 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCBench: Benchmarking Object State Change in Text-to-Video Generation
Mar 12, 2026Text-to-video (T2V) generation models have made rapid progress in producing visually high-quality and temporally coherent videos. However, existing benchmarks primarily focus on perceptual quality, text-video alignment, or physical plausibility, leaving a critical aspect of action understanding largely unexplored: object state change (OSC) explicitly specified in the text prompt. OSC refers to the transformation of an object's state induced by an action, such as peeling a potato or slicing a lemon. In this paper, we introduce OSCBench, a benchmark specifically designed to assess OSC performance in T2V models. OSCBench is constructed from instructional cooking data and systematically organizes action-object interactions into regular, novel, and compositional scenarios to probe both in-distribution performance and generalization. We evaluate six representative open-source and proprietary T2V models using both human user study and multimodal large language model (MLLM)-based automatic evaluation. Our results show that, despite strong performance on semantic and scene alignment, current T2V models consistently struggle with accurate and temporally consistent object state changes, especially in novel and compositional settings. These findings position OSC as a key bottleneck in text-to-video generation and establish OSCBench as a diagnostic benchmark for advancing state-aware video generation models.
CaPulse: Detecting Anomalies by Tuning in to the Causal Rhythms of Time Series
Aug 06, 2025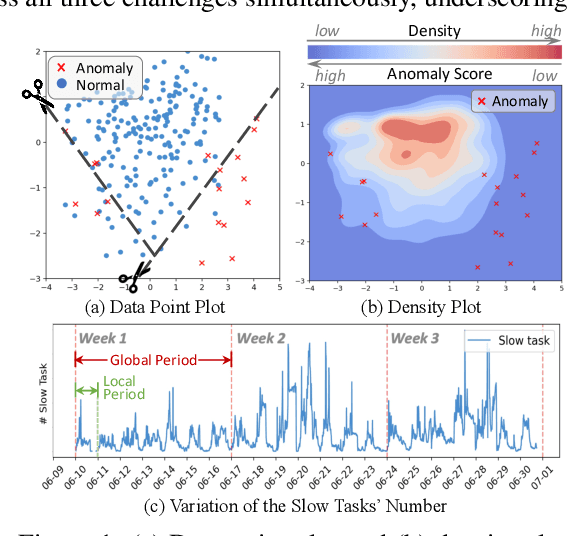
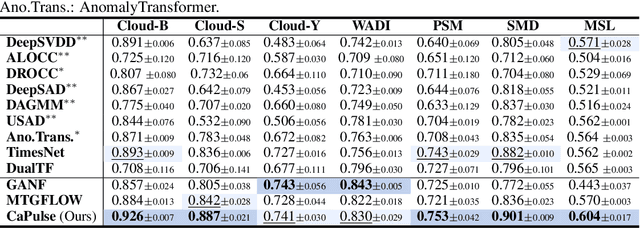

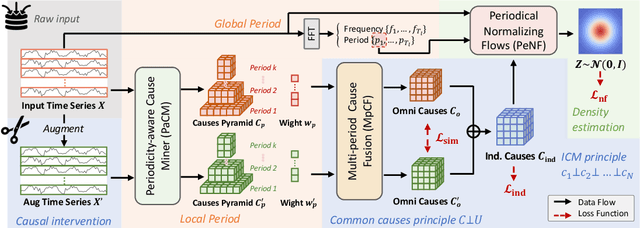
Time series anomaly detection has garnered considerable attention across diverse domains. While existing methods often fail to capture the underlying mechanisms behind anomaly generation in time series data. In addition, time series anomaly detection often faces several data-related inherent challenges, i.e., label scarcity, data imbalance, and complex multi-periodicity. In this paper, we leverage causal tools and introduce a new causality-based framework, CaPulse, which tunes in to the underlying causal pulse of time series data to effectively detect anomalies. Concretely, we begin by building a structural causal model to decipher the generation processes behind anomalies. To tackle the challenges posed by the data, we propose Periodical Normalizing Flows with a novel mask mechanism and carefully designed periodical learners, creating a periodicity-aware, density-based anomaly detection approach. Extensive experiments on seven real-world datasets demonstrate that CaPulse consistently outperforms existing methods, achieving AUROC improvements of 3% to 17%, with enhanced interpretability.
Uni3D-MoE: Scalable Multimodal 3D Scene Understanding via Mixture of Experts
May 27, 2025Recent advancements in multimodal large language models (MLLMs) have demonstrated considerable potential for comprehensive 3D scene understanding. However, existing approaches typically utilize only one or a limited subset of 3D modalities, resulting in incomplete representations of 3D scenes and reduced interpretive accuracy. Furthermore, different types of queries inherently depend on distinct modalities, indicating that uniform processing of all modality tokens may fail to effectively capture query-specific context. To address these challenges, we propose Uni3D-MoE, a sparse Mixture-of-Experts (MoE)-based 3D MLLM designed to enable adaptive 3D multimodal fusion. Specifically, Uni3D-MoE integrates a comprehensive set of 3D modalities, including multi-view RGB and depth images, bird's-eye-view (BEV) maps, point clouds, and voxel representations. At its core, our framework employs a learnable routing mechanism within the sparse MoE-based large language model, dynamically selecting appropriate experts at the token level. Each expert specializes in processing multimodal tokens based on learned modality preferences, thus facilitating flexible collaboration tailored to diverse task-specific requirements. Extensive evaluations on standard 3D scene understanding benchmarks and specialized datasets demonstrate the efficacy of Uni3D-MoE.
JointDistill: Adaptive Multi-Task Distillation for Joint Depth Estimation and Scene Segmentation
May 15, 2025Depth estimation and scene segmentation are two important tasks in intelligent transportation systems. A joint modeling of these two tasks will reduce the requirement for both the storage and training efforts. This work explores how the multi-task distillation could be used to improve such unified modeling. While existing solutions transfer multiple teachers' knowledge in a static way, we propose a self-adaptive distillation method that can dynamically adjust the knowledge amount from each teacher according to the student's current learning ability. Furthermore, as multiple teachers exist, the student's gradient update direction in the distillation is more prone to be erroneous where knowledge forgetting may occur. To avoid this, we propose a knowledge trajectory to record the most essential information that a model has learnt in the past, based on which a trajectory-based distillation loss is designed to guide the student to follow the learning curve similarly in a cost-effective way. We evaluate our method on multiple benchmarking datasets including Cityscapes and NYU-v2. Compared to the state-of-the-art solutions, our method achieves a clearly improvement. The code is provided in the supplementary materials.
OpenAVS: Training-Free Open-Vocabulary Audio Visual Segmentation with Foundational Models
Apr 30, 2025Audio-visual segmentation aims to separate sounding objects from videos by predicting pixel-level masks based on audio signals. Existing methods primarily concentrate on closed-set scenarios and direct audio-visual alignment and fusion, which limits their capability to generalize to new, unseen situations. In this paper, we propose OpenAVS, a novel training-free language-based approach that, for the first time, effectively aligns audio and visual modalities using text as a proxy for open-vocabulary Audio-Visual Segmentation (AVS). Equipped with multimedia foundation models, OpenAVS directly infers masks through 1) audio-to-text prompt generation, 2) LLM-guided prompt translation, and 3) text-to-visual sounding object segmentation. The objective of OpenAVS is to establish a simple yet flexible architecture that relies on the most appropriate foundation models by fully leveraging their capabilities to enable more effective knowledge transfer to the downstream AVS task. Moreover, we present a model-agnostic framework OpenAVS-ST that enables the integration of OpenAVS with any advanced supervised AVS model via pseudo-label based self-training. This approach enhances performance by effectively utilizing large-scale unlabeled data when available. Comprehensive experiments on three benchmark datasets demonstrate the superior performance of OpenAVS. It surpasses existing unsupervised, zero-shot, and few-shot AVS methods by a significant margin, achieving absolute performance gains of approximately 9.4% and 10.9% in mIoU and F-score, respectively, in challenging scenarios.
Reimagining Urban Science: Scaling Causal Inference with Large Language Models
Apr 15, 2025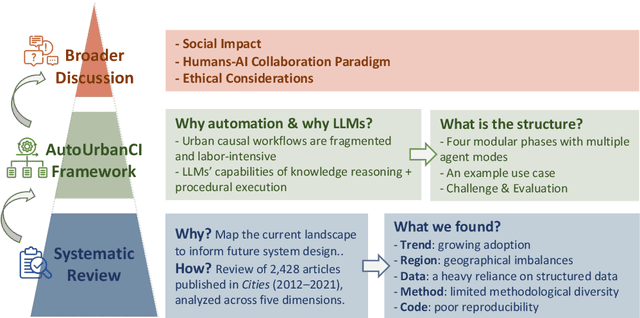
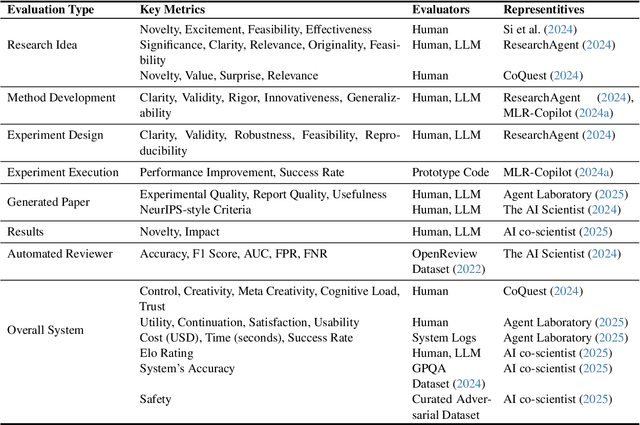
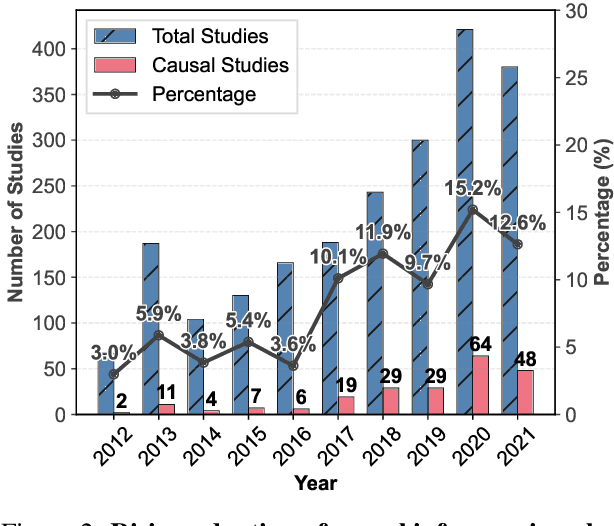

Urban causal research is essential for understanding the complex dynamics of cities and informing evidence-based policies. However, it is challenged by the inefficiency and bias of hypothesis generation, barriers to multimodal data complexity, and the methodological fragility of causal experimentation. Recent advances in large language models (LLMs) present an opportunity to rethink how urban causal analysis is conducted. This Perspective examines current urban causal research by analyzing taxonomies that categorize research topics, data sources, and methodological approaches to identify structural gaps. We then introduce an LLM-driven conceptual framework, AutoUrbanCI, composed of four distinct modular agents responsible for hypothesis generation, data engineering, experiment design and execution, and results interpretation with policy recommendations. We propose evaluation criteria for rigor and transparency and reflect on implications for human-AI collaboration, equity, and accountability. We call for a new research agenda that embraces AI-augmented workflows not as replacements for human expertise but as tools to broaden participation, improve reproducibility, and unlock more inclusive forms of urban causal reasoning.
TAIL: Text-Audio Incremental Learning
Mar 06, 2025



Many studies combine text and audio to capture multi-modal information but they overlook the model's generalization ability on new datasets. Introducing new datasets may affect the feature space of the original dataset, leading to catastrophic forgetting. Meanwhile, large model parameters can significantly impact training performance. To address these limitations, we introduce a novel task called Text-Audio Incremental Learning (TAIL) task for text-audio retrieval, and propose a new method, PTAT, Prompt Tuning for Audio-Text incremental learning. This method utilizes prompt tuning to optimize the model parameters while incorporating an audio-text similarity and feature distillation module to effectively mitigate catastrophic forgetting. We benchmark our method and previous incremental learning methods on AudioCaps, Clotho, BBC Sound Effects and Audioset datasets, and our method outperforms previous methods significantly, particularly demonstrating stronger resistance to forgetting on older datasets. Compared to the full-parameters Finetune (Sequential) method, our model only requires 2.42\% of its parameters, achieving 4.46\% higher performance.
Facilitate Collaboration between Large Language Model and Task-specific Model for Time Series Anomaly Detection
Jan 10, 2025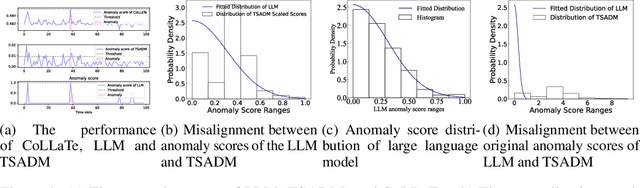
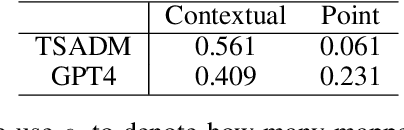
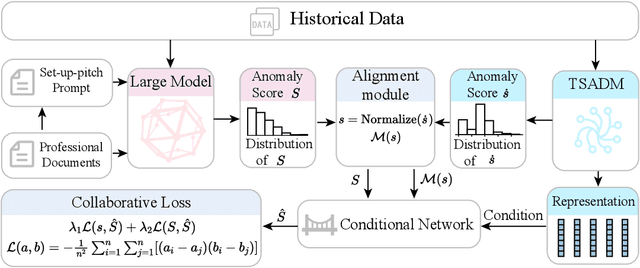
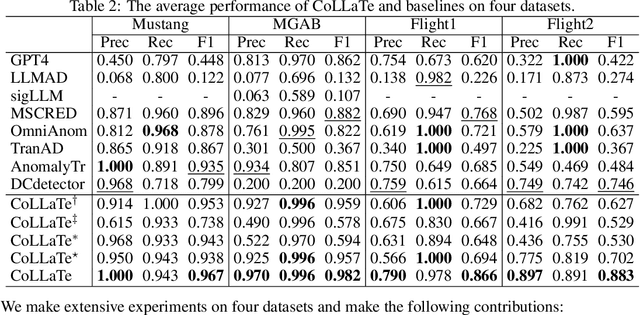
In anomaly detection, methods based on large language models (LLMs) can incorporate expert knowledge, while task-specific smaller models excel at extracting normal patterns and detecting value fluctuations. Inspired by the human nervous system, where the brain stores expert knowledge and the peripheral nervous system and spinal cord handle specific tasks like withdrawal and knee-jerk reflexes, we propose CoLLaTe, a framework designed to facilitate collaboration between LLMs and task-specific models, leveraging the strengths of both. In this work, we first formulate the collaboration process and identify two key challenges in the collaboration between LLMs and task-specific models: (1) the misalignment between the expression domains of LLMs and smaller models, and (2) error accumulation arising from the predictions of both models. To address these challenges, we introduce two key components in CoLLaTe: the alignment module and the collaborative loss function. Through theoretical analysis and experimental validation, we demonstrate that these components effectively mitigate the identified challenges and achieve better performance than LLM based methods and task-specific smaller model.
Improving Multimodal LLMs Ability In Geometry Problem Solving, Reasoning, And Multistep Scoring
Dec 01, 2024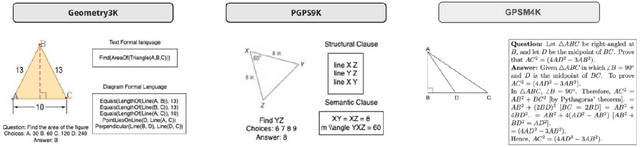
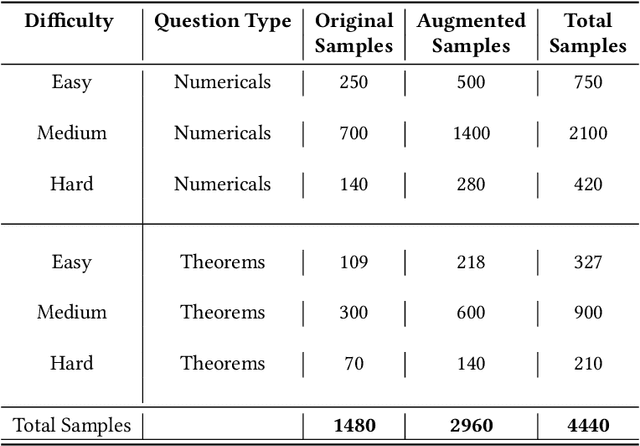
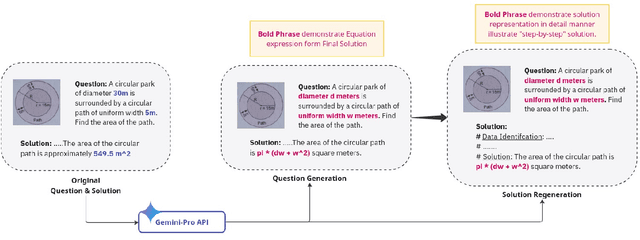
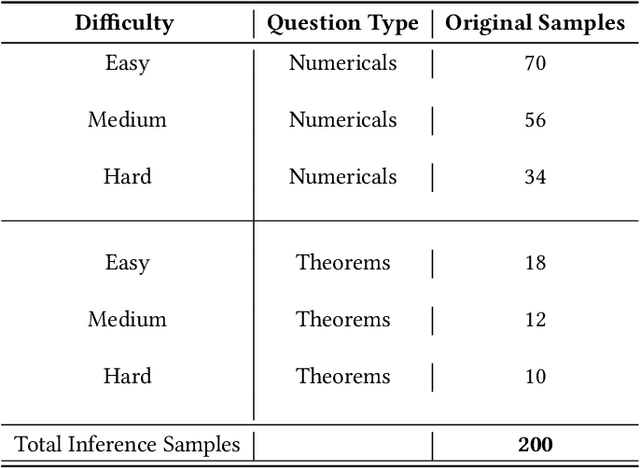
This paper presents GPSM4K, a comprehensive geometry multimodal dataset tailored to augment the problem-solving capabilities of Large Vision Language Models (LVLMs). GPSM4K encompasses 2157 multimodal question-answer pairs manually extracted from mathematics textbooks spanning grades 7-12 and is further augmented to 5340 problems, consisting of both numerical and theorem-proving questions. In contrast to PGPS9k, Geometry3K, and Geo170K which feature only objective-type questions, GPSM4K offers detailed step-by-step solutions in a consistent format, facilitating a comprehensive evaluation of problem-solving approaches. This dataset serves as an excellent benchmark for assessing the geometric reasoning capabilities of LVLMs. Evaluation of our test set shows that there is scope for improvement needed in open-source language models in geometry problem-solving. Finetuning on our training set increases the geometry problem-solving capabilities of models. Further, We also evaluate the effectiveness of techniques such as image captioning and Retrieval Augmentation generation (RAG) on model performance. We leveraged LLM to automate the task of final answer evaluation by providing ground truth and predicted solutions. This research will help to assess and improve the geometric reasoning capabilities of LVLMs.
Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts
Oct 14, 2024



Time series foundation models have demonstrated impressive performance as zero-shot forecasters. However, achieving effectively unified training on time series remains an open challenge. Existing approaches introduce some level of model specialization to account for the highly heterogeneous nature of time series data. For instance, Moirai pursues unified training by employing multiple input/output projection layers, each tailored to handle time series at a specific frequency. Similarly, TimesFM maintains a frequency embedding dictionary for this purpose. We identify two major drawbacks to this human-imposed frequency-level model specialization: (1) Frequency is not a reliable indicator of the underlying patterns in time series. For example, time series with different frequencies can display similar patterns, while those with the same frequency may exhibit varied patterns. (2) Non-stationarity is an inherent property of real-world time series, leading to varied distributions even within a short context window of a single time series. Frequency-level specialization is too coarse-grained to capture this level of diversity. To address these limitations, this paper introduces Moirai-MoE, using a single input/output projection layer while delegating the modeling of diverse time series patterns to the sparse mixture of experts (MoE) within Transformers. With these designs, Moirai-MoE reduces reliance on human-defined heuristics and enables automatic token-level specialization. Extensive experiments on 39 datasets demonstrate the superiority of Moirai-MoE over existing foundation models in both in-distribution and zero-shot scenarios. Furthermore, this study conducts comprehensive model analyses to explore the inner workings of time series MoE foundation models and provides valuable insights for future research.