 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Sep 18, 2025



Recent studies have demonstrated the importance of high-quality visual representations in image generation and have highlighted the limitations of generative models in image understanding. As a generative paradigm originally designed for natural language, autoregressive models face similar challenges. In this work, we present the first systematic investigation into the mechanisms of applying the next-token prediction paradigm to the visual domain. We identify three key properties that hinder the learning of high-level visual semantics: local and conditional dependence, inter-step semantic inconsistency, and spatial invariance deficiency. We show that these issues can be effectively addressed by introducing self-supervised objectives during training, leading to a novel training framework, Self-guided Training for AutoRegressive models (ST-AR). Without relying on pre-trained representation models, ST-AR significantly enhances the image understanding ability of autoregressive models and leads to improved generation quality. Specifically, ST-AR brings approximately 42% FID improvement for LlamaGen-L and 49% FID improvement for LlamaGen-XL, while maintaining the same sampling strategy.
Transition Models: Rethinking the Generative Learning Objective
Sep 04, 2025

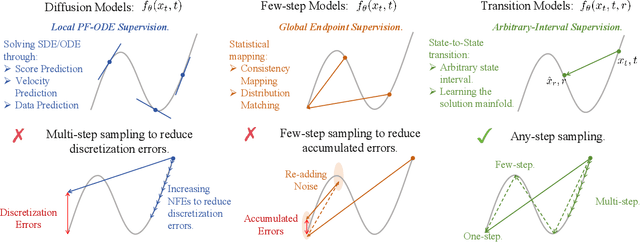

A fundamental dilemma in generative modeling persists: iterative diffusion models achieve outstanding fidelity, but at a significant computational cost, while efficient few-step alternatives are constrained by a hard quality ceiling. This conflict between generation steps and output quality arises from restrictive training objectives that focus exclusively on either infinitesimal dynamics (PF-ODEs) or direct endpoint prediction. We address this challenge by introducing an exact, continuous-time dynamics equation that analytically defines state transitions across any finite time interval. This leads to a novel generative paradigm, Transition Models (TiM), which adapt to arbitrary-step transitions, seamlessly traversing the generative trajectory from single leaps to fine-grained refinement with more steps. Despite having only 865M parameters, TiM achieves state-of-the-art performance, surpassing leading models such as SD3.5 (8B parameters) and FLUX.1 (12B parameters) across all evaluated step counts. Importantly, unlike previous few-step generators, TiM demonstrates monotonic quality improvement as the sampling budget increases. Additionally, when employing our native-resolution strategy, TiM delivers exceptional fidelity at resolutions up to 4096x4096.
RadarQA: Multi-modal Quality Analysis of Weather Radar Forecasts
Aug 17, 2025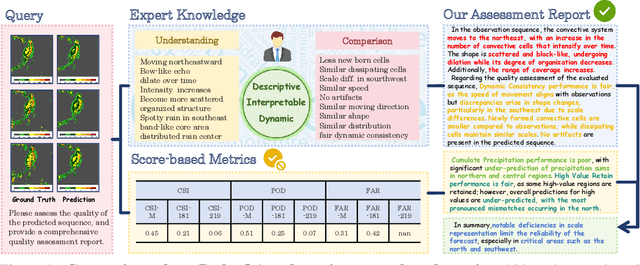
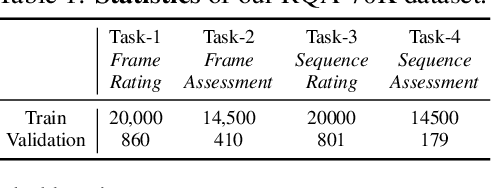

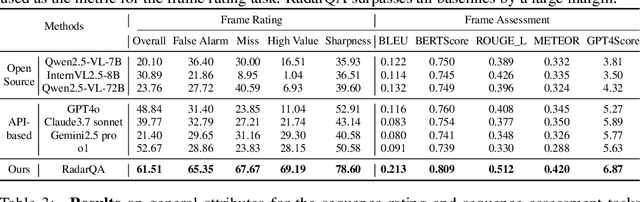
Quality analysis of weather forecasts is an essential topic in meteorology. Although traditional score-based evaluation metrics can quantify certain forecast errors, they are still far from meteorological experts in terms of descriptive capability, interpretability, and understanding of dynamic evolution. With the rapid development of Multi-modal Large Language Models (MLLMs), these models become potential tools to overcome the above challenges. In this work, we introduce an MLLM-based weather forecast analysis method, RadarQA, integrating key physical attributes with detailed assessment reports. We introduce a novel and comprehensive task paradigm for multi-modal quality analysis, encompassing both single frame and sequence, under both rating and assessment scenarios. To support training and benchmarking, we design a hybrid annotation pipeline that combines human expert labeling with automated heuristics. With such an annotation method, we construct RQA-70K, a large-scale dataset with varying difficulty levels for radar forecast quality evaluation. We further design a multi-stage training strategy that iteratively improves model performance at each stage. Extensive experiments show that RadarQA outperforms existing general MLLMs across all evaluation settings, highlighting its potential for advancing quality analysis in weather prediction.
EarthLink: A Self-Evolving AI Agent for Climate Science
Jul 24, 2025


Modern Earth science is at an inflection point. The vast, fragmented, and complex nature of Earth system data, coupled with increasingly sophisticated analytical demands, creates a significant bottleneck for rapid scientific discovery. Here we introduce EarthLink, the first AI agent designed as an interactive copilot for Earth scientists. It automates the end-to-end research workflow, from planning and code generation to multi-scenario analysis. Unlike static diagnostic tools, EarthLink can learn from user interaction, continuously refining its capabilities through a dynamic feedback loop. We validated its performance on a number of core scientific tasks of climate change, ranging from model-observation comparisons to the diagnosis of complex phenomena. In a multi-expert evaluation, EarthLink produced scientifically sound analyses and demonstrated an analytical competency that was rated as comparable to specific aspects of a human junior researcher's workflow. Additionally, its transparent, auditable workflows and natural language interface empower scientists to shift from laborious manual execution to strategic oversight and hypothesis generation. EarthLink marks a pivotal step towards an efficient, trustworthy, and collaborative paradigm for Earth system research in an era of accelerating global change. The system is accessible at our website https://earthlink.intern-ai.org.cn.
MSEarth: A Benchmark for Multimodal Scientific Comprehension of Earth Science
May 27, 2025The rapid advancement of multimodal large language models (MLLMs) has unlocked new opportunities to tackle complex scientific challenges. Despite this progress, their application in addressing earth science problems, especially at the graduate level, remains underexplored. A significant barrier is the absence of benchmarks that capture the depth and contextual complexity of geoscientific reasoning. Current benchmarks often rely on synthetic datasets or simplistic figure-caption pairs, which do not adequately reflect the intricate reasoning and domain-specific insights required for real-world scientific applications. To address these gaps, we introduce MSEarth, a multimodal scientific benchmark curated from high-quality, open-access scientific publications. MSEarth encompasses the five major spheres of Earth science: atmosphere, cryosphere, hydrosphere, lithosphere, and biosphere, featuring over 7K figures with refined captions. These captions are crafted from the original figure captions and enriched with discussions and reasoning from the papers, ensuring the benchmark captures the nuanced reasoning and knowledge-intensive content essential for advanced scientific tasks. MSEarth supports a variety of tasks, including scientific figure captioning, multiple choice questions, and open-ended reasoning challenges. By bridging the gap in graduate-level benchmarks, MSEarth provides a scalable and high-fidelity resource to enhance the development and evaluation of MLLMs in scientific reasoning. The benchmark is publicly available to foster further research and innovation in this field. Resources related to this benchmark can be found at https://huggingface.co/MSEarth and https://github.com/xiangyu-mm/MSEarth.
EarthSE: A Benchmark Evaluating Earth Scientific Exploration Capability for Large Language Models
May 22, 2025Advancements in Large Language Models (LLMs) drive interest in scientific applications, necessitating specialized benchmarks such as Earth science. Existing benchmarks either present a general science focus devoid of Earth science specificity or cover isolated subdomains, lacking holistic evaluation. Furthermore, current benchmarks typically neglect the assessment of LLMs' capabilities in open-ended scientific exploration. In this paper, we present a comprehensive and professional benchmark for the Earth sciences, designed to evaluate the capabilities of LLMs in scientific exploration within this domain, spanning from fundamental to advanced levels. Leveraging a corpus of 100,000 research papers, we first construct two Question Answering (QA) datasets: Earth-Iron, which offers extensive question coverage for broad assessment, and Earth-Silver, which features a higher level of difficulty to evaluate professional depth. These datasets encompass five Earth spheres, 114 disciplines, and 11 task categories, assessing foundational knowledge crucial for scientific exploration. Most notably, we introduce Earth-Gold with new metrics, a dataset comprising open-ended multi-turn dialogues specifically designed to evaluate the advanced capabilities of LLMs in scientific exploration, including methodology induction, limitation analysis, and concept proposal. Extensive experiments reveal limitations in 11 leading LLMs across different domains and tasks, highlighting considerable room for improvement in their scientific exploration capabilities. The benchmark is available on https://huggingface.co/ai-earth .
Diffusion Models Need Visual Priors for Image Generation
Oct 11, 2024



Conventional class-guided diffusion models generally succeed in generating images with correct semantic content, but often struggle with texture details. This limitation stems from the usage of class priors, which only provide coarse and limited conditional information. To address this issue, we propose Diffusion on Diffusion (DoD), an innovative multi-stage generation framework that first extracts visual priors from previously generated samples, then provides rich guidance for the diffusion model leveraging visual priors from the early stages of diffusion sampling. Specifically, we introduce a latent embedding module that employs a compression-reconstruction approach to discard redundant detail information from the conditional samples in each stage, retaining only the semantic information for guidance. We evaluate DoD on the popular ImageNet-$256 \times 256$ dataset, reducing 7$\times$ training cost compared to SiT and DiT with even better performance in terms of the FID-50K score. Our largest model DoD-XL achieves an FID-50K score of 1.83 with only 1 million training steps, which surpasses other state-of-the-art methods without bells and whistles during inference.
OV-PARTS: Towards Open-Vocabulary Part Segmentation
Oct 08, 2023



Segmenting and recognizing diverse object parts is a crucial ability in applications spanning various computer vision and robotic tasks. While significant progress has been made in object-level Open-Vocabulary Semantic Segmentation (OVSS), i.e., segmenting objects with arbitrary text, the corresponding part-level research poses additional challenges. Firstly, part segmentation inherently involves intricate boundaries, while limited annotated data compounds the challenge. Secondly, part segmentation introduces an open granularity challenge due to the diverse and often ambiguous definitions of parts in the open world. Furthermore, the large-scale vision and language models, which play a key role in the open vocabulary setting, struggle to recognize parts as effectively as objects. To comprehensively investigate and tackle these challenges, we propose an Open-Vocabulary Part Segmentation (OV-PARTS) benchmark. OV-PARTS includes refined versions of two publicly available datasets: Pascal-Part-116 and ADE20K-Part-234. And it covers three specific tasks: Generalized Zero-Shot Part Segmentation, Cross-Dataset Part Segmentation, and Few-Shot Part Segmentation, providing insights into analogical reasoning, open granularity and few-shot adapting abilities of models. Moreover, we analyze and adapt two prevailing paradigms of existing object-level OVSS methods for OV-PARTS. Extensive experimental analysis is conducted to inspire future research in leveraging foundational models for OV-PARTS. The code and dataset are available at https://github.com/OpenRobotLab/OV_PARTS.
Understanding Masked Autoencoders From a Local Contrastive Perspective
Oct 03, 2023Masked AutoEncoder(MAE) has revolutionized the field of self-supervised learning with its simple yet effective masking and reconstruction strategies. However, despite achieving state-of-the-art performance across various downstream vision tasks, the underlying mechanisms that drive MAE's efficacy are less well-explored compared to the canonical contrastive learning paradigm. In this paper, we explore a new perspective to explain what truly contributes to the "rich hidden representations inside the MAE". Firstly, concerning MAE's generative pretraining pathway, with a unique encoder-decoder architecture to reconstruct images from aggressive masking, we conduct an in-depth analysis of the decoder's behaviors. We empirically find that MAE's decoder mainly learns local features with a limited receptive field, adhering to the well-known Locality Principle. Building upon this locality assumption, we propose a theoretical framework that reformulates the reconstruction-based MAE into a local region-level contrastive learning form for improved understanding. Furthermore, to substantiate the local contrastive nature of MAE, we introduce a Siamese architecture that combines the essence of MAE and contrastive learning without masking and explicit decoder, which sheds light on a unified and more flexible self-supervised learning framework.