 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3T: Discrete Multi-Modal Motion Tokens for Sign Language Production
Mar 24, 2026Sign language production requires more than hand motion generation. Non-manual features, including mouthings, eyebrow raises, gaze, and head movements, are grammatically obligatory and cannot be recovered from manual articulators alone. Existing 3D production systems face two barriers to integrating them: the standard body model provides a facial space too low-dimensional to encode these articulations, and when richer representations are adopted, standard discrete tokenization suffers from codebook collapse, leaving most of the expression space unreachable. We propose SMPL-FX, which couples FLAME's rich expression space with the SMPL-X body, and tokenize the resulting representation with modality-specific Finite Scalar Quantization VAEs for body, hands, and face. M3T is an autoregressive transformer trained on this multi-modal motion vocabulary, with an auxiliary translation objective that encourages semantically grounded embeddings. Across three standard benchmarks (How2Sign, CSL-Daily, Phoenix14T) M3T achieves state-of-the-art sign language production quality, and on NMFs-CSL, where signs are distinguishable only by non-manual features, reaches 58.3% accuracy against 49.0% for the strongest comparable pose baseline.
SignAgent: Agentic LLMs for Linguistically-Grounded Sign Language Annotation and Dataset Curation
Mar 19, 2026This paper introduces SignAgent, a novel agentic framework that utilises Large Language Models (LLMs) for scalable, linguistically-grounded Sign Language (SL) annotation and dataset curation. Traditional computational methods for SLs often operate at the gloss level, overlooking crucial linguistic nuances, while manual linguistic annotation remains a significant bottleneck, proving too slow and expensive for the creation of large-scale, phonologically-aware datasets. SignAgent addresses these challenges through SignAgent Orchestrator, a reasoning LLM that coordinates a suite of linguistic tools, and SignGraph, a knowledge-grounded LLM that provides lexical and linguistic grounding. We evaluate our framework on two downstream annotation tasks. First, on Pseudo-gloss Annotation, where the agent performs constrained assignment, using multi-modal evidence to extract and order suitable gloss labels for signed sequences. Second, on ID Glossing, where the agent detects and refines visual clusters by reasoning over both visual similarity and phonological overlap to correctly identify and group lexical sign variants. Our results demonstrate that our agentic approach achieves strong performance for large-scale, linguistically-aware data annotation and curation.
SignSparK: Efficient Multilingual Sign Language Production via Sparse Keyframe Learning
Mar 12, 2026Generating natural and linguistically accurate sign language avatars remains a formidable challenge. Current Sign Language Production (SLP) frameworks face a stark trade-off: direct text-to-pose models suffer from regression-to-the-mean effects, while dictionary-retrieval methods produce robotic, disjointed transitions. To resolve this, we propose a novel training paradigm that leverages sparse keyframes to capture the true underlying kinematic distribution of human signing. By predicting dense motion from these discrete anchors, our approach mitigates regression-to-the-mean while ensuring fluid articulation. To realize this paradigm at scale, we first introduce FAST, an ultra-efficient sign segmentation model that automatically mines precise temporal boundaries. We then present SignSparK, a large-scale Conditional Flow Matching (CFM) framework that utilizes these extracted anchors to synthesize 3D signing sequences in SMPL-X and MANO spaces. This keyframe-driven formulation also uniquely unlocks Keyframe-to-Pose (KF2P) generation, making precise spatiotemporal editing of signing sequences possible. Furthermore, our adopted reconstruction-based CFM objective also enables high-fidelity synthesis in fewer than ten sampling steps; this allows SignSparK to scale across four distinct sign languages, establishing the largest multilingual SLP framework to date. Finally, by integrating 3D Gaussian Splatting for photorealistic rendering, we demonstrate through extensive evaluation that SignSparK establishes a new state-of-the-art across diverse SLP tasks and multilingual benchmarks.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Beyond Gloss: A Hand-Centric Framework for Gloss-Free Sign Language Translation
Jul 31, 2025Sign Language Translation (SLT) is a challenging task that requires bridging the modality gap between visual and linguistic information while capturing subtle variations in hand shapes and movements. To address these challenges, we introduce \textbf{BeyondGloss}, a novel gloss-free SLT framework that leverages the spatio-temporal reasoning capabilities of Video Large Language Models (VideoLLMs). Since existing VideoLLMs struggle to model long videos in detail, we propose a novel approach to generate fine-grained, temporally-aware textual descriptions of hand motion. A contrastive alignment module aligns these descriptions with video features during pre-training, encouraging the model to focus on hand-centric temporal dynamics and distinguish signs more effectively. To further enrich hand-specific representations, we distill fine-grained features from HaMeR. Additionally, we apply a contrastive loss between sign video representations and target language embeddings to reduce the modality gap in pre-training. \textbf{BeyondGloss} achieves state-of-the-art performance on the Phoenix14T and CSL-Daily benchmarks, demonstrating the effectiveness of the proposed framework. We will release the code upon acceptance of the paper.
Hierarchical Feature Alignment for Gloss-Free Sign Language Translation
Jul 09, 2025Sign Language Translation (SLT) attempts to convert sign language videos into spoken sentences. However, many existing methods struggle with the disparity between visual and textual representations during end-to-end learning. Gloss-based approaches help to bridge this gap by leveraging structured linguistic information. While, gloss-free methods offer greater flexibility and remove the burden of annotation, they require effective alignment strategies. Recent advances in Large Language Models (LLMs) have enabled gloss-free SLT by generating text-like representations from sign videos. In this work, we introduce a novel hierarchical pre-training strategy inspired by the structure of sign language, incorporating pseudo-glosses and contrastive video-language alignment. Our method hierarchically extracts features at frame, segment, and video levels, aligning them with pseudo-glosses and the spoken sentence to enhance translation quality. Experiments demonstrate that our approach improves BLEU-4 and ROUGE scores while maintaining efficiency.
VisualSpeaker: Visually-Guided 3D Avatar Lip Synthesis
Jul 08, 2025



Realistic, high-fidelity 3D facial animations are crucial for expressive avatar systems in human-computer interaction and accessibility. Although prior methods show promising quality, their reliance on the mesh domain limits their ability to fully leverage the rapid visual innovations seen in 2D computer vision and graphics. We propose VisualSpeaker, a novel method that bridges this gap using photorealistic differentiable rendering, supervised by visual speech recognition, for improved 3D facial animation. Our contribution is a perceptual lip-reading loss, derived by passing photorealistic 3D Gaussian Splatting avatar renders through a pre-trained Visual Automatic Speech Recognition model during training. Evaluation on the MEAD dataset demonstrates that VisualSpeaker improves both the standard Lip Vertex Error metric by 56.1% and the perceptual quality of the generated animations, while retaining the controllability of mesh-driven animation. This perceptual focus naturally supports accurate mouthings, essential cues that disambiguate similar manual signs in sign language avatars.
Using Sign Language Production as Data Augmentation to enhance Sign Language Translation
Jun 11, 2025



Machine learning models fundamentally rely on large quantities of high-quality data. Collecting the necessary data for these models can be challenging due to cost, scarcity, and privacy restrictions. Signed languages are visual languages used by the deaf community and are considered low-resource languages. Sign language datasets are often orders of magnitude smaller than their spoken language counterparts. Sign Language Production is the task of generating sign language videos from spoken language sentences, while Sign Language Translation is the reverse translation task. Here, we propose leveraging recent advancements in Sign Language Production to augment existing sign language datasets and enhance the performance of Sign Language Translation models. For this, we utilize three techniques: a skeleton-based approach to production, sign stitching, and two photo-realistic generative models, SignGAN and SignSplat. We evaluate the effectiveness of these techniques in enhancing the performance of Sign Language Translation models by generating variation in the signer's appearance and the motion of the skeletal data. Our results demonstrate that the proposed methods can effectively augment existing datasets and enhance the performance of Sign Language Translation models by up to 19%, paving the way for more robust and accurate Sign Language Translation systems, even in resource-constrained environments.
HuGeDiff: 3D Human Generation via Diffusion with Gaussian Splatting
Jun 04, 2025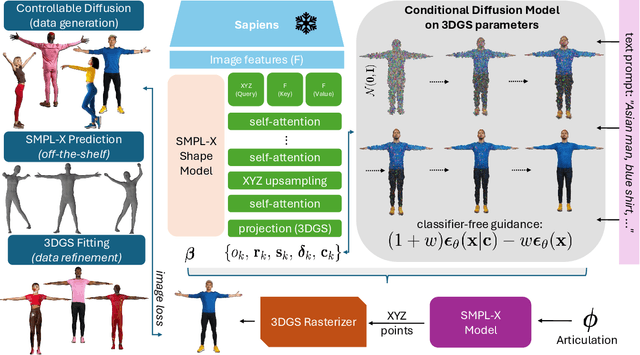
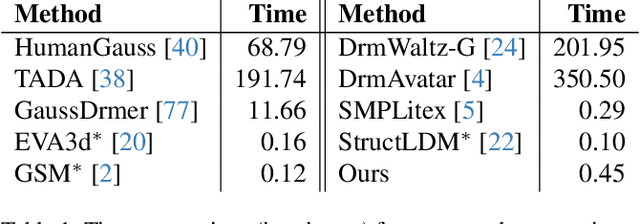
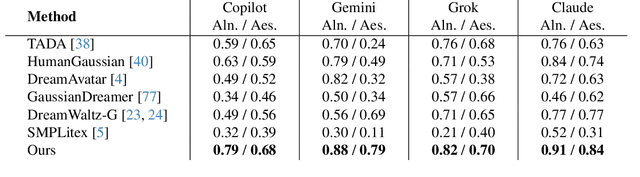

3D human generation is an important problem with a wide range of applications in computer vision and graphics. Despite recent progress in generative AI such as diffusion models or rendering methods like Neural Radiance Fields or Gaussian Splatting, controlling the generation of accurate 3D humans from text prompts remains an open challenge. Current methods struggle with fine detail, accurate rendering of hands and faces, human realism, and controlability over appearance. The lack of diversity, realism, and annotation in human image data also remains a challenge, hindering the development of a foundational 3D human model. We present a weakly supervised pipeline that tries to address these challenges. In the first step, we generate a photorealistic human image dataset with controllable attributes such as appearance, race, gender, etc using a state-of-the-art image diffusion model. Next, we propose an efficient mapping approach from image features to 3D point clouds using a transformer-based architecture. Finally, we close the loop by training a point-cloud diffusion model that is conditioned on the same text prompts used to generate the original samples. We demonstrate orders-of-magnitude speed-ups in 3D human generation compared to the state-of-the-art approaches, along with significantly improved text-prompt alignment, realism, and rendering quality. We will make the code and dataset available.
HandOcc: NeRF-based Hand Rendering with Occupancy Networks
May 04, 2025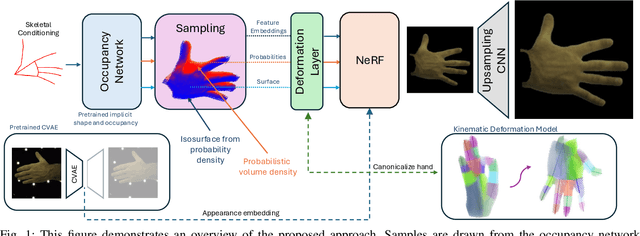
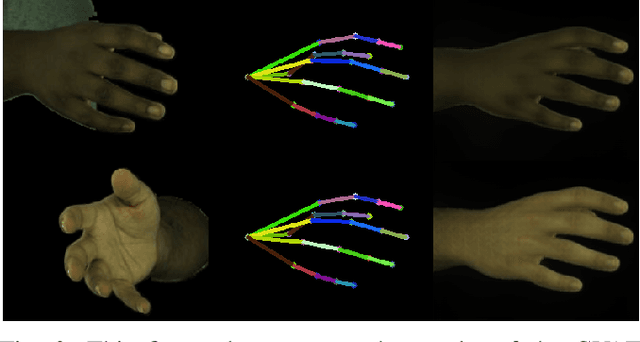
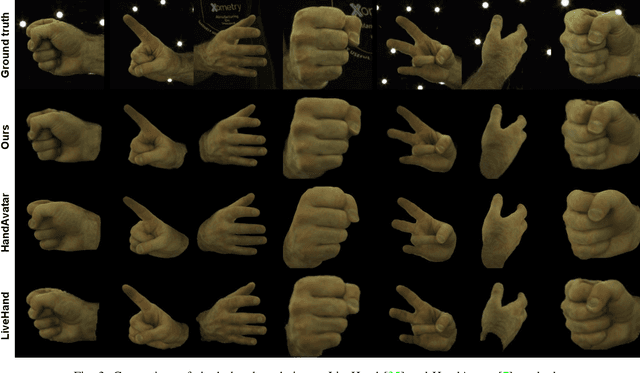

We propose HandOcc, a novel framework for hand rendering based upon occupancy. Popular rendering methods such as NeRF are often combined with parametric meshes to provide deformable hand models. However, in doing so, such approaches present a trade-off between the fidelity of the mesh and the complexity and dimensionality of the parametric model. The simplicity of parametric mesh structures is appealing, but the underlying issue is that it binds methods to mesh initialization, making it unable to generalize to objects where a parametric model does not exist. It also means that estimation is tied to mesh resolution and the accuracy of mesh fitting. This paper presents a pipeline for meshless 3D rendering, which we apply to the hands. By providing only a 3D skeleton, the desired appearance is extracted via a convolutional model. We do this by exploiting a NeRF renderer conditioned upon an occupancy-based representation. The approach uses the hand occupancy to resolve hand-to-hand interactions further improving results, allowing fast rendering, and excellent hand appearance transfer. On the benchmark InterHand2.6M dataset, we achieved state-of-the-art results.