 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV2UV: Generating High-quality UV Texture Maps with Multiview Prompts
Mar 16, 2026Generating high-quality textures for 3D assets is a challenging task. Existing multiview texture generation methods suffer from the multiview inconsistency and missing textures on unseen parts, while UV inpainting texture methods do not generalize well due to insufficient UV data and cannot well utilize 2D image diffusion priors. In this paper, we propose a new method called MV2UV that combines 2D generative priors from multiview generation and the inpainting ability of UV refinement to get high-quality texture maps. Our key idea is to adopt a UV space generative model that simultaneously inpaints unseen parts of multiview images while resolving the inconsistency of multiview images. Experiments show that our method enables a better texture generation quality than existing methods, especially in unseen occluded and multiview-inconsistent parts.
CRAFT: Calibrated Reasoning with Answer-Faithful Traces via Reinforcement Learning for Multi-Hop Question Answering
Feb 01, 2026Retrieval-augmented generation (RAG) is widely used to ground Large Language Models (LLMs) for multi-hop question answering. Recent work mainly focused on improving answer accuracy via fine-tuning and structured or reinforcement-based optimization. However, reliable reasoning in response generation faces three challenges: 1) Reasoning Collapse. Reasoning in multi-hop QA is inherently complex due to multi-hop composition and is further destabilized by noisy retrieval. 2) Reasoning-answer inconsistency. Due to the intrinsic uncertainty of LLM generation and exposure to evidence--distractor mixtures, models may produce correct answers that are not faithfully supported by their intermediate reasoning or evidence. 3) Loss of format control. Traditional chain-of-thought generation often deviates from required structured output formats, leading to incomplete or malformed structured content. To address these challenges, we propose CRAFT (Calibrated Reasoning with Answer-Faithful Traces), a Group Relative Policy Optimization (GRPO) based reinforcement learning framework that trains models to perform faithful reasoning during response generation. CRAFT employs dual reward mechanisms to optimize multi-hop reasoning: deterministic rewards ensure structural correctness while judge-based rewards verify semantic faithfulness. This optimization framework supports controllable trace variants that enable systematic analysis of how structure and scale affect reasoning performance and faithfulness. Experiments on three multi-hop QA benchmarks show that CRAFT improves both answer accuracy and reasoning faithfulness across model scales, with the CRAFT 7B model achieving competitive performance with closed-source LLMs across multiple reasoning trace settings.
UniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Jan 03, 2026We present UniSH, a unified, feed-forward framework for joint metric-scale 3D scene and human reconstruction. A key challenge in this domain is the scarcity of large-scale, annotated real-world data, forcing a reliance on synthetic datasets. This reliance introduces a significant sim-to-real domain gap, leading to poor generalization, low-fidelity human geometry, and poor alignment on in-the-wild videos. To address this, we propose an innovative training paradigm that effectively leverages unlabeled in-the-wild data. Our framework bridges strong, disparate priors from scene reconstruction and HMR, and is trained with two core components: (1) a robust distillation strategy to refine human surface details by distilling high-frequency details from an expert depth model, and (2) a two-stage supervision scheme, which first learns coarse localization on synthetic data, then fine-tunes on real data by directly optimizing the geometric correspondence between the SMPL mesh and the human point cloud. This approach enables our feed-forward model to jointly recover high-fidelity scene geometry, human point clouds, camera parameters, and coherent, metric-scale SMPL bodies, all in a single forward pass. Extensive experiments demonstrate that our model achieves state-of-the-art performance on human-centric scene reconstruction and delivers highly competitive results on global human motion estimation, comparing favorably against both optimization-based frameworks and HMR-only methods. Project page: https://murphylmf.github.io/UniSH/
MeshRipple: Structured Autoregressive Generation of Artist-Meshes
Dec 09, 2025Meshes serve as a primary representation for 3D assets. Autoregressive mesh generators serialize faces into sequences and train on truncated segments with sliding-window inference to cope with memory limits. However, this mismatch breaks long-range geometric dependencies, producing holes and fragmented components. To address this critical limitation, we introduce MeshRipple, which expands a mesh outward from an active generation frontier, akin to a ripple on a surface. MeshRipple rests on three key innovations: a frontier-aware BFS tokenization that aligns the generation order with surface topology; an expansive prediction strategy that maintains coherent, connected surface growth; and a sparse-attention global memory that provides an effectively unbounded receptive field to resolve long-range topological dependencies. This integrated design enables MeshRipple to generate meshes with high surface fidelity and topological completeness, outperforming strong recent baselines.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025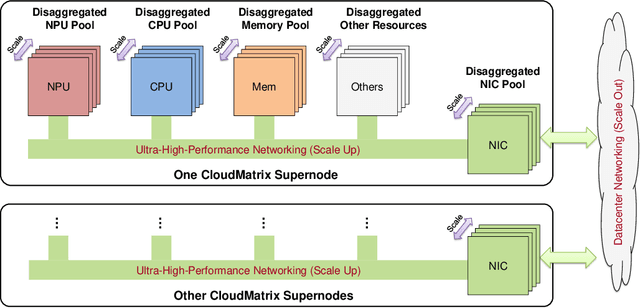
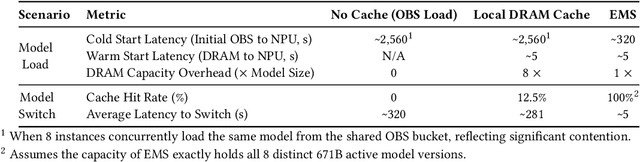
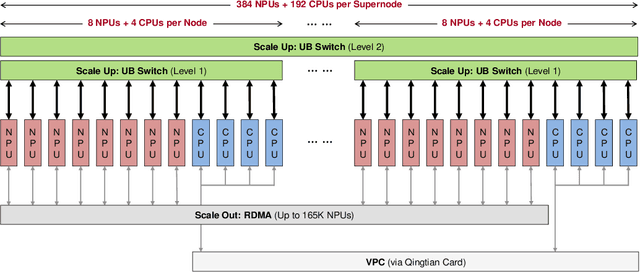
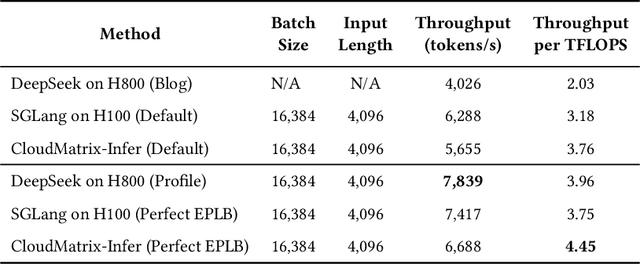
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
CMMLoc: Advancing Text-to-PointCloud Localization with Cauchy-Mixture-Model Based Framework
Mar 05, 2025



The goal of point cloud localization based on linguistic description is to identify a 3D position using textual description in large urban environments, which has potential applications in various fields, such as determining the location for vehicle pickup or goods delivery. Ideally, for a textual description and its corresponding 3D location, the objects around the 3D location should be fully described in the text description. However, in practical scenarios, e.g., vehicle pickup, passengers usually describe only the part of the most significant and nearby surroundings instead of the entire environment. In response to this $\textbf{partially relevant}$ challenge, we propose $\textbf{CMMLoc}$, an uncertainty-aware $\textbf{C}$auchy-$\textbf{M}$ixture-$\textbf{M}$odel ($\textbf{CMM}$) based framework for text-to-point-cloud $\textbf{Loc}$alization. To model the uncertain semantic relations between text and point cloud, we integrate CMM constraints as a prior during the interaction between the two modalities. We further design a spatial consolidation scheme to enable adaptive aggregation of different 3D objects with varying receptive fields. To achieve precise localization, we propose a cardinal direction integration module alongside a modality pre-alignment strategy, helping capture the spatial relationships among objects and bringing the 3D objects closer to the text modality. Comprehensive experiments validate that CMMLoc outperforms existing methods, achieving state-of-the-art results on the KITTI360Pose dataset. Codes are available in this GitHub repository https://github.com/kevin301342/CMMLoc.
SafeEmbodAI: a Safety Framework for Mobile Robots in Embodied AI Systems
Sep 03, 2024Embodied AI systems, including AI-powered robots that autonomously interact with the physical world, stand to be significantly advanced by Large Language Models (LLMs), which enable robots to better understand complex language commands and perform advanced tasks with enhanced comprehension and adaptability, highlighting their potential to improve embodied AI capabilities. However, this advancement also introduces safety challenges, particularly in robotic navigation tasks. Improper safety management can lead to failures in complex environments and make the system vulnerable to malicious command injections, resulting in unsafe behaviours such as detours or collisions. To address these issues, we propose \textit{SafeEmbodAI}, a safety framework for integrating mobile robots into embodied AI systems. \textit{SafeEmbodAI} incorporates secure prompting, state management, and safety validation mechanisms to secure and assist LLMs in reasoning through multi-modal data and validating responses. We designed a metric to evaluate mission-oriented exploration, and evaluations in simulated environments demonstrate that our framework effectively mitigates threats from malicious commands and improves performance in various environment settings, ensuring the safety of embodied AI systems. Notably, In complex environments with mixed obstacles, our method demonstrates a significant performance increase of 267\% compared to the baseline in attack scenarios, highlighting its robustness in challenging conditions.
A Study on Prompt Injection Attack Against LLM-Integrated Mobile Robotic Systems
Aug 07, 2024



The integration of Large Language Models (LLMs) like GPT-4o into robotic systems represents a significant advancement in embodied artificial intelligence. These models can process multi-modal prompts, enabling them to generate more context-aware responses. However, this integration is not without challenges. One of the primary concerns is the potential security risks associated with using LLMs in robotic navigation tasks. These tasks require precise and reliable responses to ensure safe and effective operation. Multi-modal prompts, while enhancing the robot's understanding, also introduce complexities that can be exploited maliciously. For instance, adversarial inputs designed to mislead the model can lead to incorrect or dangerous navigational decisions. This study investigates the impact of prompt injections on mobile robot performance in LLM-integrated systems and explores secure prompt strategies to mitigate these risks. Our findings demonstrate a substantial overall improvement of approximately 30.8% in both attack detection and system performance with the implementation of robust defence mechanisms, highlighting their critical role in enhancing security and reliability in mission-oriented tasks.
OpenOmni: A Collaborative Open Source Tool for Building Future-Ready Multimodal Conversational Agents
Aug 06, 2024



Multimodal conversational agents are highly desirable because they offer natural and human-like interaction. However, there is a lack of comprehensive end-to-end solutions to support collaborative development and benchmarking. While proprietary systems like GPT-4o and Gemini demonstrating impressive integration of audio, video, and text with response times of 200-250ms, challenges remain in balancing latency, accuracy, cost, and data privacy. To better understand and quantify these issues, we developed OpenOmni, an open-source, end-to-end pipeline benchmarking tool that integrates advanced technologies such as Speech-to-Text, Emotion Detection, Retrieval Augmented Generation, Large Language Models, along with the ability to integrate customized models. OpenOmni supports local and cloud deployment, ensuring data privacy and supporting latency and accuracy benchmarking. This flexible framework allows researchers to customize the pipeline, focusing on real bottlenecks and facilitating rapid proof-of-concept development. OpenOmni can significantly enhance applications like indoor assistance for visually impaired individuals, advancing human-computer interaction. Our demonstration video is available https://www.youtube.com/watch?v=zaSiT3clWqY, demo is available via https://openomni.ai4wa.com, code is available via https://github.com/AI4WA/OpenOmniFramework.
Explicitly Guided Information Interaction Network for Cross-modal Point Cloud Completion
Jul 03, 2024



Corresponding author}In this paper, we explore a novel framework, EGIInet (Explicitly Guided Information Interaction Network), a model for View-guided Point cloud Completion (ViPC) task, which aims to restore a complete point cloud from a partial one with a single view image. In comparison with previous methods that relied on the global semantics of input images, EGIInet efficiently combines the information from two modalities by leveraging the geometric nature of the completion task. Specifically, we propose an explicitly guided information interaction strategy supported by modal alignment for point cloud completion. First, in contrast to previous methods which simply use 2D and 3D backbones to encode features respectively, we unified the encoding process to promote modal alignment. Second, we propose a novel explicitly guided information interaction strategy that could help the network identify critical information within images, thus achieving better guidance for completion. Extensive experiments demonstrate the effectiveness of our framework, and we achieved a new state-of-the-art (+16\% CD over XMFnet) in benchmark datasets despite using fewer parameters than the previous methods. The pre-trained model and code and are available at https://github.com/WHU-USI3DV/EGIInet.