 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Knowledge-Guided Decision Calibration for Accurate Fine-Grained Tree Species Classification
Jan 23, 2026Accurate fine-grained tree species classification is critical for forest inventory and biodiversity monitoring. Existing methods predominantly focus on designing complex architectures to fit local data distributions. However, they often overlook the long-tailed distributions and high inter-class similarity inherent in limited data, thereby struggling to distinguish between few-shot or confusing categories. In the process of knowledge dissemination in the human world, individuals will actively seek expert assistance to transcend the limitations of local thinking. Inspired by this, we introduce an external "Domain Expert" and propose an Expert Knowledge-Guided Classification Decision Calibration Network (EKDC-Net) to overcome these challenges. Our framework addresses two core issues: expert knowledge extraction and utilization. Specifically, we first develop a Local Prior Guided Knowledge Extraction Module (LPKEM). By leveraging Class Activation Map (CAM) analysis, LPKEM guides the domain expert to focus exclusively on discriminative features essential for classification. Subsequently, to effectively integrate this knowledge, we design an Uncertainty-Guided Decision Calibration Module (UDCM). This module dynamically corrects the local model's decisions by considering both overall category uncertainty and instance-level prediction uncertainty. Furthermore, we present a large-scale classification dataset covering 102 tree species, named CU-Tree102 to address the issue of scarce diversity in current benchmarks. Experiments on three benchmark datasets demonstrate that our approach achieves state-of-the-art performance. Crucially, as a lightweight plug-and-play module, EKDC-Net improves backbone accuracy by 6.42% and precision by 11.46% using only 0.08M additional learnable parameters. The dataset, code, and pre-trained models are available at https://github.com/WHU-USI3DV/TreeCLS.
WHU-STree: A Multi-modal Benchmark Dataset for Street Tree Inventory
Sep 16, 2025Street trees are vital to urban livability, providing ecological and social benefits. Establishing a detailed, accurate, and dynamically updated street tree inventory has become essential for optimizing these multifunctional assets within space-constrained urban environments. Given that traditional field surveys are time-consuming and labor-intensive, automated surveys utilizing Mobile Mapping Systems (MMS) offer a more efficient solution. However, existing MMS-acquired tree datasets are limited by small-scale scene, limited annotation, or single modality, restricting their utility for comprehensive analysis. To address these limitations, we introduce WHU-STree, a cross-city, richly annotated, and multi-modal urban street tree dataset. Collected across two distinct cities, WHU-STree integrates synchronized point clouds and high-resolution images, encompassing 21,007 annotated tree instances across 50 species and 2 morphological parameters. Leveraging the unique characteristics, WHU-STree concurrently supports over 10 tasks related to street tree inventory. We benchmark representative baselines for two key tasks--tree species classification and individual tree segmentation. Extensive experiments and in-depth analysis demonstrate the significant potential of multi-modal data fusion and underscore cross-domain applicability as a critical prerequisite for practical algorithm deployment. In particular, we identify key challenges and outline potential future works for fully exploiting WHU-STree, encompassing multi-modal fusion, multi-task collaboration, cross-domain generalization, spatial pattern learning, and Multi-modal Large Language Model for street tree asset management. The WHU-STree dataset is accessible at: https://github.com/WHU-USI3DV/WHU-STree.
HLFormer: Enhancing Partially Relevant Video Retrieval with Hyperbolic Learning
Jul 23, 2025



Partially Relevant Video Retrieval (PRVR) addresses the critical challenge of matching untrimmed videos with text queries describing only partial content. Existing methods suffer from geometric distortion in Euclidean space that sometimes misrepresents the intrinsic hierarchical structure of videos and overlooks certain hierarchical semantics, ultimately leading to suboptimal temporal modeling. To address this issue, we propose the first hyperbolic modeling framework for PRVR, namely HLFormer, which leverages hyperbolic space learning to compensate for the suboptimal hierarchical modeling capabilities of Euclidean space. Specifically, HLFormer integrates the Lorentz Attention Block and Euclidean Attention Block to encode video embeddings in hybrid spaces, using the Mean-Guided Adaptive Interaction Module to dynamically fuse features. Additionally, we introduce a Partial Order Preservation Loss to enforce "text < video" hierarchy through Lorentzian cone constraints. This approach further enhances cross-modal matching by reinforcing partial relevance between video content and text queries. Extensive experiments show that HLFormer outperforms state-of-the-art methods. Code is released at https://github.com/lijun2005/ICCV25-HLFormer.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
Explicitly Guided Information Interaction Network for Cross-modal Point Cloud Completion
Jul 03, 2024



Corresponding author}In this paper, we explore a novel framework, EGIInet (Explicitly Guided Information Interaction Network), a model for View-guided Point cloud Completion (ViPC) task, which aims to restore a complete point cloud from a partial one with a single view image. In comparison with previous methods that relied on the global semantics of input images, EGIInet efficiently combines the information from two modalities by leveraging the geometric nature of the completion task. Specifically, we propose an explicitly guided information interaction strategy supported by modal alignment for point cloud completion. First, in contrast to previous methods which simply use 2D and 3D backbones to encode features respectively, we unified the encoding process to promote modal alignment. Second, we propose a novel explicitly guided information interaction strategy that could help the network identify critical information within images, thus achieving better guidance for completion. Extensive experiments demonstrate the effectiveness of our framework, and we achieved a new state-of-the-art (+16\% CD over XMFnet) in benchmark datasets despite using fewer parameters than the previous methods. The pre-trained model and code and are available at https://github.com/WHU-USI3DV/EGIInet.
VEnvision3D: A Synthetic Perception Dataset for 3D Multi-Task Model Research
Mar 05, 2024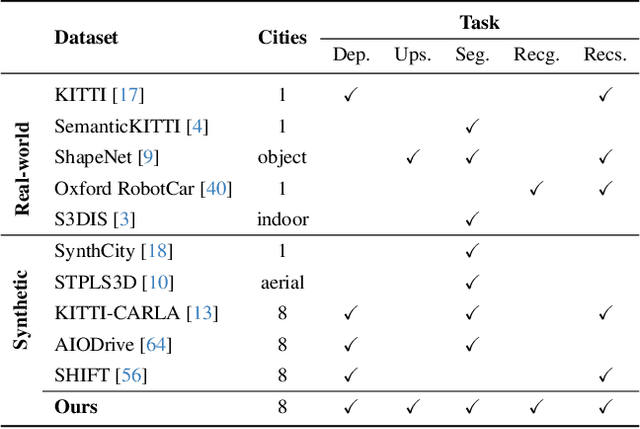


Developing a unified multi-task foundation model has become a critical challenge in computer vision research. In the current field of 3D computer vision, most datasets only focus on single task, which complicates the concurrent training requirements of various downstream tasks. In this paper, we introduce VEnvision3D, a large 3D synthetic perception dataset for multi-task learning, including depth completion, segmentation, upsampling, place recognition, and 3D reconstruction. Since the data for each task is collected in the same environmental domain, sub-tasks are inherently aligned in terms of the utilized data. Therefore, such a unique attribute can assist in exploring the potential for the multi-task model and even the foundation model without separate training methods. Meanwhile, capitalizing on the advantage of virtual environments being freely editable, we implement some novel settings such as simulating temporal changes in the environment and sampling point clouds on model surfaces. These characteristics enable us to present several new benchmarks. We also perform extensive studies on multi-task end-to-end models, revealing new observations, challenges, and opportunities for future research. Our dataset and code will be open-sourced upon acceptance.
SparseDC: Depth Completion from sparse and non-uniform inputs
Nov 30, 2023We propose SparseDC, a model for Depth Completion of Sparse and non-uniform depth inputs. Unlike previous methods focusing on completing fixed distributions on benchmark datasets (e.g., NYU with 500 points, KITTI with 64 lines), SparseDC is specifically designed to handle depth maps with poor quality in real usage. The key contributions of SparseDC are two-fold. First, we design a simple strategy, called SFFM, to improve the robustness under sparse input by explicitly filling the unstable depth features with stable image features. Second, we propose a two-branch feature embedder to predict both the precise local geometry of regions with available depth values and accurate structures in regions with no depth. The key of the embedder is an uncertainty-based fusion module called UFFM to balance the local and long-term information extracted by CNNs and ViTs. Extensive indoor and outdoor experiments demonstrate the robustness of our framework when facing sparse and non-uniform input depths. The pre-trained model and code are available at https://github.com/WHU-USI3DV/SparseDC.
PC2-PU: Patch Correlation and Position Correction for Effective Point Cloud Upsampling
Sep 20, 2021
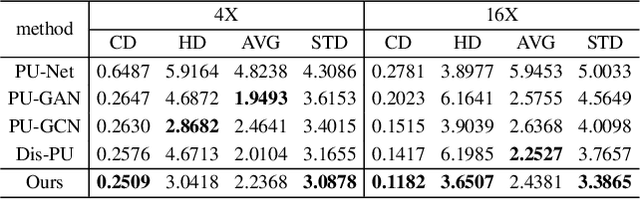

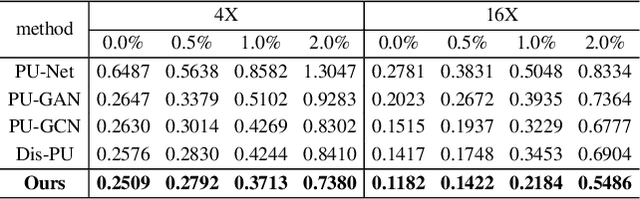
Point cloud upsampling is to densify a sparse point set acquired from 3D sensors, providing a denser representation for underlying surface. However, existing methods perform upsampling on a single patch, ignoring the coherence and relation of the entire surface, thus limiting the upsampled capability. Also, they mainly focus on a clean input, thus the performance is severely compromised when handling scenarios with extra noises. In this paper, we present a novel method for more effective point cloud upsampling, achieving a more robust and improved performance. To this end, we incorporate two thorough considerations. i) Instead of upsampling each small patch independently as previous works, we take adjacent patches as input and introduce a Patch Correlation Unit to explore the shape correspondence between them for effective upsampling. ii)We propose a Position Correction Unit to mitigate the effects of outliers and noisy points. It contains a distance-aware encoder to dynamically adjust the generated points to be close to the underlying surface. Extensive experiments demonstrate that our proposed method surpasses previous upsampling methods on both clean and noisy inputs.
A Dynamic Boosted Ensemble Learning Method Based on Random Forest
Apr 24, 2018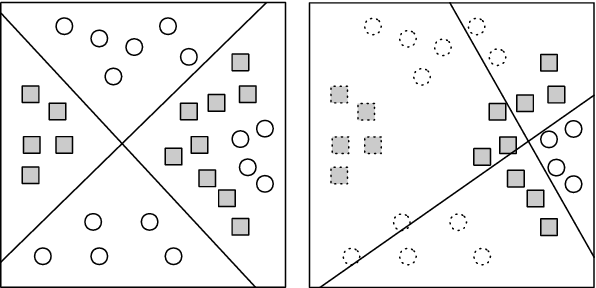
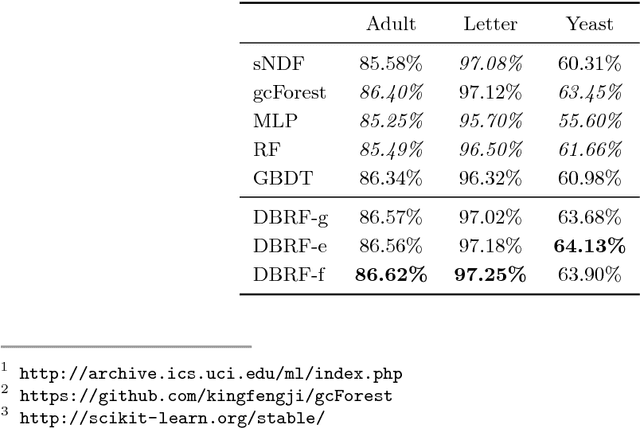
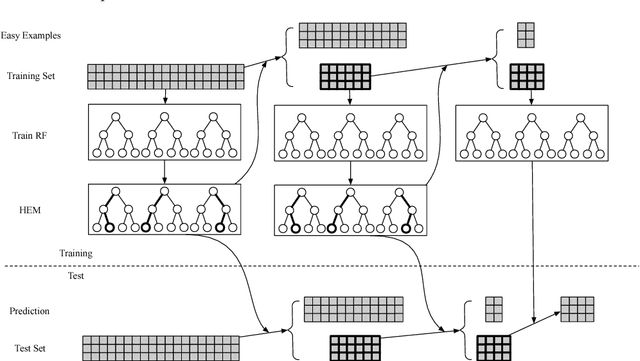
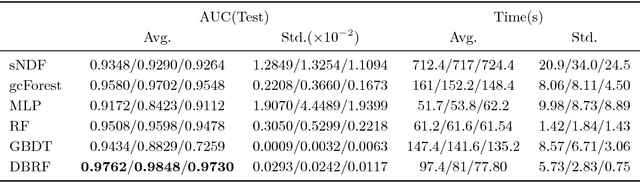
We propose a dynamic boosted ensemble learning method based on random forest (DBRF), a novel ensemble algorithm that incorporates the notion of hard example mining into Random Forest (RF) and thus combines the high accuracy of Boosting algorithm with the strong generalization of Bagging algorithm. Specifically, we propose to measure the quality of each leaf node of every decision tree in the random forest to determine hard examples. By iteratively training and then removing easy examples from training data, we evolve the random forest to focus on hard examples dynamically so as to learn decision boundaries better. Data can be cascaded through these random forests learned in each iteration in sequence to generate predictions, thus making RF deep. We also propose to use evolution mechanism and smart iteration mechanism to improve the performance of the model. DBRF outperforms RF on three UCI datasets and achieved state-of-the-art results compared to other deep models. Moreover, we show that DBRF is also a new way of sampling and can be very useful when learning from imbalanced data.