 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenDetNet: Weakly-supervised Shadow Detection with Shadow Caster Verification
Aug 30, 2024

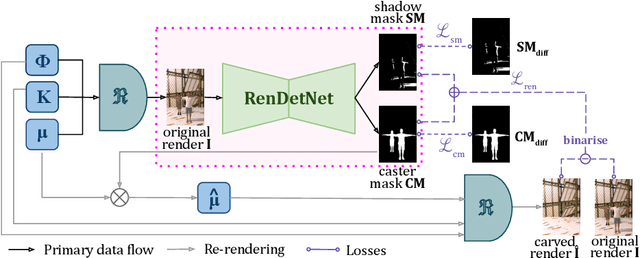

Existing shadow detection models struggle to differentiate dark image areas from shadows. In this paper, we tackle this issue by verifying that all detected shadows are real, i.e. they have paired shadow casters. We perform this step in a physically-accurate manner by differentiably re-rendering the scene and observing the changes stemming from carving out estimated shadow casters. Thanks to this approach, the RenDetNet proposed in this paper is the first learning-based shadow detection model whose supervisory signals can be computed in a self-supervised manner. The developed system compares favourably against recent models trained on our data. As part of this publication, we release our code on github.
S3R-Net: A Single-Stage Approach to Self-Supervised Shadow Removal
Apr 18, 2024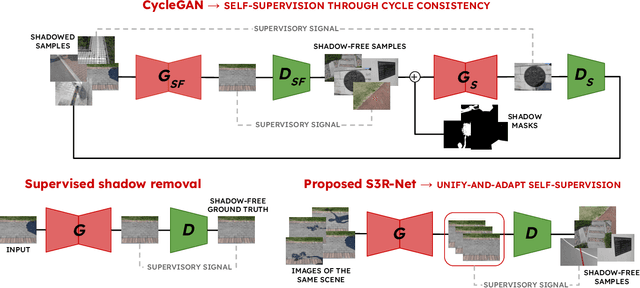
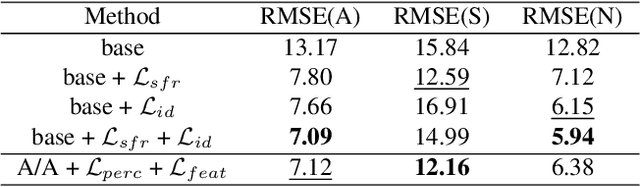
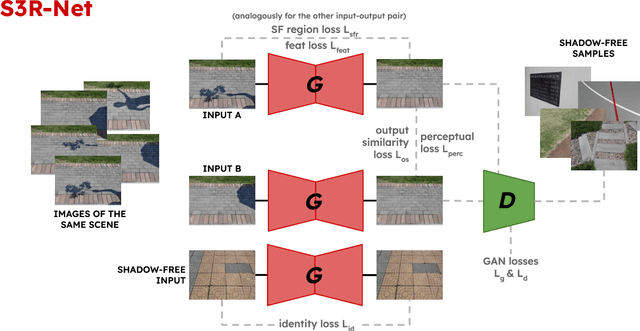
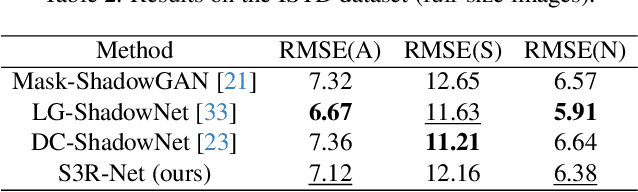
In this paper we present S3R-Net, the Self-Supervised Shadow Removal Network. The two-branch WGAN model achieves self-supervision relying on the unify-and-adaptphenomenon - it unifies the style of the output data and infers its characteristics from a database of unaligned shadow-free reference images. This approach stands in contrast to the large body of supervised frameworks. S3R-Net also differentiates itself from the few existing self-supervised models operating in a cycle-consistent manner, as it is a non-cyclic, unidirectional solution. The proposed framework achieves comparable numerical scores to recent selfsupervised shadow removal models while exhibiting superior qualitative performance and keeping the computational cost low.
SILT: Self-supervised Lighting Transfer Using Implicit Image Decomposition
Oct 25, 2021
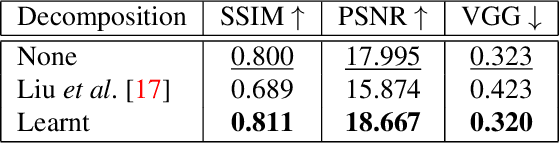
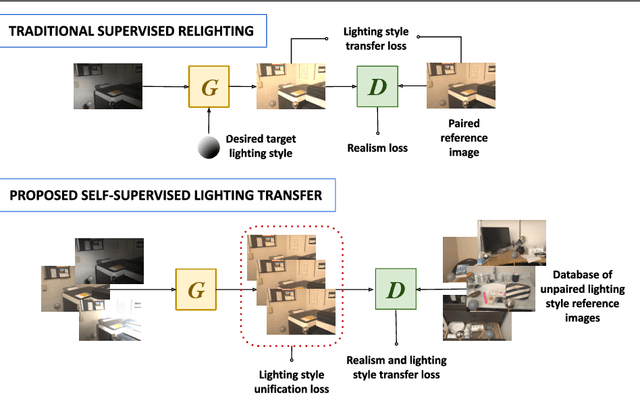
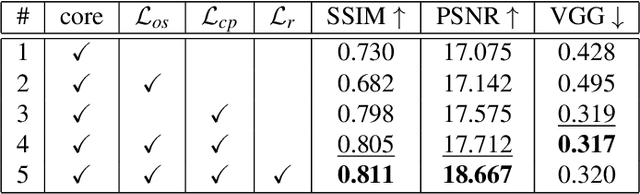
We present SILT, a Self-supervised Implicit Lighting Transfer method. Unlike previous research on scene relighting, we do not seek to apply arbitrary new lighting configurations to a given scene. Instead, we wish to transfer the lighting style from a database of other scenes, to provide a uniform lighting style regardless of the input. The solution operates as a two-branch network that first aims to map input images of any arbitrary lighting style to a unified domain, with extra guidance achieved through implicit image decomposition. We then remap this unified input domain using a discriminator that is presented with the generated outputs and the style reference, i.e. images of the desired illumination conditions. Our method is shown to outperform supervised relighting solutions across two different datasets without requiring lighting supervision.
TACTIC: Joint Rate-Distortion-Accuracy Optimisation for Low Bitrate Compression
Sep 22, 2021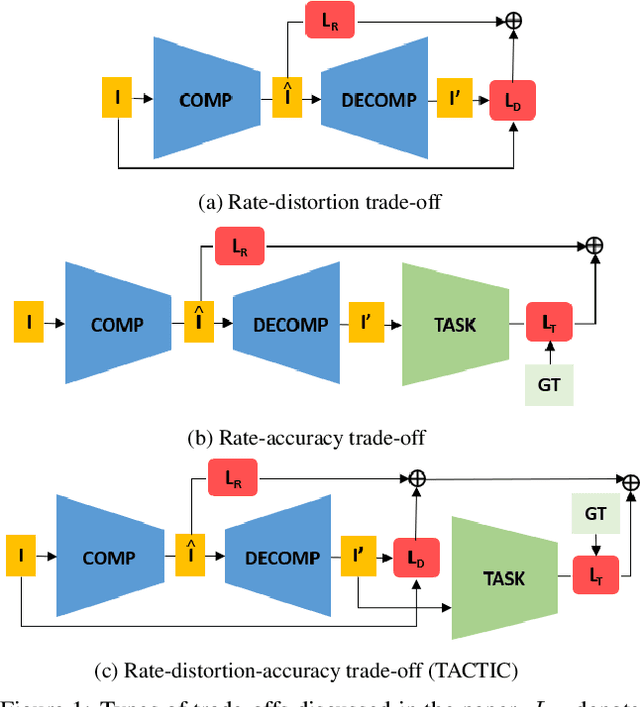

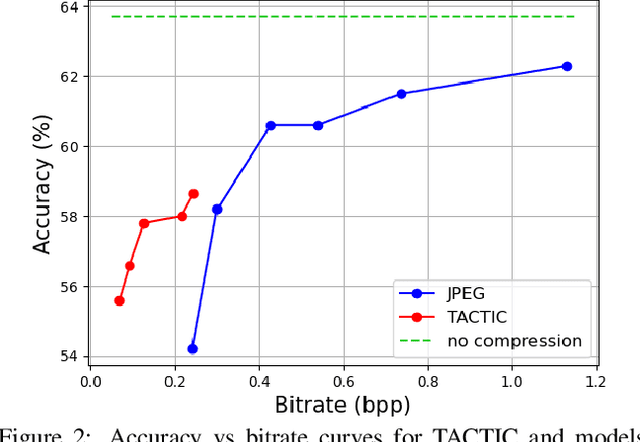

We present TACTIC: Task-Aware Compression Through Intelligent Coding. Our lossy compression model learns based on the rate-distortion-accuracy trade-off for a specific task. By considering what information is important for the follow-on problem, the system trades off visual fidelity for good task performance at a low bitrate. When compared against JPEG at the same bitrate, our approach is able to improve the accuracy of ImageNet subset classification by 4.5%. We also demonstrate the applicability of our approach to other problems, providing a 3.4% accuracy and 4.9% mean IoU improvements in performance over task-agnostic compression for semantic segmentation.