 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Trajectory Aligning Cross-view Optimisation
May 05, 2026Cross-View Geo-localisation (CVGL) matches ground imagery against satellite tiles to give absolute position fixes, an alternative to GNSS where signals are occluded, jammed, or spoofed. Recent fine-grained CVGL methods regress sub-tile metric pose, but have only been evaluated as one-shot localisers, never as the primary fix in a live pipeline. Inertial sensing provides high-rate relative motion, but accumulates unbounded drift without an absolute anchor. We propose TACO, a tightly-coupled IMU + fine-grained CVGL pipeline that consumes a single GNSS reading at start-up and thereafter operates on onboard sensing alone. A closed-form cross-track error model triggers CVGL before IMU drift exceeds the matcher's capture radius, and a forward-biased five-point multi-crop search keeps inference cost fixed at five forward passes per fix. A yaw-residual gate rejects fixes that disagree with the onboard compass, and an anisotropic body-frame noise model scales each Unscented Kalman Filter update by per-fix confidence. A factor graph with vetted loop closures provides an offline smoothed trajectory. On the KITTI raw dataset, TACO reduces median Absolute Trajectory Error (ATE) from 97.0m (IMU-only) to 16.3m, a 5.9 times reduction, at <0.1 ms per-frame fusion cost and a 5-10% camera duty cycle. Code is available: github.com/tavisshore/TACO.
Sequences as Nodes for Contrastive Multimodal Graph Recommendation
Feb 06, 2026To tackle cold-start and data sparsity issues in recommender systems, numerous multimodal, sequential, and contrastive techniques have been proposed. While these augmentations can boost recommendation performance, they tend to add noise and disrupt useful semantics. To address this, we propose MuSICRec (Multimodal Sequence-Item Contrastive Recommender), a multi-view graph-based recommender that combines collaborative, sequential, and multimodal signals. We build a sequence-item (SI) view by attention pooling over the user's interacted items to form sequence nodes. We propagate over the SI graph, obtaining a second view organically as an alternative to artificial data augmentation, while simultaneously injecting sequential context signals. Additionally, to mitigate modality noise and align the multimodal information, the contribution of text and visual features is modulated according to an ID-guided gate. We evaluate under a strict leave-two-out split against a broad range of sequential, multimodal, and contrastive baselines. On the Amazon Baby, Sports, and Electronics datasets, MuSICRec outperforms state-of-the-art baselines across all model types. We observe the largest gains for short-history users, mitigating sparsity and cold-start challenges. Our code is available at https://anonymous.4open.science/r/MuSICRec-3CEE/ and will be made publicly available.
Multimodal Enhancement of Sequential Recommendation
Feb 06, 2026We propose a novel recommender framework, MuSTRec (Multimodal and Sequential Transformer-based Recommendation), that unifies multimodal and sequential recommendation paradigms. MuSTRec captures cross-item similarities and collaborative filtering signals, by building item-item graphs from extracted text and visual features. A frequency-based self-attention module additionally captures the short- and long-term user preferences. Across multiple Amazon datasets, MuSTRec demonstrates superior performance (up to 33.5% improvement) over multimodal and sequential state-of-the-art baselines. Finally, we detail some interesting facets of this new recommendation paradigm. These include the need for a new data partitioning regime, and a demonstration of how integrating user embeddings into sequential recommendation leads to drastically increased short-term metrics (up to 200% improvement) on smaller datasets. Our code is availabe at https://anonymous.4open.science/r/MuSTRec-D32B/ and will be made publicly available.
DSL: Understanding and Improving Softmax Recommender Systems with Competition-Aware Scaling
Feb 06, 2026Softmax Loss (SL) is being increasingly adopted for recommender systems (RS) as it has demonstrated better performance, robustness and fairness. Yet in implicit-feedback, a single global temperature and equal treatment of uniformly sampled negatives can lead to brittle training, because sampled sets may contain varying degrees of relevant or informative competitors. The optimal loss sharpness for a user-item pair with a particular set of negatives, can be suboptimal or destabilising for another with different negatives. We introduce Dual-scale Softmax Loss (DSL), which infers effective sharpness from the sampled competition itself. DSL adds two complementary branches to the log-sum-exp backbone. Firstly it reweights negatives within each training instance using hardness and item--item similarity, secondly it adapts a per-example temperature from the competition intensity over a constructed competitor slate. Together, these components preserve the geometry of SL while reshaping the competition distribution across negatives and across examples. Over several representative benchmarks and backbones, DSL yields substantial gains over strong baselines, with improvements over SL exceeding $10%$ in several settings and averaging $6.22%$ across datasets, metrics, and backbones. Under out-of-distribution (OOD) popularity shift, the gains are larger, with an average of $9.31%$ improvement over SL. We further provide a theoretical, distributionally robust optimisation (DRO) analysis, which demonstrates how DSL reshapes the robust payoff and the KL deviation for ambiguous instances. This helps explain the empirically observed improvements in accuracy and robustness.
Deep Leakage with Generative Flow Matching Denoiser
Jan 21, 2026Federated Learning (FL) has emerged as a powerful paradigm for decentralized model training, yet it remains vulnerable to deep leakage (DL) attacks that reconstruct private client data from shared model updates. While prior DL methods have demonstrated varying levels of success, they often suffer from instability, limited fidelity, or poor robustness under realistic FL settings. We introduce a new DL attack that integrates a generative Flow Matching (FM) prior into the reconstruction process. By guiding optimization toward the distribution of realistic images (represented by a flow matching foundation model), our method enhances reconstruction fidelity without requiring knowledge of the private data. Extensive experiments on multiple datasets and target models demonstrate that our approach consistently outperforms state-of-the-art attacks across pixel-level, perceptual, and feature-based similarity metrics. Crucially, the method remains effective across different training epochs, larger client batch sizes, and under common defenses such as noise injection, clipping, and sparsification. Our findings call for the development of new defense strategies that explicitly account for adversaries equipped with powerful generative priors.
SpooFL: Spoofing Federated Learning
Jan 21, 2026Traditional defenses against Deep Leakage (DL) attacks in Federated Learning (FL) primarily focus on obfuscation, introducing noise, transformations or encryption to degrade an attacker's ability to reconstruct private data. While effective to some extent, these methods often still leak high-level information such as class distributions or feature representations, and are frequently broken by increasingly powerful denoising attacks. We propose a fundamentally different perspective on FL defense: framing it as a spoofing problem.We introduce SpooFL (Figure 1), a spoofing-based defense that deceives attackers into believing they have recovered the true training data, while actually providing convincing but entirely synthetic samples from an unrelated task. Unlike prior synthetic-data defenses that share classes or distributions with the private data and thus still leak semantic information, SpooFL uses a state-of-the-art generative model trained on an external dataset with no class overlap. As a result, attackers are misled into recovering plausible yet completely irrelevant samples, preventing meaningful data leakage while preserving FL training integrity. We implement the first example of such a spoofing defense, and evaluate our method against state-of-the-art DL defenses and demonstrate that it successfully misdirects attackers without compromising model performance significantly.
FeatureSLAM: Feature-enriched 3D gaussian splatting SLAM in real time
Jan 09, 2026We present a real-time tracking SLAM system that unifies efficient camera tracking with photorealistic feature-enriched mapping using 3D Gaussian Splatting (3DGS). Our main contribution is integrating dense feature rasterization into the novel-view synthesis, aligned with a visual foundation model. This yields strong semantics, going beyond basic RGB-D input, aiding both tracking and mapping accuracy. Unlike previous semantic SLAM approaches (which embed pre-defined class labels) FeatureSLAM enables entirely new downstream tasks via free-viewpoint, open-set segmentation. Across standard benchmarks, our method achieves real-time tracking, on par with state-of-the-art systems while improving tracking stability and map fidelity without prohibitive compute. Quantitatively, we obtain 9\% lower pose error and 8\% higher mapping accuracy compared to recent fixed-set SLAM baselines. Our results confirm that real-time feature-embedded SLAM, is not only valuable for enabling new downstream applications. It also improves the performance of the underlying tracking and mapping subsystems, providing semantic and language masking results that are on-par with offline 3DGS models, alongside state-of-the-art tracking, depth and RGB rendering.
FlowDet: Unifying Object Detection and Generative Transport Flows
Dec 18, 2025



We present FlowDet, the first formulation of object detection using modern Conditional Flow Matching techniques. This work follows from DiffusionDet, which originally framed detection as a generative denoising problem in the bounding box space via diffusion. We revisit and generalise this formulation to a broader class of generative transport problems, while maintaining the ability to vary the number of boxes and inference steps without re-training. In contrast to the curved stochastic transport paths induced by diffusion, FlowDet learns simpler and straighter paths resulting in faster scaling of detection performance as the number of inference steps grows. We find that this reformulation enables us to outperform diffusion based detection systems (as well as non-generative baselines) across a wide range of experiments, including various precision/recall operating points using multiple feature backbones and datasets. In particular, when evaluating under recall-constrained settings, we can highlight the effects of the generative transport without over-compensating with large numbers of proposals. This provides gains of up to +3.6% AP and +4.2% AP$_{rare}$ over DiffusionDet on the COCO and LVIS datasets, respectively.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description
Mar 31, 2025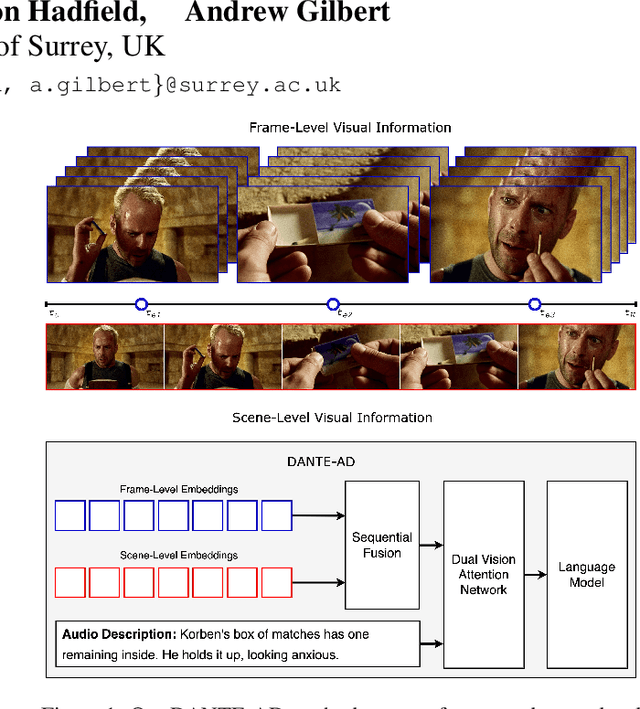
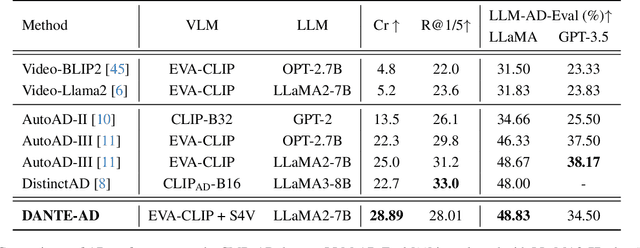
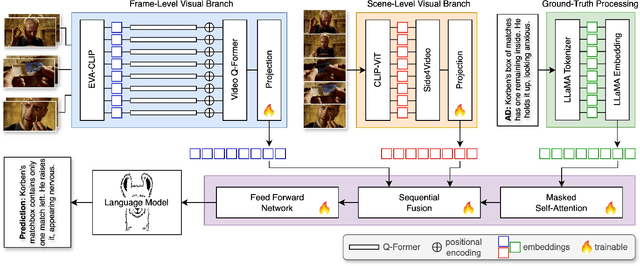
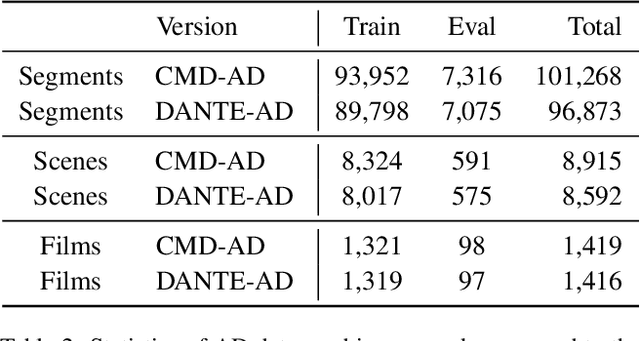
Audio Description is a narrated commentary designed to aid vision-impaired audiences in perceiving key visual elements in a video. While short-form video understanding has advanced rapidly, a solution for maintaining coherent long-term visual storytelling remains unresolved. Existing methods rely solely on frame-level embeddings, effectively describing object-based content but lacking contextual information across scenes. We introduce DANTE-AD, an enhanced video description model leveraging a dual-vision Transformer-based architecture to address this gap. DANTE-AD sequentially fuses both frame and scene level embeddings to improve long-term contextual understanding. We propose a novel, state-of-the-art method for sequential cross-attention to achieve contextual grounding for fine-grained audio description generation. Evaluated on a broad range of key scenes from well-known movie clips, DANTE-AD outperforms existing methods across traditional NLP metrics and LLM-based evaluations.