 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSign Stitching: A Novel Approach to Sign Language Production
May 13, 2024Sign Language Production (SLP) is a challenging task, given the limited resources available and the inherent diversity within sign data. As a result, previous works have suffered from the problem of regression to the mean, leading to under-articulated and incomprehensible signing. In this paper, we propose using dictionary examples and a learnt codebook of facial expressions to create expressive sign language sequences. However, simply concatenating signs and adding the face creates robotic and unnatural sequences. To address this we present a 7-step approach to effectively stitch sequences together. First, by normalizing each sign into a canonical pose, cropping, and stitching we create a continuous sequence. Then, by applying filtering in the frequency domain and resampling each sign, we create cohesive natural sequences that mimic the prosody found in the original data. We leverage a SignGAN model to map the output to a photo-realistic signer and present a complete Text-to-Sign (T2S) SLP pipeline. Our evaluation demonstrates the effectiveness of the approach, showcasing state-of-the-art performance across all datasets. Finally, a user evaluation shows our approach outperforms the baseline model and is capable of producing realistic sign language sequences.
Select and Reorder: A Novel Approach for Neural Sign Language Production
Apr 17, 2024



Sign languages, often categorised as low-resource languages, face significant challenges in achieving accurate translation due to the scarcity of parallel annotated datasets. This paper introduces Select and Reorder (S&R), a novel approach that addresses data scarcity by breaking down the translation process into two distinct steps: Gloss Selection (GS) and Gloss Reordering (GR). Our method leverages large spoken language models and the substantial lexical overlap between source spoken languages and target sign languages to establish an initial alignment. Both steps make use of Non-AutoRegressive (NAR) decoding for reduced computation and faster inference speeds. Through this disentanglement of tasks, we achieve state-of-the-art BLEU and Rouge scores on the Meine DGS Annotated (mDGS) dataset, demonstrating a substantial BLUE-1 improvement of 37.88% in Text to Gloss (T2G) Translation. This innovative approach paves the way for more effective translation models for sign languages, even in resource-constrained settings.
Gloss Alignment Using Word Embeddings
Aug 08, 2023

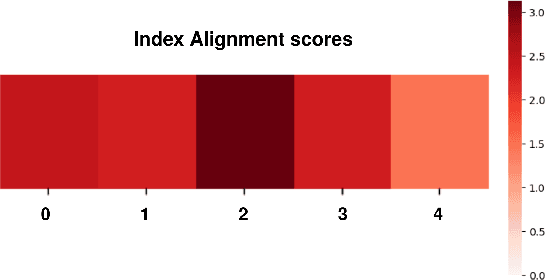
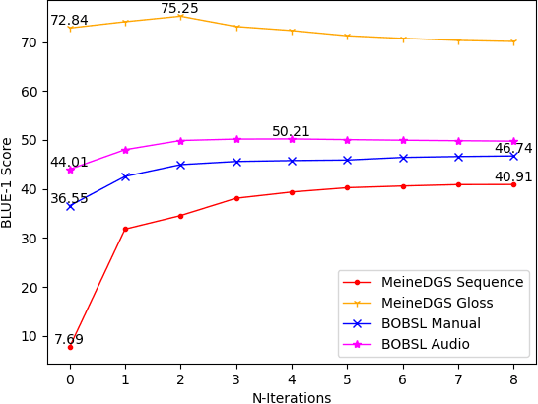
Capturing and annotating Sign language datasets is a time consuming and costly process. Current datasets are orders of magnitude too small to successfully train unconstrained \acf{slt} models. As a result, research has turned to TV broadcast content as a source of large-scale training data, consisting of both the sign language interpreter and the associated audio subtitle. However, lack of sign language annotation limits the usability of this data and has led to the development of automatic annotation techniques such as sign spotting. These spottings are aligned to the video rather than the subtitle, which often results in a misalignment between the subtitle and spotted signs. In this paper we propose a method for aligning spottings with their corresponding subtitles using large spoken language models. Using a single modality means our method is computationally inexpensive and can be utilized in conjunction with existing alignment techniques. We quantitatively demonstrate the effectiveness of our method on the \acf{mdgs} and \acf{bobsl} datasets, recovering up to a 33.22 BLEU-1 score in word alignment.
Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Photo-Realistic Sign Language Production
Mar 29, 2022
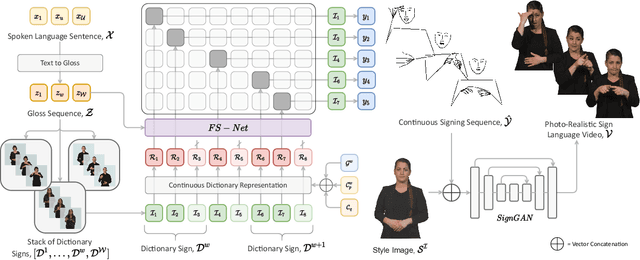
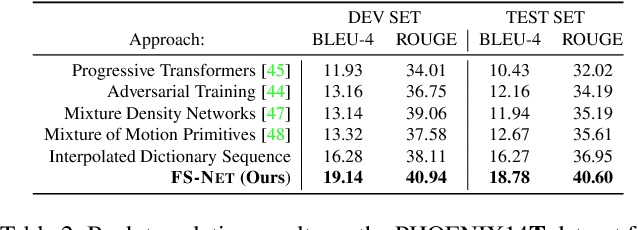
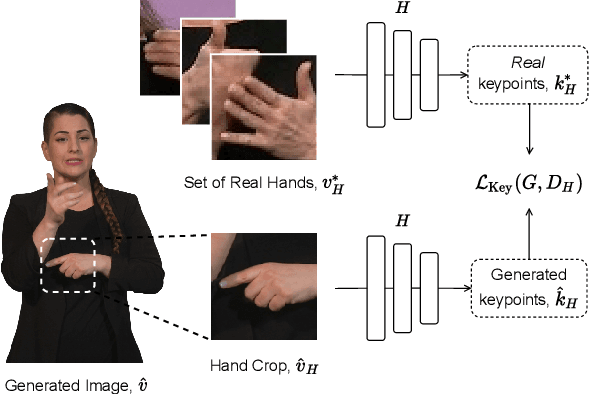
Sign languages are visual languages, with vocabularies as rich as their spoken language counterparts. However, current deep-learning based Sign Language Production (SLP) models produce under-articulated skeleton pose sequences from constrained vocabularies and this limits applicability. To be understandable and accepted by the deaf, an automatic SLP system must be able to generate co-articulated photo-realistic signing sequences for large domains of discourse. In this work, we tackle large-scale SLP by learning to co-articulate between dictionary signs, a method capable of producing smooth signing while scaling to unconstrained domains of discourse. To learn sign co-articulation, we propose a novel Frame Selection Network (FS-Net) that improves the temporal alignment of interpolated dictionary signs to continuous signing sequences. Additionally, we propose SignGAN, a pose-conditioned human synthesis model that produces photo-realistic sign language videos direct from skeleton pose. We propose a novel keypoint-based loss function which improves the quality of synthesized hand images. We evaluate our SLP model on the large-scale meineDGS (mDGS) corpus, conducting extensive user evaluation showing our FS-Net approach improves co-articulation of interpolated dictionary signs. Additionally, we show that SignGAN significantly outperforms all baseline methods for quantitative metrics, human perceptual studies and native deaf signer comprehension.
Skeletal Graph Self-Attention: Embedding a Skeleton Inductive Bias into Sign Language Production
Dec 06, 2021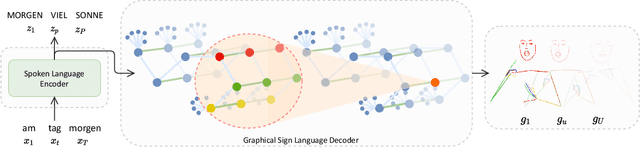

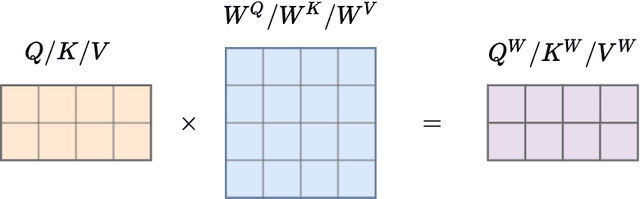

Recent approaches to Sign Language Production (SLP) have adopted spoken language Neural Machine Translation (NMT) architectures, applied without sign-specific modifications. In addition, these works represent sign language as a sequence of skeleton pose vectors, projected to an abstract representation with no inherent skeletal structure. In this paper, we represent sign language sequences as a skeletal graph structure, with joints as nodes and both spatial and temporal connections as edges. To operate on this graphical structure, we propose Skeletal Graph Self-Attention (SGSA), a novel graphical attention layer that embeds a skeleton inductive bias into the SLP model. Retaining the skeletal feature representation throughout, we directly apply a spatio-temporal adjacency matrix into the self-attention formulation. This provides structure and context to each skeletal joint that is not possible when using a non-graphical abstract representation, enabling fluid and expressive sign language production. We evaluate our Skeletal Graph Self-Attention architecture on the challenging RWTH-PHOENIX-Weather-2014T(PHOENIX14T) dataset, achieving state-of-the-art back translation performance with an 8% and 7% improvement over competing methods for the dev and test sets.
Mixed SIGNals: Sign Language Production via a Mixture of Motion Primitives
Jul 26, 2021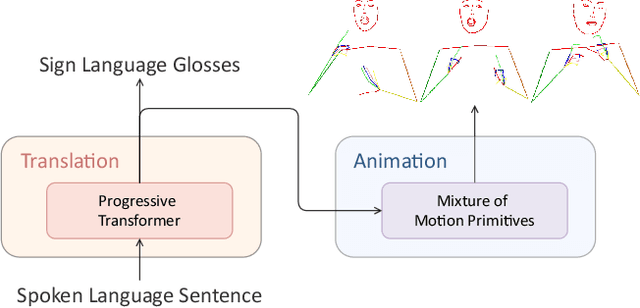
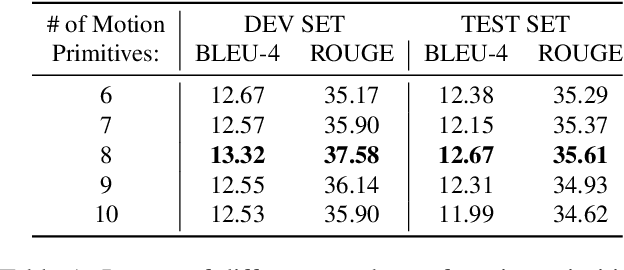
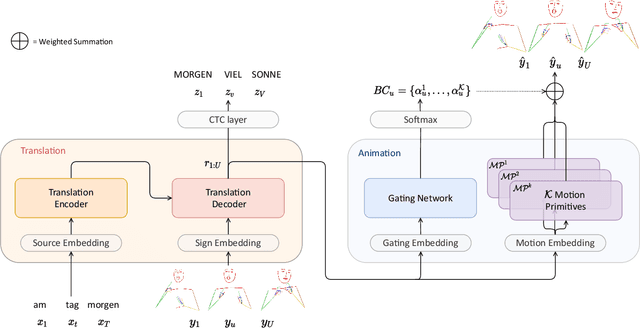
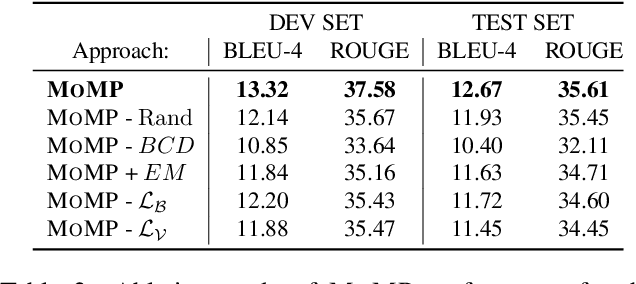
It is common practice to represent spoken languages at their phonetic level. However, for sign languages, this implies breaking motion into its constituent motion primitives. Avatar based Sign Language Production (SLP) has traditionally done just this, building up animation from sequences of hand motions, shapes and facial expressions. However, more recent deep learning based solutions to SLP have tackled the problem using a single network that estimates the full skeletal structure. We propose splitting the SLP task into two distinct jointly-trained sub-tasks. The first translation sub-task translates from spoken language to a latent sign language representation, with gloss supervision. Subsequently, the animation sub-task aims to produce expressive sign language sequences that closely resemble the learnt spatio-temporal representation. Using a progressive transformer for the translation sub-task, we propose a novel Mixture of Motion Primitives (MoMP) architecture for sign language animation. A set of distinct motion primitives are learnt during training, that can be temporally combined at inference to animate continuous sign language sequences. We evaluate on the challenging RWTH-PHOENIX-Weather-2014T(PHOENIX14T) dataset, presenting extensive ablation studies and showing that MoMP outperforms baselines in user evaluations. We achieve state-of-the-art back translation performance with an 11% improvement over competing results. Importantly, and for the first time, we showcase stronger performance for a full translation pipeline going from spoken language to sign, than from gloss to sign.
AnonySIGN: Novel Human Appearance Synthesis for Sign Language Video Anonymisation
Jul 23, 2021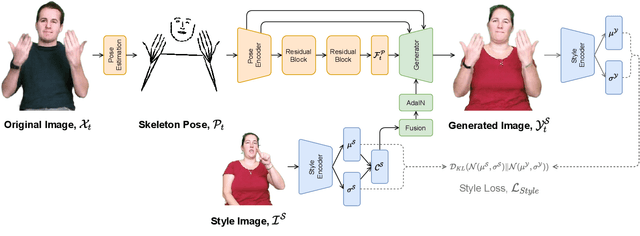
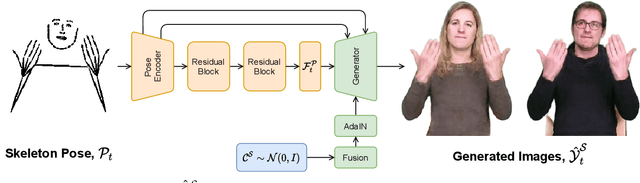


The visual anonymisation of sign language data is an essential task to address privacy concerns raised by large-scale dataset collection. Previous anonymisation techniques have either significantly affected sign comprehension or required manual, labour-intensive work. In this paper, we formally introduce the task of Sign Language Video Anonymisation (SLVA) as an automatic method to anonymise the visual appearance of a sign language video whilst retaining the meaning of the original sign language sequence. To tackle SLVA, we propose AnonySign, a novel automatic approach for visual anonymisation of sign language data. We first extract pose information from the source video to remove the original signer appearance. We next generate a photo-realistic sign language video of a novel appearance from the pose sequence, using image-to-image translation methods in a conditional variational autoencoder framework. An approximate posterior style distribution is learnt, which can be sampled from to synthesise novel human appearances. In addition, we propose a novel \textit{style loss} that ensures style consistency in the anonymised sign language videos. We evaluate AnonySign for the SLVA task with extensive quantitative and qualitative experiments highlighting both realism and anonymity of our novel human appearance synthesis. In addition, we formalise an anonymity perceptual study as an evaluation criteria for the SLVA task and showcase that video anonymisation using AnonySign retains the original sign language content.
Content4All Open Research Sign Language Translation Datasets
May 05, 2021


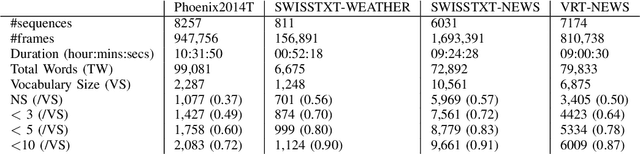
Computational sign language research lacks the large-scale datasets that enables the creation of useful reallife applications. To date, most research has been limited to prototype systems on small domains of discourse, e.g. weather forecasts. To address this issue and to push the field forward, we release six datasets comprised of 190 hours of footage on the larger domain of news. From this, 20 hours of footage have been annotated by Deaf experts and interpreters and is made publicly available for research purposes. In this paper, we share the dataset collection process and tools developed to enable the alignment of sign language video and subtitles, as well as baseline translation results to underpin future research.
Continuous 3D Multi-Channel Sign Language Production via Progressive Transformers and Mixture Density Networks
Mar 11, 2021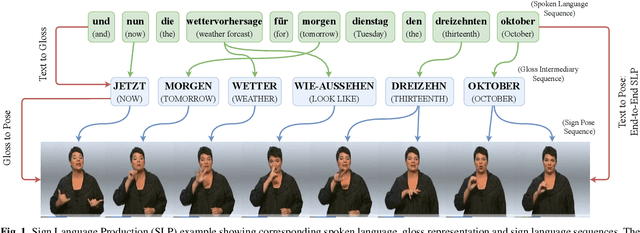
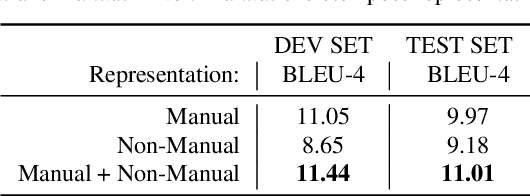
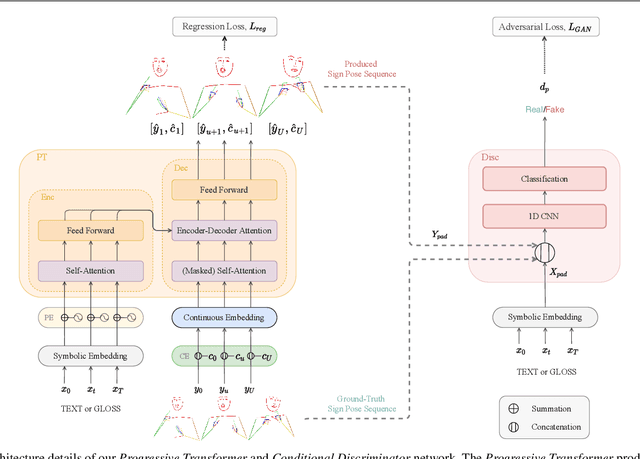

Sign languages are multi-channel visual languages, where signers use a continuous 3D space to communicate.Sign Language Production (SLP), the automatic translation from spoken to sign languages, must embody both the continuous articulation and full morphology of sign to be truly understandable by the Deaf community. Previous deep learning-based SLP works have produced only a concatenation of isolated signs focusing primarily on the manual features, leading to a robotic and non-expressive production. In this work, we propose a novel Progressive Transformer architecture, the first SLP model to translate from spoken language sentences to continuous 3D multi-channel sign pose sequences in an end-to-end manner. Our transformer network architecture introduces a counter decoding that enables variable length continuous sequence generation by tracking the production progress over time and predicting the end of sequence. We present extensive data augmentation techniques to reduce prediction drift, alongside an adversarial training regime and a Mixture Density Network (MDN) formulation to produce realistic and expressive sign pose sequences. We propose a back translation evaluation mechanism for SLP, presenting benchmark quantitative results on the challenging PHOENIX14T dataset and setting baselines for future research. We further provide a user evaluation of our SLP model, to understand the Deaf reception of our sign pose productions.
Everybody Sign Now: Translating Spoken Language to Photo Realistic Sign Language Video
Nov 26, 2020
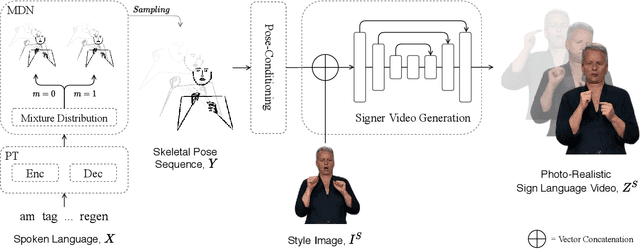
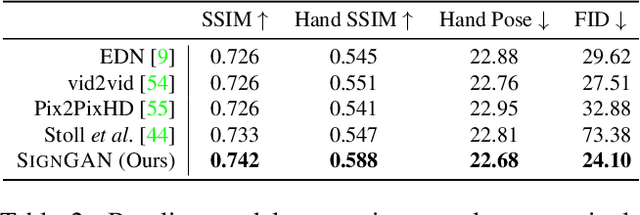
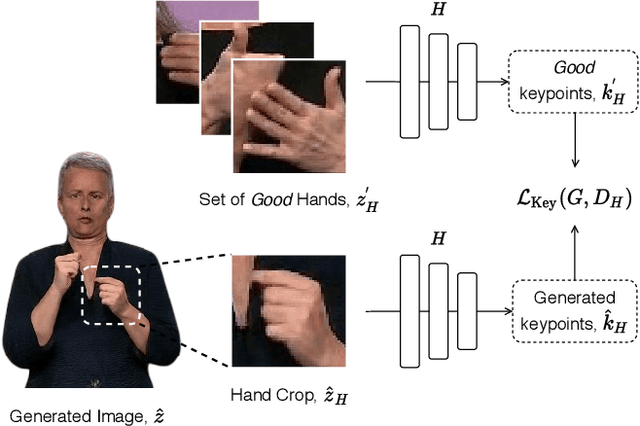
To be truly understandable and accepted by Deaf communities, an automatic Sign Language Production (SLP) system must generate a photo-realistic signer. Prior approaches based on graphical avatars have proven unpopular, whereas recent neural SLP works that produce skeleton pose sequences have been shown to be not understandable to Deaf viewers. In this paper, we propose SignGAN, the first SLP model to produce photo-realistic continuous sign language videos directly from spoken language. We employ a transformer architecture with a Mixture Density Network (MDN) formulation to handle the translation from spoken language to skeletal pose. A pose-conditioned human synthesis model is then introduced to generate a photo-realistic sign language video from the skeletal pose sequence. This allows the photo-realistic production of sign videos directly translated from written text. We further propose a novel keypoint-based loss function, which significantly improves the quality of synthesized hand images, operating in the keypoint space to avoid issues caused by motion blur. In addition, we introduce a method for controllable video generation, enabling training on large, diverse sign language datasets and providing the ability to control the signer appearance at inference. Using a dataset of eight different sign language interpreters extracted from broadcast footage, we show that SignGAN significantly outperforms all baseline methods for quantitative metrics and human perceptual studies.