 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Aware Prototype Learning with Negative Contrast for Test-Time Adaptation of Vision-Language Models
Oct 22, 2025Vision-Language Models (VLMs) demonstrate impressive zero-shot generalization through large-scale image-text pretraining, yet their performance can drop once the deployment distribution diverges from the training distribution. To address this, Test-Time Adaptation (TTA) methods update models using unlabeled target data. However, existing approaches often ignore two key challenges: prototype degradation in long-tailed distributions and confusion between semantically similar classes. To tackle these issues, we propose \textbf{C}lass-Aware \textbf{P}rototype \textbf{L}earning with \textbf{N}egative \textbf{C}ontrast(\textbf{CPL-NC}), a lightweight TTA framework designed specifically for VLMs to enhance generalization under distribution shifts. CPL-NC introduces a \textit{Class-Aware Prototype Cache} Module that dynamically adjusts per-class capacity based on test-time frequency and activation history, with a rejuvenation mechanism for inactive classes to retain rare-category knowledge. Additionally, a \textit{Negative Contrastive Learning} Mechanism identifies and constrains hard visual-textual negatives to improve class separability. The framework employs asymmetric optimization, refining only textual prototypes while anchoring on stable visual features. Experiments on 15 benchmarks show that CPL-NC consistently outperforms prior TTA methods across both ResNet-50 and ViT-B/16 backbones.
StereoCarla: A High-Fidelity Driving Dataset for Generalizable Stereo
Sep 16, 2025Stereo matching plays a crucial role in enabling depth perception for autonomous driving and robotics. While recent years have witnessed remarkable progress in stereo matching algorithms, largely driven by learning-based methods and synthetic datasets, the generalization performance of these models remains constrained by the limited diversity of existing training data. To address these challenges, we present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. We conduct comprehensive cross-domain experiments across four standard evaluation datasets (KITTI2012, KITTI2015, Middlebury, ETH3D) and demonstrate that models trained on StereoCarla outperform those trained on 11 existing stereo datasets in terms of generalization accuracy across multiple benchmarks. Furthermore, when integrated into multi-dataset training, StereoCarla contributes substantial improvements to generalization accuracy, highlighting its compatibility and scalability. This dataset provides a valuable benchmark for developing and evaluating stereo algorithms under realistic, diverse, and controllable settings, facilitating more robust depth perception systems for autonomous vehicles. Code can be available at https://github.com/XiandaGuo/OpenStereo, and data can be available at https://xiandaguo.net/StereoCarla.
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025
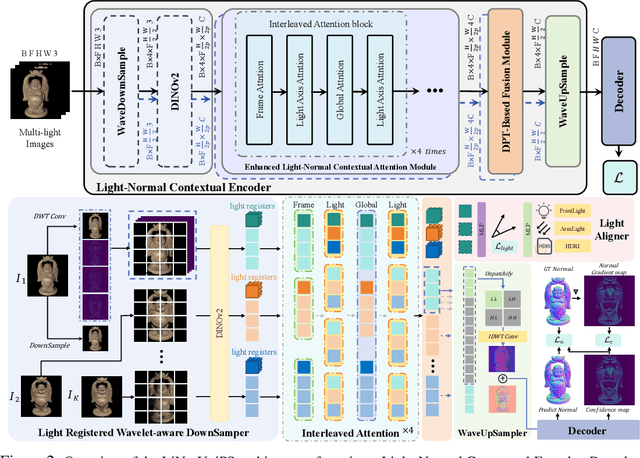
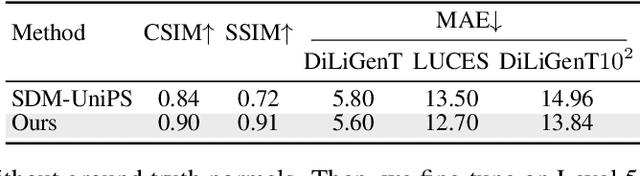

Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
May 26, 2025Research interest in end-to-end autonomous driving has surged owing to its fully differentiable design integrating modular tasks, i.e. perception, prediction and planing, which enables optimization in pursuit of the ultimate goal. Despite the great potential of the end-to-end paradigm, existing methods suffer from several aspects including expensive BEV (bird's eye view) computation, action diversity, and sub-optimal decision in complex real-world scenarios. To address these challenges, we propose a novel hybrid sparse-dense diffusion policy, empowered by a Vision-Language Model (VLM), called Diff-VLA. We explore the sparse diffusion representation for efficient multi-modal driving behavior. Moreover, we rethink the effectiveness of VLM driving decision and improve the trajectory generation guidance through deep interaction across agent, map instances and VLM output. Our method shows superior performance in Autonomous Grand Challenge 2025 which contains challenging real and reactive synthetic scenarios. Our methods achieves 45.0 PDMS.
ThanoRA: Task Heterogeneity-Aware Multi-Task Low-Rank Adaptation
May 24, 2025Low-Rank Adaptation (LoRA) is widely adopted for downstream fine-tuning of foundation models due to its efficiency and zero additional inference cost. Many real-world applications require foundation models to specialize in multiple tasks simultaneously, motivating the need for efficient multi-task adaptation. While recent approaches integrate LoRA with mixture-of-experts (MoE) to address this, the use of routers prevents parameter mergeability, which increases inference overhead and hinders unified multi-task adaptation, thereby limiting deployment practicality. In this work, we propose ThanoRA, a Task Heterogeneity-Aware Multi-Task Low-Rank Adaptation framework that enables multi-task adaptation while preserving the inference efficiency of LoRA. ThanoRA jointly models task heterogeneity and mitigates subspace interference throughout training. Specifically, motivated by inherent differences in complexity and heterogeneity across tasks, ThanoRA constructs task-specific LoRA subspaces at initialization, enabling fine-grained knowledge injection aligned with task heterogeneity. Furthermore, to prevent task interference and subspace collapse during multi-task training, ThanoRA introduces a subspace-preserving regularization that maintains the independence of task-specific representations. With the synergy of both components, ThanoRA enables efficient and unified multi-task adaptation. Extensive experiments across multimodal and text-only benchmarks under varying multi-task mixtures demonstrate that ThanoRA consistently achieves robust and superior performance over strong baselines without introducing additional inference overhead. Our code is publicly available at: https://github.com/LiangJian24/ThanoRA.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
InsightDrive: Insight Scene Representation for End-to-End Autonomous Driving
Mar 17, 2025Directly generating planning results from raw sensors has become increasingly prevalent due to its adaptability and robustness in complex scenarios. Scene representation, as a key module in the pipeline, has traditionally relied on conventional perception, which focus on the global scene. However, in driving scenarios, human drivers typically focus only on regions that directly impact driving, which often coincide with those required for end-to-end autonomous driving. In this paper, a novel end-to-end autonomous driving method called InsightDrive is proposed, which organizes perception by language-guided scene representation. We introduce an instance-centric scene tokenizer that transforms the surrounding environment into map- and object-aware instance tokens. Scene attention language descriptions, which highlight key regions and obstacles affecting the ego vehicle's movement, are generated by a vision-language model that leverages the cognitive reasoning capabilities of foundation models. We then align scene descriptions with visual features using the vision-language model, guiding visual attention through these descriptions to give effectively scene representation. Furthermore, we employ self-attention and cross-attention mechanisms to model the ego-agents and ego-map relationships to comprehensively build the topological relationships of the scene. Finally, based on scene understanding, we jointly perform motion prediction and planning. Extensive experiments on the widely used nuScenes benchmark demonstrate that the proposed InsightDrive achieves state-of-the-art performance in end-to-end autonomous driving. The code is available at https://github.com/songruiqi/InsightDrive
Bidirectional Prototype-Reward co-Evolution for Test-Time Adaptation of Vision-Language Models
Mar 12, 2025Test-time adaptation (TTA) is crucial in maintaining Vision-Language Models (VLMs) performance when facing real-world distribution shifts, particularly when the source data or target labels are inaccessible. Existing TTA methods rely on CLIP's output probability distribution for feature evaluation, which can introduce biases under domain shifts. This misalignment may cause features to be misclassified due to text priors or incorrect textual associations. To address these limitations, we propose Bidirectional Prototype-Reward co-Evolution (BPRE), a novel TTA framework for VLMs that integrates feature quality assessment with prototype evolution through a synergistic feedback loop. BPRE first employs a Multi-Dimensional Quality-Aware Reward Module to evaluate feature quality and guide prototype refinement precisely. The continuous refinement of prototype quality through Prototype-Reward Interactive Evolution will subsequently enhance the computation of more robust Multi-Dimensional Quality-Aware Reward Scores. Through the bidirectional interaction, the precision of rewards and the evolution of prototypes mutually reinforce each other, forming a self-evolving cycle. Extensive experiments are conducted across 15 diverse recognition datasets encompassing natural distribution shifts and cross-dataset generalization scenarios. Results demonstrate that BPRE consistently achieves superior average performance compared to state-of-the-art methods across different model architectures, such as ResNet-50 and ViT-B/16. By emphasizing comprehensive feature evaluation and bidirectional knowledge refinement, BPRE advances VLM generalization capabilities, offering a new perspective on TTA.
Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model
Mar 06, 2025Multi-modal Large Language Models (MLLMs) integrate visual and linguistic reasoning to address complex tasks such as image captioning and visual question answering. While MLLMs demonstrate remarkable versatility, MLLMs appears limited performance on special applications. But tuning MLLMs for downstream tasks encounters two key challenges: Task-Expert Specialization, where distribution shifts between pre-training and target datasets constrain target performance, and Open-World Stabilization, where catastrophic forgetting erases the model general knowledge. In this work, we systematically review recent advancements in MLLM tuning methodologies, classifying them into three paradigms: (I) Selective Tuning, (II) Additive Tuning, and (III) Reparameterization Tuning. Furthermore, we benchmark these tuning strategies across popular MLLM architectures and diverse downstream tasks to establish standardized evaluation analysis and systematic tuning principles. Finally, we highlight several open challenges in this domain and propose future research directions. To facilitate ongoing progress in this rapidly evolving field, we provide a public repository that continuously tracks developments: https://github.com/WenkeHuang/Awesome-MLLM-Tuning.
WMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
Mar 04, 2025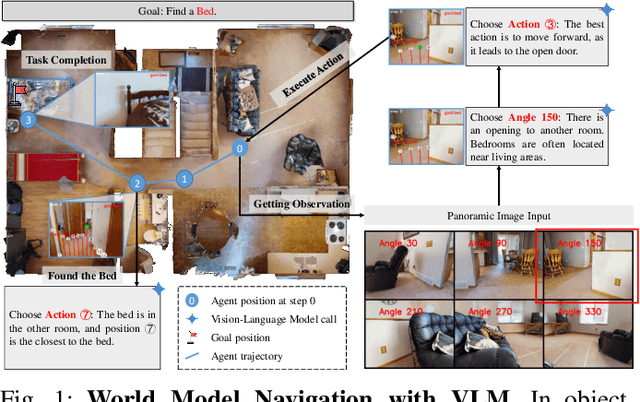
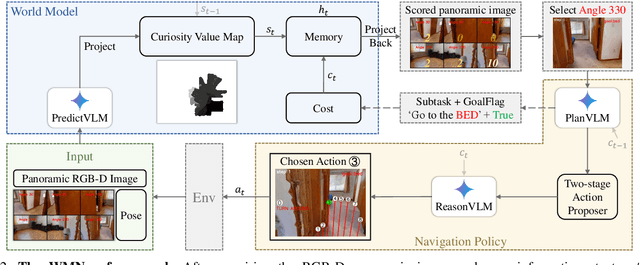
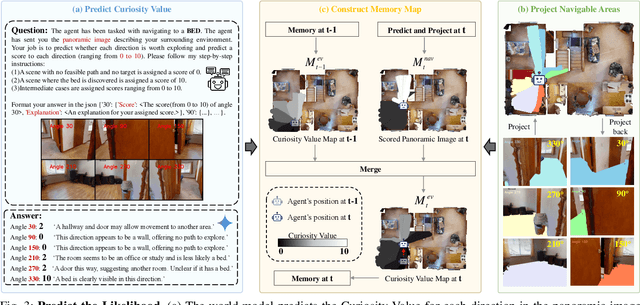

Object Goal Navigation-requiring an agent to locate a specific object in an unseen environment-remains a core challenge in embodied AI. Although recent progress in Vision-Language Model (VLM)-based agents has demonstrated promising perception and decision-making abilities through prompting, none has yet established a fully modular world model design that reduces risky and costly interactions with the environment by predicting the future state of the world. We introduce WMNav, a novel World Model-based Navigation framework powered by Vision-Language Models (VLMs). It predicts possible outcomes of decisions and builds memories to provide feedback to the policy module. To retain the predicted state of the environment, WMNav proposes the online maintained Curiosity Value Map as part of the world model memory to provide dynamic configuration for navigation policy. By decomposing according to a human-like thinking process, WMNav effectively alleviates the impact of model hallucination by making decisions based on the feedback difference between the world model plan and observation. To further boost efficiency, we implement a two-stage action proposer strategy: broad exploration followed by precise localization. Extensive evaluation on HM3D and MP3D validates WMNav surpasses existing zero-shot benchmarks in both success rate and exploration efficiency (absolute improvement: +3.2% SR and +3.2% SPL on HM3D, +13.5% SR and +1.1% SPL on MP3D). Project page: https://b0b8k1ng.github.io/WMNav/.