->TC->ET in a coarse-to-fine manner consistent with their anatomical containment hierarchy. (2) sub-region-aware prompt tuning, which uses learnable soft prompts with a LoRA-adapted BioBERT encoder to generate specialized text representations tailored for each sub-region; (3) text-semantic channel modulators that convert the aforementioned representations into channel-wise refinement signals, enabling the decoder to emphasize features aligned with clinically described patterns. Experiments on the TextBraTS dataset demonstrate consistent improvements across all sub-regions against state-of-the-art methods by 1.7% and 6% on the main metrics Dice and HD95.
EndoIR: Degradation-Agnostic All-in-One Endoscopic Image Restoration via Noise-Aware Routing Diffusion
Nov 11, 2025Endoscopic images often suffer from diverse and co-occurring degradations such as low lighting, smoke, and bleeding, which obscure critical clinical details. Existing restoration methods are typically task-specific and often require prior knowledge of the degradation type, limiting their robustness in real-world clinical use. We propose EndoIR, an all-in-one, degradation-agnostic diffusion-based framework that restores multiple degradation types using a single model. EndoIR introduces a Dual-Domain Prompter that extracts joint spatial-frequency features, coupled with an adaptive embedding that encodes both shared and task-specific cues as conditioning for denoising. To mitigate feature confusion in conventional concatenation-based conditioning, we design a Dual-Stream Diffusion architecture that processes clean and degraded inputs separately, with a Rectified Fusion Block integrating them in a structured, degradation-aware manner. Furthermore, Noise-Aware Routing Block improves efficiency by dynamically selecting only noise-relevant features during denoising. Experiments on SegSTRONG-C and CEC datasets demonstrate that EndoIR achieves state-of-the-art performance across multiple degradation scenarios while using fewer parameters than strong baselines, and downstream segmentation experiments confirm its clinical utility.
Medical Referring Image Segmentation via Next-Token Mask Prediction
Nov 07, 2025Medical Referring Image Segmentation (MRIS) involves segmenting target regions in medical images based on natural language descriptions. While achieving promising results, recent approaches usually involve complex design of multimodal fusion or multi-stage decoders. In this work, we propose NTP-MRISeg, a novel framework that reformulates MRIS as an autoregressive next-token prediction task over a unified multimodal sequence of tokenized image, text, and mask representations. This formulation streamlines model design by eliminating the need for modality-specific fusion and external segmentation models, supports a unified architecture for end-to-end training. It also enables the use of pretrained tokenizers from emerging large-scale multimodal models, enhancing generalization and adaptability. More importantly, to address challenges under this formulation-such as exposure bias, long-tail token distributions, and fine-grained lesion edges-we propose three novel strategies: (1) a Next-k Token Prediction (NkTP) scheme to reduce cumulative prediction errors, (2) Token-level Contrastive Learning (TCL) to enhance boundary sensitivity and mitigate long-tail distribution effects, and (3) a memory-based Hard Error Token (HET) optimization strategy that emphasizes difficult tokens during training. Extensive experiments on the QaTa-COV19 and MosMedData+ datasets demonstrate that NTP-MRISeg achieves new state-of-the-art performance, offering a streamlined and effective alternative to traditional MRIS pipelines.
A Review of Longitudinal Radiology Report Generation: Dataset Composition, Methods, and Performance Evaluation
Oct 14, 2025Chest Xray imaging is a widely used diagnostic tool in modern medicine, and its high utilization creates substantial workloads for radiologists. To alleviate this burden, vision language models are increasingly applied to automate Chest Xray radiology report generation (CXRRRG), aiming for clinically accurate descriptions while reducing manual effort. Conventional approaches, however, typically rely on single images, failing to capture the longitudinal context necessary for producing clinically faithful comparison statements. Recently, growing attention has been directed toward incorporating longitudinal data into CXR RRG, enabling models to leverage historical studies in ways that mirror radiologists diagnostic workflows. Nevertheless, existing surveys primarily address single image CXRRRG and offer limited guidance for longitudinal settings, leaving researchers without a systematic framework for model design. To address this gap, this survey provides the first comprehensive review of longitudinal radiology report generation (LRRG). Specifically, we examine dataset construction strategies, report generation architectures alongside longitudinally tailored designs, and evaluation protocols encompassing both longitudinal specific measures and widely used benchmarks. We further summarize LRRG methods performance, alongside analyses of different ablation studies, which collectively highlight the critical role of longitudinal information and architectural design choices in improving model performance. Finally, we summarize five major limitations of current research and outline promising directions for future development, aiming to lay a foundation for advancing this emerging field.
Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Sep 18, 2025



Recent studies have demonstrated the importance of high-quality visual representations in image generation and have highlighted the limitations of generative models in image understanding. As a generative paradigm originally designed for natural language, autoregressive models face similar challenges. In this work, we present the first systematic investigation into the mechanisms of applying the next-token prediction paradigm to the visual domain. We identify three key properties that hinder the learning of high-level visual semantics: local and conditional dependence, inter-step semantic inconsistency, and spatial invariance deficiency. We show that these issues can be effectively addressed by introducing self-supervised objectives during training, leading to a novel training framework, Self-guided Training for AutoRegressive models (ST-AR). Without relying on pre-trained representation models, ST-AR significantly enhances the image understanding ability of autoregressive models and leads to improved generation quality. Specifically, ST-AR brings approximately 42% FID improvement for LlamaGen-L and 49% FID improvement for LlamaGen-XL, while maintaining the same sampling strategy.
Dense Video Captioning using Graph-based Sentence Summarization
Jun 25, 2025Recently, dense video captioning has made attractive progress in detecting and captioning all events in a long untrimmed video. Despite promising results were achieved, most existing methods do not sufficiently explore the scene evolution within an event temporal proposal for captioning, and therefore perform less satisfactorily when the scenes and objects change over a relatively long proposal. To address this problem, we propose a graph-based partition-and-summarization (GPaS) framework for dense video captioning within two stages. For the ``partition" stage, a whole event proposal is split into short video segments for captioning at a finer level. For the ``summarization" stage, the generated sentences carrying rich description information for each segment are summarized into one sentence to describe the whole event. We particularly focus on the ``summarization" stage, and propose a framework that effectively exploits the relationship between semantic words for summarization. We achieve this goal by treating semantic words as nodes in a graph and learning their interactions by coupling Graph Convolutional Network (GCN) and Long Short Term Memory (LSTM), with the aid of visual cues. Two schemes of GCN-LSTM Interaction (GLI) modules are proposed for seamless integration of GCN and LSTM. The effectiveness of our approach is demonstrated via an extensive comparison with the state-of-the-arts methods on the two benchmarks ActivityNet Captions dataset and YouCook II dataset.
Mamba-Sea: A Mamba-based Framework with Global-to-Local Sequence Augmentation for Generalizable Medical Image Segmentation
Apr 24, 2025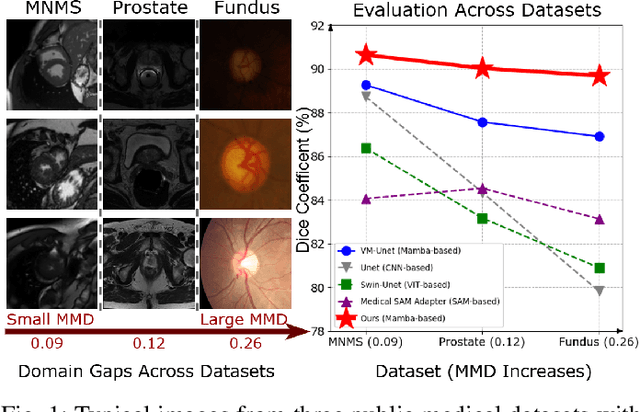
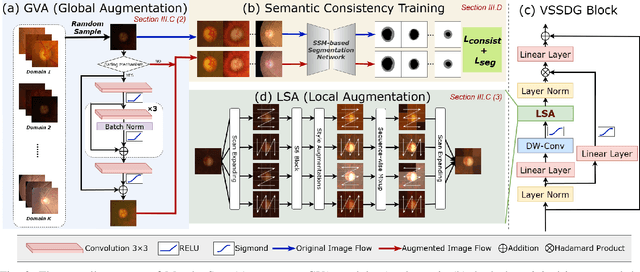

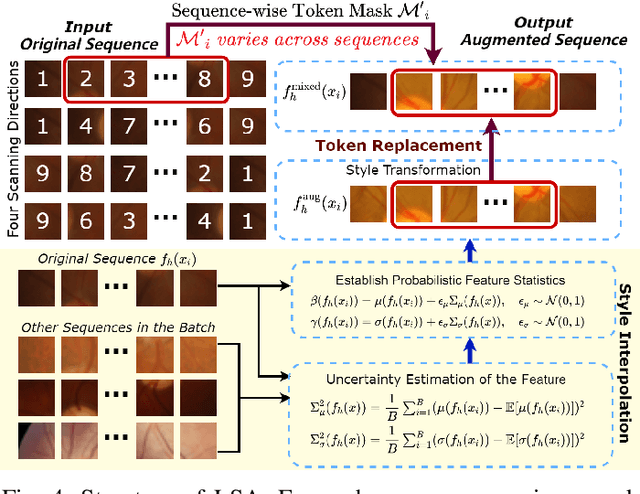
To segment medical images with distribution shifts, domain generalization (DG) has emerged as a promising setting to train models on source domains that can generalize to unseen target domains. Existing DG methods are mainly based on CNN or ViT architectures. Recently, advanced state space models, represented by Mamba, have shown promising results in various supervised medical image segmentation. The success of Mamba is primarily owing to its ability to capture long-range dependencies while keeping linear complexity with input sequence length, making it a promising alternative to CNNs and ViTs. Inspired by the success, in the paper, we explore the potential of the Mamba architecture to address distribution shifts in DG for medical image segmentation. Specifically, we propose a novel Mamba-based framework, Mamba-Sea, incorporating global-to-local sequence augmentation to improve the model's generalizability under domain shift issues. Our Mamba-Sea introduces a global augmentation mechanism designed to simulate potential variations in appearance across different sites, aiming to suppress the model's learning of domain-specific information. At the local level, we propose a sequence-wise augmentation along input sequences, which perturbs the style of tokens within random continuous sub-sequences by modeling and resampling style statistics associated with domain shifts. To our best knowledge, Mamba-Sea is the first work to explore the generalization of Mamba for medical image segmentation, providing an advanced and promising Mamba-based architecture with strong robustness to domain shifts. Remarkably, our proposed method is the first to surpass a Dice coefficient of 90% on the Prostate dataset, which exceeds previous SOTA of 88.61%. The code is available at https://github.com/orange-czh/Mamba-Sea.
DiN: Diffusion Model for Robust Medical VQA with Semantic Noisy Labels
Mar 24, 2025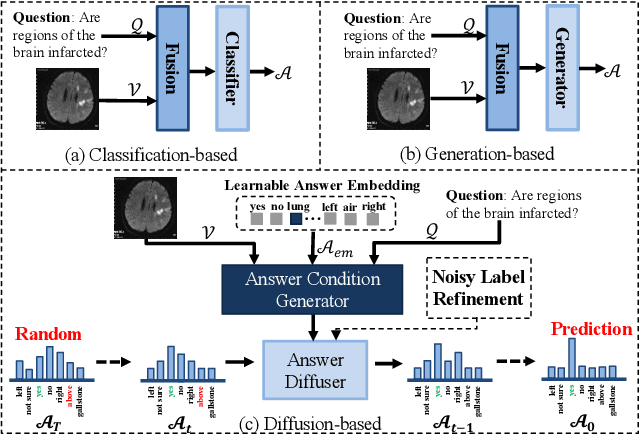
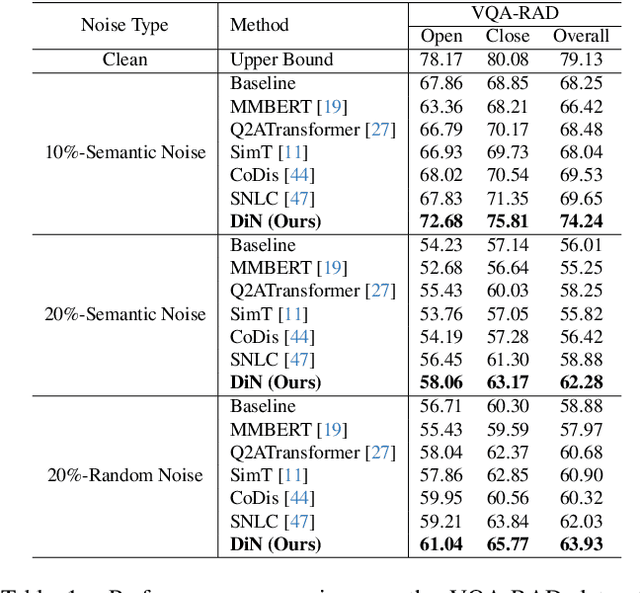
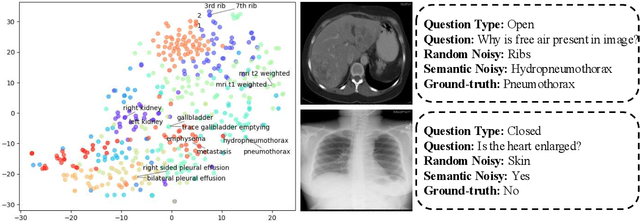
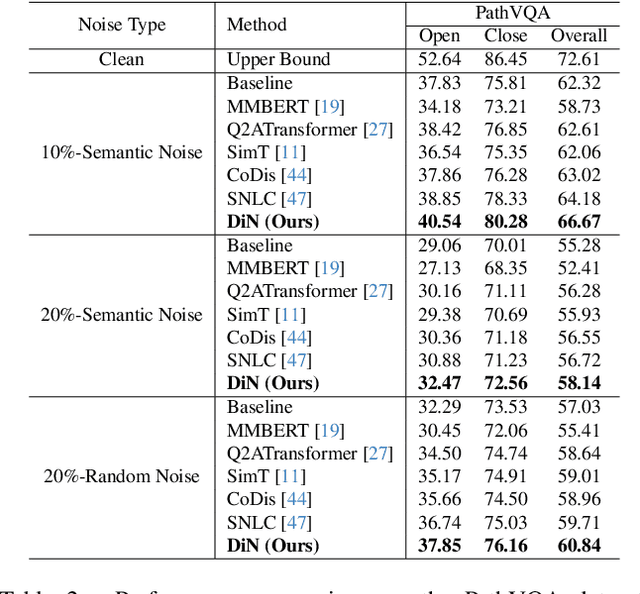
Medical Visual Question Answering (Med-VQA) systems benefit the interpretation of medical images containing critical clinical information. However, the challenge of noisy labels and limited high-quality datasets remains underexplored. To address this, we establish the first benchmark for noisy labels in Med-VQA by simulating human mislabeling with semantically designed noise types. More importantly, we introduce the DiN framework, which leverages a diffusion model to handle noisy labels in Med-VQA. Unlike the dominant classification-based VQA approaches that directly predict answers, our Answer Diffuser (AD) module employs a coarse-to-fine process, refining answer candidates with a diffusion model for improved accuracy. The Answer Condition Generator (ACG) further enhances this process by generating task-specific conditional information via integrating answer embeddings with fused image-question features. To address label noise, our Noisy Label Refinement(NLR) module introduces a robust loss function and dynamic answer adjustment to further boost the performance of the AD module.
Imbalanced Medical Image Segmentation with Pixel-dependent Noisy Labels
Jan 12, 2025



Accurate medical image segmentation is often hindered by noisy labels in training data, due to the challenges of annotating medical images. Prior research works addressing noisy labels tend to make class-dependent assumptions, overlooking the pixel-dependent nature of most noisy labels. Furthermore, existing methods typically apply fixed thresholds to filter out noisy labels, risking the removal of minority classes and consequently degrading segmentation performance. To bridge these gaps, our proposed framework, Collaborative Learning with Curriculum Selection (CLCS), addresses pixel-dependent noisy labels with class imbalance. CLCS advances the existing works by i) treating noisy labels as pixel-dependent and addressing them through a collaborative learning framework, and ii) employing a curriculum dynamic thresholding approach adapting to model learning progress to select clean data samples to mitigate the class imbalance issue, and iii) applying a noise balance loss to noisy data samples to improve data utilization instead of discarding them outright. Specifically, our CLCS contains two modules: Curriculum Noisy Label Sample Selection (CNS) and Noise Balance Loss (NBL). In the CNS module, we designed a two-branch network with discrepancy loss for collaborative learning so that different feature representations of the same instance could be extracted from distinct views and used to vote the class probabilities of pixels. Besides, a curriculum dynamic threshold is adopted to select clean-label samples through probability voting. In the NBL module, instead of directly dropping the suspiciously noisy labels, we further adopt a robust loss to leverage such instances to boost the performance.
UniBrain: A Unified Model for Cross-Subject Brain Decoding
Dec 27, 2024



Brain decoding aims to reconstruct original stimuli from fMRI signals, providing insights into interpreting mental content. Current approaches rely heavily on subject-specific models due to the complex brain processing mechanisms and the variations in fMRI signals across individuals. Therefore, these methods greatly limit the generalization of models and fail to capture cross-subject commonalities. To address this, we present UniBrain, a unified brain decoding model that requires no subject-specific parameters. Our approach includes a group-based extractor to handle variable fMRI signal lengths, a mutual assistance embedder to capture cross-subject commonalities, and a bilevel feature alignment scheme for extracting subject-invariant features. We validate our UniBrain on the brain decoding benchmark, achieving comparable performance to current state-of-the-art subject-specific models with extremely fewer parameters. We also propose a generalization benchmark to encourage the community to emphasize cross-subject commonalities for more general brain decoding. Our code is available at https://github.com/xiaoyao3302/UniBrain.