 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Sparse Inversion and Token Relabel Enhanced One-shot Federated Learning with ViTs
May 11, 2026One-Shot Federated Learning, where a central server learns a global model in a single communication round, has emerged as a promising paradigm. However, under extremely non-IID settings, existing data-free methods often generate low-quality data that suffers from severe semantic misalignment with ground-truth labels. To overcome these issues, we propose a novel Federated Model Inversion and Token Relabel (FedMITR) framework, which trains the global model by fully exploiting all patches of synthetic images. Specifically, FedMITR employs sparse model inversion during data generation, selectively inverting semantic foregrounds while halting the inversion of uninformative backgrounds. To address semantically meaningless tokens that hinder ViT predictions, we implement a differentiated strategy: patches with high information density utilize generated pseudo-labels, while patches with low information density are relabeled via ensemble models for robust distillation. Theoretically, our analysis based on algorithmic stability reveals that Sparse Model Inversion eliminates gradient instability arising from background noise, while Token Relabel effectively reduces gradient variance, collectively guaranteeing a tighter generalization bound. Empirically, extensive experimental results demonstrate that FedMITR substantially outperforms existing baselines under various settings.
TableVista: Benchmarking Multimodal Table Reasoning under Visual and Structural Complexity
May 07, 2026We introduce TableVista, a comprehensive benchmark for evaluating foundation models in multimodal table reasoning under visual and structural complexity. TableVista consists of 3,000 high-quality table reasoning problems, where each instance is expanded into 10 distinct visual variants through our multi-style rendering and transformation pipeline. This process encompasses diverse scenario styles, robustness perturbations, and vision-only configurations, culminating in 30,000 multimodal samples for a multi-dimensional evaluation. We conduct an extensive evaluation of 29 state-of-the-art open-source and proprietary foundation models on TableVista. Through comprehensive quantitative and qualitative analysis, we find that while evaluated models remain largely stable across diverse rendering styles, they exhibit pronounced performance degradation on complex structural layouts and vision-only settings, revealing that current models struggle to maintain reasoning consistency when structural complexity combines with visually integrated presentations. These findings highlight critical gaps in current multimodal capabilities, providing insights for advancing more robust and reliable table understanding models.
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Apr 28, 2026Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
Closing the Confusion Loop: CLIP-Guided Alignment for Source-Free Domain Adaptation
Feb 09, 2026Source-Free Domain Adaptation (SFDA) tackles the problem of adapting a pre-trained source model to an unlabeled target domain without accessing any source data, which is quite suitable for the field of data security. Although recent advances have shown that pseudo-labeling strategies can be effective, they often fail in fine-grained scenarios due to subtle inter-class similarities. A critical but underexplored issue is the presence of asymmetric and dynamic class confusion, where visually similar classes are unequally and inconsistently misclassified by the source model. Existing methods typically ignore such confusion patterns, leading to noisy pseudo-labels and poor target discrimination. To address this, we propose CLIP-Guided Alignment(CGA), a novel framework that explicitly models and mitigates class confusion in SFDA. Generally, our method consists of three parts: (1) MCA: detects first directional confusion pairs by analyzing the predictions of the source model in the target domain; (2) MCC: leverages CLIP to construct confusion-aware textual prompts (e.g. a truck that looks like a bus), enabling more context-sensitive pseudo-labeling; and (3) FAM: builds confusion-guided feature banks for both CLIP and the source model and aligns them using contrastive learning to reduce ambiguity in the representation space. Extensive experiments on various datasets demonstrate that CGA consistently outperforms state-of-the-art SFDA methods, with especially notable gains in confusion-prone and fine-grained scenarios. Our results highlight the importance of explicitly modeling inter-class confusion for effective source-free adaptation. Our code can be find at https://github.com/soloiro/CGA
Reducing Class-Wise Performance Disparity via Margin Regularization
Jan 30, 2026Deep neural networks often exhibit substantial disparities in class-wise accuracy, even when trained on class-balanced data, posing concerns for reliable deployment. While prior efforts have explored empirical remedies, a theoretical understanding of such performance disparities in classification remains limited. In this work, we present Margin Regularization for Performance Disparity Reduction (MR$^2$), a theoretically principled regularization for classification by dynamically adjusting margins in both the logit and representation spaces. Our analysis establishes a margin-based, class-sensitive generalization bound that reveals how per-class feature variability contributes to error, motivating the use of larger margins for hard classes. Guided by this insight, MR$^2$ optimizes per-class logit margins proportional to feature spread and penalizes excessive representation margins to enhance intra-class compactness. Experiments on seven datasets, including ImageNet, and diverse pre-trained backbones (MAE, MoCov2, CLIP) demonstrate that MR$^2$ not only improves overall accuracy but also significantly boosts hard class performance without trading off easy classes, thus reducing performance disparity. Code is available at: https://github.com/BeierZhu/MR2
BalDRO: A Distributionally Robust Optimization based Framework for Large Language Model Unlearning
Jan 14, 2026As Large Language Models (LLMs) increasingly shape online content, removing targeted information from well-trained LLMs (also known as LLM unlearning) has become critical for web governance. A key challenge lies in sample-wise imbalance within the forget set: different samples exhibit widely varying unlearning difficulty, leading to asynchronous forgetting where some knowledge remains insufficiently erased while others become over-forgotten. To address this, we propose BalDRO, a novel and efficient framework for balanced LLM unlearning. BalDRO formulates unlearning as a min-sup process: an inner step identifies a worst-case data distribution that emphasizes hard-to-unlearn samples, while an outer step updates model parameters under this distribution. We instantiate BalDRO via two efficient variants: BalDRO-G, a discrete GroupDRO-based approximation focusing on high-loss subsets, and BalDRO-DV, a continuous Donsker-Varadhan dual method enabling smooth adaptive weighting within standard training pipelines. Experiments on TOFU and MUSE show that BalDRO significantly improves both forgetting quality and model utility over existing methods, and we release code for reproducibility.
Maximizing Local Entropy Where It Matters: Prefix-Aware Localized LLM Unlearning
Jan 06, 2026Machine unlearning aims to forget sensitive knowledge from Large Language Models (LLMs) while maintaining general utility. However, existing approaches typically treat all tokens in a response indiscriminately and enforce uncertainty over the entire vocabulary. This global treatment results in unnecessary utility degradation and extends optimization to content-agnostic regions. To address these limitations, we propose PALU (Prefix-Aware Localized Unlearning), a framework driven by a local entropy maximization objective across both temporal and vocabulary dimensions. PALU reveals that (i) suppressing the sensitive prefix alone is sufficient to sever the causal generation link, and (ii) flattening only the top-$k$ logits is adequate to maximize uncertainty in the critical subspace. These findings allow PALU to avoid redundant optimization across the full vocabulary and parameter space while minimizing collateral damage to general model performance. Extensive experiments validate that PALU achieves superior forgetting efficacy and utility preservation compared to state-of-the-art baselines.
Parallel Diffusion Solver via Residual Dirichlet Policy Optimization
Dec 28, 2025Diffusion models (DMs) have achieved state-of-the-art generative performance but suffer from high sampling latency due to their sequential denoising nature. Existing solver-based acceleration methods often face significant image quality degradation under a low-latency budget, primarily due to accumulated truncation errors arising from the inability to capture high-curvature trajectory segments. In this paper, we propose the Ensemble Parallel Direction solver (dubbed as EPD-Solver), a novel ODE solver that mitigates these errors by incorporating multiple parallel gradient evaluations in each step. Motivated by the geometric insight that sampling trajectories are largely confined to a low-dimensional manifold, EPD-Solver leverages the Mean Value Theorem for vector-valued functions to approximate the integral solution more accurately. Importantly, since the additional gradient computations are independent, they can be fully parallelized, preserving low-latency sampling nature. We introduce a two-stage optimization framework. Initially, EPD-Solver optimizes a small set of learnable parameters via a distillation-based approach. We further propose a parameter-efficient Reinforcement Learning (RL) fine-tuning scheme that reformulates the solver as a stochastic Dirichlet policy. Unlike traditional methods that fine-tune the massive backbone, our RL approach operates strictly within the low-dimensional solver space, effectively mitigating reward hacking while enhancing performance in complex text-to-image (T2I) generation tasks. In addition, our method is flexible and can serve as a plugin (EPD-Plugin) to improve existing ODE samplers.
EverybodyDance: Bipartite Graph-Based Identity Correspondence for Multi-Character Animation
Dec 18, 2025
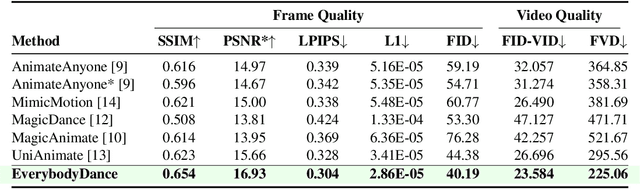

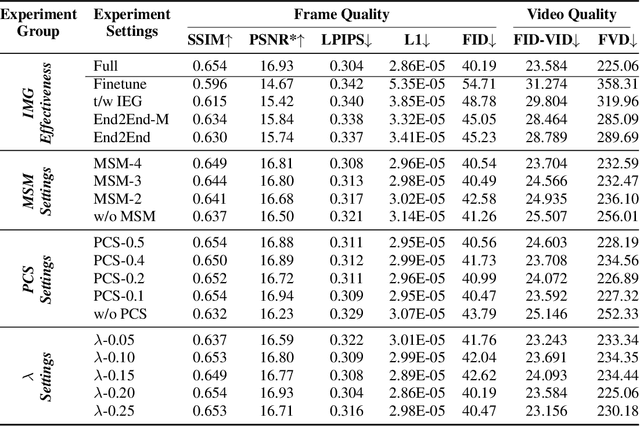
Consistent pose-driven character animation has achieved remarkable progress in single-character scenarios. However, extending these advances to multi-character settings is non-trivial, especially when position swap is involved. Beyond mere scaling, the core challenge lies in enforcing correct Identity Correspondence (IC) between characters in reference and generated frames. To address this, we introduce EverybodyDance, a systematic solution targeting IC correctness in multi-character animation. EverybodyDance is built around the Identity Matching Graph (IMG), which models characters in the generated and reference frames as two node sets in a weighted complete bipartite graph. Edge weights, computed via our proposed Mask-Query Attention (MQA), quantify the affinity between each pair of characters. Our key insight is to formalize IC correctness as a graph structural metric and to optimize it during training. We also propose a series of targeted strategies tailored for multi-character animation, including identity-embedded guidance, a multi-scale matching strategy, and pre-classified sampling, which work synergistically. Finally, to evaluate IC performance, we curate the Identity Correspondence Evaluation benchmark, dedicated to multi-character IC correctness. Extensive experiments demonstrate that EverybodyDance substantially outperforms state-of-the-art baselines in both IC and visual fidelity.
Towards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics
Dec 17, 2025



Human conversation involves continuous exchanges of speech and nonverbal cues such as head nods, gaze shifts, and facial expressions that convey attention and emotion. Modeling these bidirectional dynamics in 3D is essential for building expressive avatars and interactive robots. However, existing frameworks often treat talking and listening as independent processes or rely on non-causal full-sequence modeling, hindering temporal coherence across turns. We present TIMAR (Turn-level Interleaved Masked AutoRegression), a causal framework for 3D conversational head generation that models dialogue as interleaved audio-visual contexts. It fuses multimodal information within each turn and applies turn-level causal attention to accumulate conversational history, while a lightweight diffusion head predicts continuous 3D head dynamics that captures both coordination and expressive variability. Experiments on the DualTalk benchmark show that TIMAR reduces Fréchet Distance and MSE by 15-30% on the test set, and achieves similar gains on out-of-distribution data. The source code will be released in the GitHub repository https://github.com/CoderChen01/towards-seamleass-interaction.