 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Cross-Modal Prompting for Event-Frame Asymmetric Stereo
Apr 16, 2026Conventional frame-based cameras capture rich contextual information but suffer from limited temporal resolution and motion blur in dynamic scenes. Event cameras offer an alternative visual representation with higher dynamic range free from such limitations. The complementary characteristics of the two modalities make event-frame asymmetric stereo promising for reliable 3D perception under fast motion and challenging illumination. However, the modality gap often leads to marginalization of domain-specific cues essential for cross-modal stereo matching. In this paper, we introduce Bi-CMPStereo, a novel bidirectional cross-modal prompting framework that fully exploits semantic and structural features from both domains for robust matching. Our approach learns finely aligned stereo representations within a target canonical space and integrates complementary representations by projecting each modality into both event and frame domains. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art methods in accuracy and generalization.
EventHub: Data Factory for Generalizable Event-Based Stereo Networks without Active Sensors
Apr 02, 2026We propose EventHub, a novel framework for training deep-event stereo networks without ground truth annotations from costly active sensors, relying instead on standard color images. From these images, we derive either proxy annotations and proxy events through state-of-the-art novel view synthesis techniques, or simply proxy annotations when images are already paired with event data. Using the training set generated by our data factory, we repurpose state-of-the-art stereo models from RGB literature to process event data, obtaining new event stereo models with unprecedented generalization capabilities. Experiments on widely used event stereo datasets support the effectiveness of EventHub and show how the same data distillation mechanism can improve the accuracy of RGB stereo foundation models in challenging conditions such as nighttime scenes.
FlowIt: Global Matching for Optical Flow with Confidence-Guided Refinement
Mar 30, 2026We present FlowIt, a novel architecture for optical flow estimation designed to robustly handle large pixel displacements. At its core, FlowIt leverages a hierarchical transformer architecture that captures extensive global context, enabling the model to effectively model long-range correspondences. To overcome the limitations of localized matching, we formulate the flow initialization as an optimal transport problem. This formulation yields a highly robust initial flow field, alongside explicitly derived occlusion and confidence maps. These cues are then seamlessly integrated into a guided refinement stage, where the network actively propagates reliable motion estimates from high-confidence regions into ambiguous, low-confidence areas. Extensive experiments across the Sintel, KITTI, Spring, and LayeredFlow datasets validate the efficacy of our approach. FlowIt achieves state-of-the-art results on the competitive Sintel and KITTI benchmarks, while simultaneously establishing new state-of-the-art cross-dataset zero-shot generalization performance on Sintel, Spring, and LayeredFlow.
FoundationSLAM: Unleashing the Power of Depth Foundation Models for End-to-End Dense Visual SLAM
Dec 31, 2025We present FoundationSLAM, a learning-based monocular dense SLAM system that addresses the absence of geometric consistency in previous flow-based approaches for accurate and robust tracking and mapping. Our core idea is to bridge flow estimation with geometric reasoning by leveraging the guidance from foundation depth models. To this end, we first develop a Hybrid Flow Network that produces geometry-aware correspondences, enabling consistent depth and pose inference across diverse keyframes. To enforce global consistency, we propose a Bi-Consistent Bundle Adjustment Layer that jointly optimizes keyframe pose and depth under multi-view constraints. Furthermore, we introduce a Reliability-Aware Refinement mechanism that dynamically adapts the flow update process by distinguishing between reliable and uncertain regions, forming a closed feedback loop between matching and optimization. Extensive experiments demonstrate that FoundationSLAM achieves superior trajectory accuracy and dense reconstruction quality across multiple challenging datasets, while running in real-time at 18 FPS, demonstrating strong generalization to various scenarios and practical applicability of our method.
StereoSpace: Depth-Free Synthesis of Stereo Geometry via End-to-End Diffusion in a Canonical Space
Dec 11, 2025We introduce StereoSpace, a diffusion-based framework for monocular-to-stereo synthesis that models geometry purely through viewpoint conditioning, without explicit depth or warping. A canonical rectified space and the conditioning guide the generator to infer correspondences and fill disocclusions end-to-end. To ensure fair and leakage-free evaluation, we introduce an end-to-end protocol that excludes any ground truth or proxy geometry estimates at test time. The protocol emphasizes metrics reflecting downstream relevance: iSQoE for perceptual comfort and MEt3R for geometric consistency. StereoSpace surpasses other methods from the warp & inpaint, latent-warping, and warped-conditioning categories, achieving sharp parallax and strong robustness on layered and non-Lambertian scenes. This establishes viewpoint-conditioned diffusion as a scalable, depth-free solution for stereo generation.
Lost in Translation? Vocabulary Alignment for Source-Free Domain Adaptation in Open-Vocabulary Semantic Segmentation
Sep 18, 2025



We introduce VocAlign, a novel source-free domain adaptation framework specifically designed for VLMs in open-vocabulary semantic segmentation. Our method adopts a student-teacher paradigm enhanced with a vocabulary alignment strategy, which improves pseudo-label generation by incorporating additional class concepts. To ensure efficiency, we use Low-Rank Adaptation (LoRA) to fine-tune the model, preserving its original capabilities while minimizing computational overhead. In addition, we propose a Top-K class selection mechanism for the student model, which significantly reduces memory requirements while further improving adaptation performance. Our approach achieves a notable 6.11 mIoU improvement on the CityScapes dataset and demonstrates superior performance on zero-shot segmentation benchmarks, setting a new standard for source-free adaptation in the open-vocabulary setting.
Depth AnyEvent: A Cross-Modal Distillation Paradigm for Event-Based Monocular Depth Estimation
Sep 18, 2025Event cameras capture sparse, high-temporal-resolution visual information, making them particularly suitable for challenging environments with high-speed motion and strongly varying lighting conditions. However, the lack of large datasets with dense ground-truth depth annotations hinders learning-based monocular depth estimation from event data. To address this limitation, we propose a cross-modal distillation paradigm to generate dense proxy labels leveraging a Vision Foundation Model (VFM). Our strategy requires an event stream spatially aligned with RGB frames, a simple setup even available off-the-shelf, and exploits the robustness of large-scale VFMs. Additionally, we propose to adapt VFMs, either a vanilla one like Depth Anything v2 (DAv2), or deriving from it a novel recurrent architecture to infer depth from monocular event cameras. We evaluate our approach with synthetic and real-world datasets, demonstrating that i) our cross-modal paradigm achieves competitive performance compared to fully supervised methods without requiring expensive depth annotations, and ii) our VFM-based models achieve state-of-the-art performance.
StereoCarla: A High-Fidelity Driving Dataset for Generalizable Stereo
Sep 16, 2025Stereo matching plays a crucial role in enabling depth perception for autonomous driving and robotics. While recent years have witnessed remarkable progress in stereo matching algorithms, largely driven by learning-based methods and synthetic datasets, the generalization performance of these models remains constrained by the limited diversity of existing training data. To address these challenges, we present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. We conduct comprehensive cross-domain experiments across four standard evaluation datasets (KITTI2012, KITTI2015, Middlebury, ETH3D) and demonstrate that models trained on StereoCarla outperform those trained on 11 existing stereo datasets in terms of generalization accuracy across multiple benchmarks. Furthermore, when integrated into multi-dataset training, StereoCarla contributes substantial improvements to generalization accuracy, highlighting its compatibility and scalability. This dataset provides a valuable benchmark for developing and evaluating stereo algorithms under realistic, diverse, and controllable settings, facilitating more robust depth perception systems for autonomous vehicles. Code can be available at https://github.com/XiandaGuo/OpenStereo, and data can be available at https://xiandaguo.net/StereoCarla.
FlowSeek: Optical Flow Made Easier with Depth Foundation Models and Motion Bases
Sep 05, 2025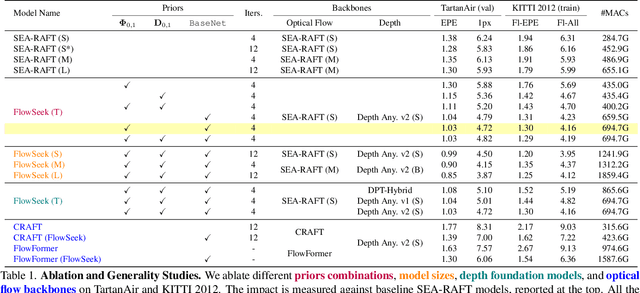
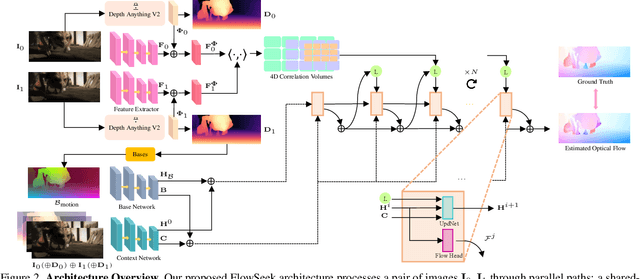
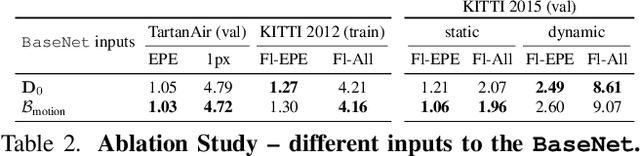
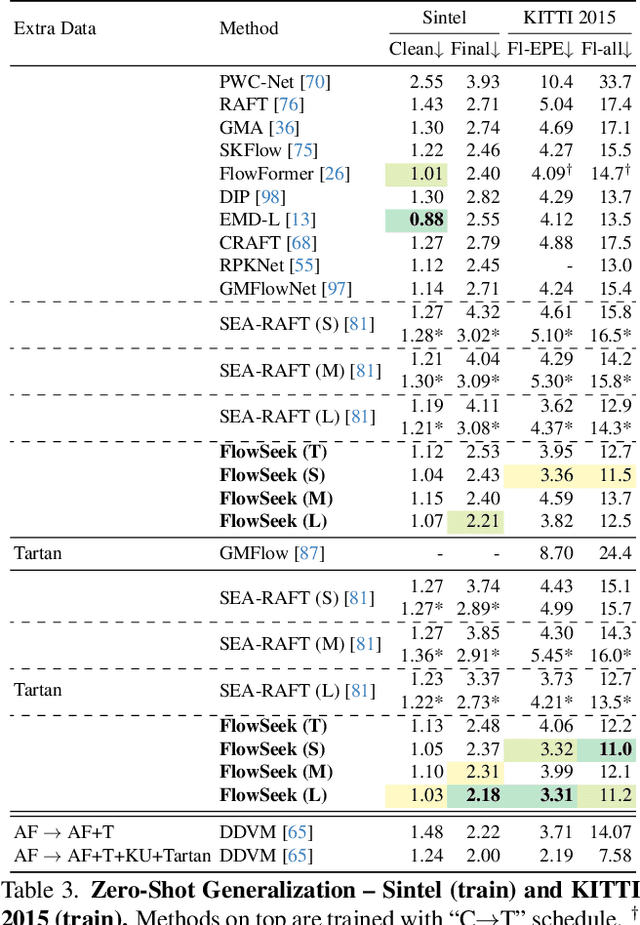
We present FlowSeek, a novel framework for optical flow requiring minimal hardware resources for training. FlowSeek marries the latest advances on the design space of optical flow networks with cutting-edge single-image depth foundation models and classical low-dimensional motion parametrization, implementing a compact, yet accurate architecture. FlowSeek is trained on a single consumer-grade GPU, a hardware budget about 8x lower compared to most recent methods, and still achieves superior cross-dataset generalization on Sintel Final and KITTI, with a relative improvement of 10 and 15% over the previous state-of-the-art SEA-RAFT, as well as on Spring and LayeredFlow datasets.
Stereo 3D Gaussian Splatting SLAM for Outdoor Urban Scenes
Jul 31, 20253D Gaussian Splatting (3DGS) has recently gained popularity in SLAM applications due to its fast rendering and high-fidelity representation. However, existing 3DGS-SLAM systems have predominantly focused on indoor environments and relied on active depth sensors, leaving a gap for large-scale outdoor applications. We present BGS-SLAM, the first binocular 3D Gaussian Splatting SLAM system designed for outdoor scenarios. Our approach uses only RGB stereo pairs without requiring LiDAR or active sensors. BGS-SLAM leverages depth estimates from pre-trained deep stereo networks to guide 3D Gaussian optimization with a multi-loss strategy enhancing both geometric consistency and visual quality. Experiments on multiple datasets demonstrate that BGS-SLAM achieves superior tracking accuracy and mapping performance compared to other 3DGS-based solutions in complex outdoor environments.