 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Using Sign Language Production as Data Augmentation to enhance Sign Language Translation
Jun 11, 2025



Machine learning models fundamentally rely on large quantities of high-quality data. Collecting the necessary data for these models can be challenging due to cost, scarcity, and privacy restrictions. Signed languages are visual languages used by the deaf community and are considered low-resource languages. Sign language datasets are often orders of magnitude smaller than their spoken language counterparts. Sign Language Production is the task of generating sign language videos from spoken language sentences, while Sign Language Translation is the reverse translation task. Here, we propose leveraging recent advancements in Sign Language Production to augment existing sign language datasets and enhance the performance of Sign Language Translation models. For this, we utilize three techniques: a skeleton-based approach to production, sign stitching, and two photo-realistic generative models, SignGAN and SignSplat. We evaluate the effectiveness of these techniques in enhancing the performance of Sign Language Translation models by generating variation in the signer's appearance and the motion of the skeletal data. Our results demonstrate that the proposed methods can effectively augment existing datasets and enhance the performance of Sign Language Translation models by up to 19%, paving the way for more robust and accurate Sign Language Translation systems, even in resource-constrained environments.
Hands-On: Segmenting Individual Signs from Continuous Sequences
Apr 14, 2025This work tackles the challenge of continuous sign language segmentation, a key task with huge implications for sign language translation and data annotation. We propose a transformer-based architecture that models the temporal dynamics of signing and frames segmentation as a sequence labeling problem using the Begin-In-Out (BIO) tagging scheme. Our method leverages the HaMeR hand features, and is complemented with 3D Angles. Extensive experiments show that our model achieves state-of-the-art results on the DGS Corpus, while our features surpass prior benchmarks on BSLCorpus.
Sign Stitching: A Novel Approach to Sign Language Production
May 13, 2024Sign Language Production (SLP) is a challenging task, given the limited resources available and the inherent diversity within sign data. As a result, previous works have suffered from the problem of regression to the mean, leading to under-articulated and incomprehensible signing. In this paper, we propose using dictionary examples and a learnt codebook of facial expressions to create expressive sign language sequences. However, simply concatenating signs and adding the face creates robotic and unnatural sequences. To address this we present a 7-step approach to effectively stitch sequences together. First, by normalizing each sign into a canonical pose, cropping, and stitching we create a continuous sequence. Then, by applying filtering in the frequency domain and resampling each sign, we create cohesive natural sequences that mimic the prosody found in the original data. We leverage a SignGAN model to map the output to a photo-realistic signer and present a complete Text-to-Sign (T2S) SLP pipeline. Our evaluation demonstrates the effectiveness of the approach, showcasing state-of-the-art performance across all datasets. Finally, a user evaluation shows our approach outperforms the baseline model and is capable of producing realistic sign language sequences.
Select and Reorder: A Novel Approach for Neural Sign Language Production
Apr 17, 2024



Sign languages, often categorised as low-resource languages, face significant challenges in achieving accurate translation due to the scarcity of parallel annotated datasets. This paper introduces Select and Reorder (S&R), a novel approach that addresses data scarcity by breaking down the translation process into two distinct steps: Gloss Selection (GS) and Gloss Reordering (GR). Our method leverages large spoken language models and the substantial lexical overlap between source spoken languages and target sign languages to establish an initial alignment. Both steps make use of Non-AutoRegressive (NAR) decoding for reduced computation and faster inference speeds. Through this disentanglement of tasks, we achieve state-of-the-art BLEU and Rouge scores on the Meine DGS Annotated (mDGS) dataset, demonstrating a substantial BLUE-1 improvement of 37.88% in Text to Gloss (T2G) Translation. This innovative approach paves the way for more effective translation models for sign languages, even in resource-constrained settings.
A Data-Driven Representation for Sign Language Production
Apr 17, 2024



Phonetic representations are used when recording spoken languages, but no equivalent exists for recording signed languages. As a result, linguists have proposed several annotation systems that operate on the gloss or sub-unit level; however, these resources are notably irregular and scarce. Sign Language Production (SLP) aims to automatically translate spoken language sentences into continuous sequences of sign language. However, current state-of-the-art approaches rely on scarce linguistic resources to work. This has limited progress in the field. This paper introduces an innovative solution by transforming the continuous pose generation problem into a discrete sequence generation problem. Thus, overcoming the need for costly annotation. Although, if available, we leverage the additional information to enhance our approach. By applying Vector Quantisation (VQ) to sign language data, we first learn a codebook of short motions that can be combined to create a natural sequence of sign. Where each token in the codebook can be thought of as the lexicon of our representation. Then using a transformer we perform a translation from spoken language text to a sequence of codebook tokens. Each token can be directly mapped to a sequence of poses allowing the translation to be performed by a single network. Furthermore, we present a sign stitching method to effectively join tokens together. We evaluate on the RWTH-PHOENIX-Weather-2014T (PHOENIX14T) and the more challenging Meine DGS Annotated (mDGS) datasets. An extensive evaluation shows our approach outperforms previous methods, increasing the BLEU-1 back translation score by up to 72%.
Gloss Alignment Using Word Embeddings
Aug 08, 2023

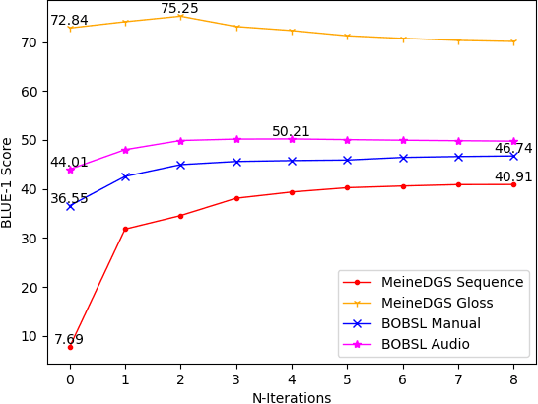
Capturing and annotating Sign language datasets is a time consuming and costly process. Current datasets are orders of magnitude too small to successfully train unconstrained \acf{slt} models. As a result, research has turned to TV broadcast content as a source of large-scale training data, consisting of both the sign language interpreter and the associated audio subtitle. However, lack of sign language annotation limits the usability of this data and has led to the development of automatic annotation techniques such as sign spotting. These spottings are aligned to the video rather than the subtitle, which often results in a misalignment between the subtitle and spotted signs. In this paper we propose a method for aligning spottings with their corresponding subtitles using large spoken language models. Using a single modality means our method is computationally inexpensive and can be utilized in conjunction with existing alignment techniques. We quantitatively demonstrate the effectiveness of our method on the \acf{mdgs} and \acf{bobsl} datasets, recovering up to a 33.22 BLEU-1 score in word alignment.