 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry over Density: Few-Shot Cross-Domain OOD Detection
May 05, 2026Out-of-distribution (OOD) detection identifies test samples that fall outside a model's training distribution, a capability critical for safe deployment in high-stakes applications. Standard OOD detectors are trained on a specific in-distribution (ID) dataset and detect deviations from that single domain. In contrast, we study few-shot cross-domain OOD detection: given a \emph{single} pre-trained model, can we perform OOD detection on \emph{arbitrary} new ID-OOD task pairs using only a handful of ID samples at inference time, with no additional training? We propose \textbf{UFCOD}, a unified framework that achieves this goal through information-geometric analysis of diffusion trajectories. Our key insight is that diffusion noise predictions are score functions (gradients of log-density), and we extract two energy features: \emph{Path Energy} (integrated score magnitude) and \emph{Dynamics Energy} (score smoothness), that form a discrete Sobolev norm capturing how samples interact with the learned diffusion process. The central contribution is a \textbf{train-once, deploy-anywhere} paradigm: a diffusion model trained on a single dataset (e.g., CelebA) serves as a universal feature extractor for OOD detection across semantically unrelated domains (e.g., CIFAR-10, SVHN, Textures). At deployment, each new task requires only $\sim$100 unlabeled ID samples for inference: no retraining, no fine-tuning, no task-specific adaptation. Using 100 ID samples per task, UFCOD achieves 93.7\% average AUROC across 12 cross-domain benchmarks, competitive with methods trained on 50k--163k samples, demonstrating $\sim$500$\times$ improvement in sample efficiency. See our code in https://github.com/lili0415/UFCOD.
Audio-Visual Intelligence in Large Foundation Models
May 05, 2026Audio-Visual Intelligence (AVI) has emerged as a central frontier in artificial intelligence, bridging auditory and visual modalities to enable machines that can perceive, generate, and interact in the multimodal real world. In the era of large foundation models, joint modeling of audio and vision has become increasingly crucial, i.e., not only for understanding but also for controllable generation and reasoning across dynamic, temporally grounded signals. Recent advances, such as Meta MovieGen and Google Veo-3, highlight the growing industrial and academic focus on unified audio-vision architectures that learn from massive multimodal data. However, despite rapid progress, the literature remains fragmented, spanning diverse tasks, inconsistent taxonomies, and heterogeneous evaluation practices that impede systematic comparison and knowledge integration. This survey provides the first comprehensive review of AVI through the lens of large foundation models. We establish a unified taxonomy covering the broad landscape of AVI tasks, ranging from understanding (e.g., speech recognition, sound localization) to generation (e.g., audio-driven video synthesis, video-to-audio) and interaction (e.g., dialogue, embodied, or agentic interfaces). We synthesize methodological foundations, including modality tokenization, cross-modal fusion, autoregressive and diffusion-based generation, large-scale pretraining, instruction alignment, and preference optimization. Furthermore, we curate representative datasets, benchmarks, and evaluation metrics, offering a structured comparison across task families and identifying open challenges in synchronization, spatial reasoning, controllability, and safety. By consolidating this rapidly expanding field into a coherent framework, this survey aims to serve as a foundational reference for future research on large-scale AVI.
SOAR: Self-Correction for Optimal Alignment and Refinement in Diffusion Models
Apr 14, 2026The post-training pipeline for diffusion models currently has two stages: supervised fine-tuning (SFT) on curated data and reinforcement learning (RL) with reward models. A fundamental gap separates them. SFT optimizes the denoiser only on ground-truth states sampled from the forward noising process; once inference deviates from these ideal states, subsequent denoising relies on out-of-distribution generalization rather than learned correction, exhibiting the same exposure bias that afflicts autoregressive models, but accumulated along the denoising trajectory instead of the token sequence. RL can in principle address this mismatch, yet its terminal reward signal is sparse, suffers from credit-assignment difficulty, and risks reward hacking. We propose SOAR (Self-Correction for Optimal Alignment and Refinement), a bias-correction post-training method that fills this gap. Starting from a real sample, SOAR performs a single stop-gradient rollout with the current model, re-noises the resulting off-trajectory state, and supervises the model to steer back toward the original clean target. The method is on-policy, reward-free, and provides dense per-timestep supervision with no credit-assignment problem. On SD3.5-Medium, SOAR improves GenEval from 0.70 to 0.78 and OCR from 0.64 to 0.67 over SFT, while simultaneously raising all model-based preference scores. In controlled reward-specific experiments, SOAR surpasses Flow-GRPO in final metric value on both aesthetic and text-image alignment tasks, despite having no access to a reward model. Since SOAR's base loss subsumes the standard SFT objective, it can directly replace SFT as a stronger first post-training stage after pretraining, while remaining fully compatible with subsequent RL alignment.
Secure On-Device Video OOD Detection Without Backpropagation
Mar 08, 2025Out-of-Distribution (OOD) detection is critical for ensuring the reliability of machine learning models in safety-critical applications such as autonomous driving and medical diagnosis. While deploying personalized OOD detection directly on edge devices is desirable, it remains challenging due to large model sizes and the computational infeasibility of on-device training. Federated learning partially addresses this but still requires gradient computation and backpropagation, exceeding the capabilities of many edge devices. To overcome these challenges, we propose SecDOOD, a secure cloud-device collaboration framework for efficient on-device OOD detection without requiring device-side backpropagation. SecDOOD utilizes cloud resources for model training while ensuring user data privacy by retaining sensitive information on-device. Central to SecDOOD is a HyperNetwork-based personalized parameter generation module, which adapts cloud-trained models to device-specific distributions by dynamically generating local weight adjustments, effectively combining central and local information without local fine-tuning. Additionally, our dynamic feature sampling and encryption strategy selectively encrypts only the most informative feature channels, largely reducing encryption overhead without compromising detection performance. Extensive experiments across multiple datasets and OOD scenarios demonstrate that SecDOOD achieves performance comparable to fully fine-tuned models, enabling secure, efficient, and personalized OOD detection on resource-limited edge devices. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/Dystopians/SecDOOD.
Grounding is All You Need? Dual Temporal Grounding for Video Dialog
Oct 08, 2024
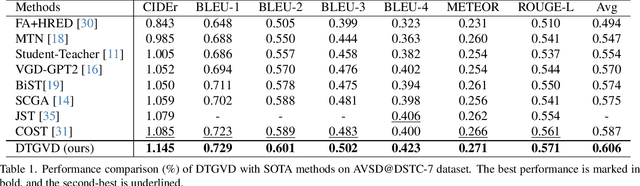
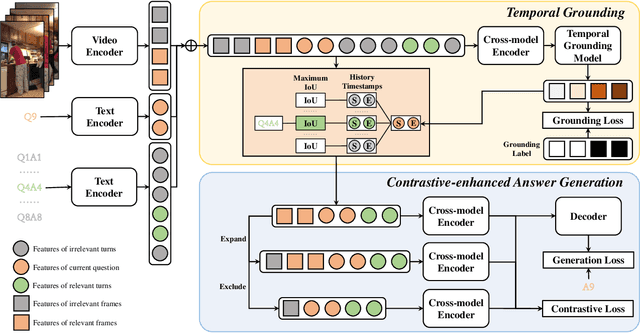

In the realm of video dialog response generation, the understanding of video content and the temporal nuances of conversation history are paramount. While a segment of current research leans heavily on large-scale pretrained visual-language models and often overlooks temporal dynamics, another delves deep into spatial-temporal relationships within videos but demands intricate object trajectory pre-extractions and sidelines dialog temporal dynamics. This paper introduces the Dual Temporal Grounding-enhanced Video Dialog model (DTGVD), strategically designed to merge the strengths of both dominant approaches. It emphasizes dual temporal relationships by predicting dialog turn-specific temporal regions, filtering video content accordingly, and grounding responses in both video and dialog contexts. One standout feature of DTGVD is its heightened attention to chronological interplay. By recognizing and acting upon the dependencies between different dialog turns, it captures more nuanced conversational dynamics. To further bolster the alignment between video and dialog temporal dynamics, we've implemented a list-wise contrastive learning strategy. Within this framework, accurately grounded turn-clip pairings are designated as positive samples, while less precise pairings are categorized as negative. This refined classification is then funneled into our holistic end-to-end response generation mechanism. Evaluations using AVSD@DSTC-7 and AVSD@DSTC-8 datasets underscore the superiority of our methodology.
Described Spatial-Temporal Video Detection
Jul 08, 2024



Detecting visual content on language expression has become an emerging topic in the community. However, in the video domain, the existing setting, i.e., spatial-temporal video grounding (STVG), is formulated to only detect one pre-existing object in each frame, ignoring the fact that language descriptions can involve none or multiple entities within a video. In this work, we advance the STVG to a more practical setting called described spatial-temporal video detection (DSTVD) by overcoming the above limitation. To facilitate the exploration of DSTVD, we first introduce a new benchmark, namely DVD-ST. Notably, DVD-ST supports grounding from none to many objects onto the video in response to queries and encompasses a diverse range of over 150 entities, including appearance, actions, locations, and interactions. The extensive breadth and diversity of the DVD-ST dataset make it an exemplary testbed for the investigation of DSTVD. In addition to the new benchmark, we further present two baseline methods for our proposed DSTVD task by extending two representative STVG models, i.e., TubeDETR, and STCAT. These extended models capitalize on tubelet queries to localize and track referred objects across the video sequence. Besides, we adjust the training objectives of these models to optimize spatial and temporal localization accuracy and multi-class classification capabilities. Furthermore, we benchmark the baselines on the introduced DVD-ST dataset and conduct extensive experimental analysis to guide future investigation. Our code and benchmark will be publicly available.
Domain-wise Invariant Learning for Panoptic Scene Graph Generation
Oct 09, 2023Panoptic Scene Graph Generation (PSG) involves the detection of objects and the prediction of their corresponding relationships (predicates). However, the presence of biased predicate annotations poses a significant challenge for PSG models, as it hinders their ability to establish a clear decision boundary among different predicates. This issue substantially impedes the practical utility and real-world applicability of PSG models. To address the intrinsic bias above, we propose a novel framework to infer potentially biased annotations by measuring the predicate prediction risks within each subject-object pair (domain), and adaptively transfer the biased annotations to consistent ones by learning invariant predicate representation embeddings. Experiments show that our method significantly improves the performance of benchmark models, achieving a new state-of-the-art performance, and shows great generalization and effectiveness on PSG dataset.
Causal SAR ATR with Limited Data via Dual Invariance
Aug 18, 2023



Synthetic aperture radar automatic target recognition (SAR ATR) with limited data has recently been a hot research topic to enhance weak generalization. Despite many excellent methods being proposed, a fundamental theory is lacked to explain what problem the limited SAR data causes, leading to weak generalization of ATR. In this paper, we establish a causal ATR model demonstrating that noise $N$ that could be blocked with ample SAR data, becomes a confounder with limited data for recognition. As a result, it has a detrimental causal effect damaging the efficacy of feature $X$ extracted from SAR images, leading to weak generalization of SAR ATR with limited data. The effect of $N$ on feature can be estimated and eliminated by using backdoor adjustment to pursue the direct causality between $X$ and the predicted class $Y$. However, it is difficult for SAR images to precisely estimate and eliminated the effect of $N$ on $X$. The limited SAR data scarcely powers the majority of existing optimization losses based on empirical risk minimization (ERM), thus making it difficult to effectively eliminate $N$'s effect. To tackle with difficult estimation and elimination of $N$'s effect, we propose a dual invariance comprising the inner-class invariant proxy and the noise-invariance loss. Motivated by tackling change with invariance, the inner-class invariant proxy facilitates precise estimation of $N$'s effect on $X$ by obtaining accurate invariant features for each class with the limited data. The noise-invariance loss transitions the ERM's data quantity necessity into a need for noise environment annotations, effectively eliminating $N$'s effect on $X$ by cleverly applying the previous $N$'s estimation as the noise environment annotations. Experiments on three benchmark datasets indicate that the proposed method achieves superior performance.
Unveiling Causalities in SAR ATR: A Causal Interventional Approach for Limited Data
Aug 18, 2023
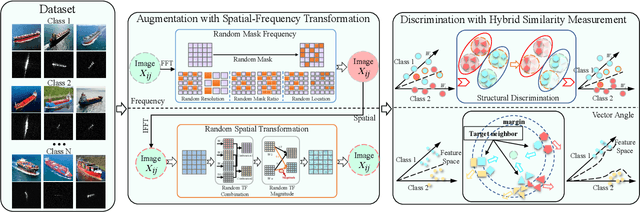
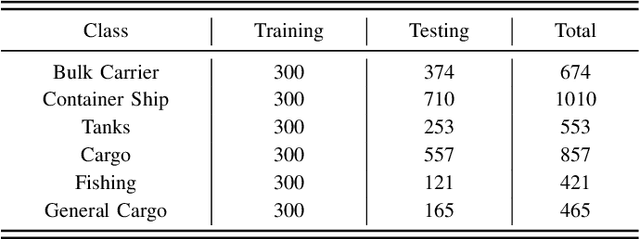
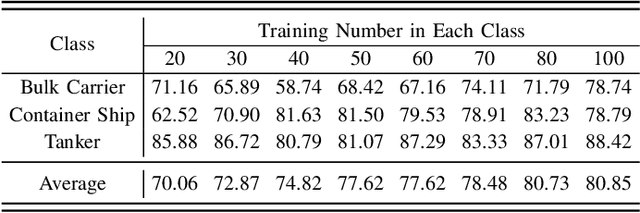
Synthetic aperture radar automatic target recognition (SAR ATR) methods fall short with limited training data. In this letter, we propose a causal interventional ATR method (CIATR) to formulate the problem of limited SAR data which helps us uncover the ever-elusive causalities among the key factors in ATR, and thus pursue the desired causal effect without changing the imaging conditions. A structural causal model (SCM) is comprised using causal inference to help understand how imaging conditions acts as a confounder introducing spurious correlation when SAR data is limited. This spurious correlation among SAR images and the predicted classes can be fundamentally tackled with the conventional backdoor adjustments. An effective implement of backdoor adjustments is proposed by firstly using data augmentation with spatial-frequency domain hybrid transformation to estimate the potential effect of varying imaging conditions on SAR images. Then, a feature discrimination approach with hybrid similarity measurement is introduced to measure and mitigate the structural and vector angle impacts of varying imaging conditions on the extracted features from SAR images. Thus, our CIATR can pursue the true causality between SAR images and the corresponding classes even with limited SAR data. Experiments and comparisons conducted on the moving and stationary target acquisition and recognition (MSTAR) and OpenSARship datasets have shown the effectiveness of our method with limited SAR data.
Panoptic Scene Graph Generation with Semantics-prototype Learning
Jul 28, 2023Panoptic Scene Graph Generation (PSG) parses objects and predicts their relationships (predicate) to connect human language and visual scenes. However, different language preferences of annotators and semantic overlaps between predicates lead to biased predicate annotations in the dataset, i.e. different predicates for same object pairs. Biased predicate annotations make PSG models struggle in constructing a clear decision plane among predicates, which greatly hinders the real application of PSG models. To address the intrinsic bias above, we propose a novel framework named ADTrans to adaptively transfer biased predicate annotations to informative and unified ones. To promise consistency and accuracy during the transfer process, we propose to measure the invariance of representations in each predicate class, and learn unbiased prototypes of predicates with different intensities. Meanwhile, we continuously measure the distribution changes between each presentation and its prototype, and constantly screen potential biased data. Finally, with the unbiased predicate-prototype representation embedding space, biased annotations are easily identified. Experiments show that ADTrans significantly improves the performance of benchmark models, achieving a new state-of-the-art performance, and shows great generalization and effectiveness on multiple datasets.