 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepsifx -- Psychological and Social Interactions Feature Extraction Package
Jul 16, 2024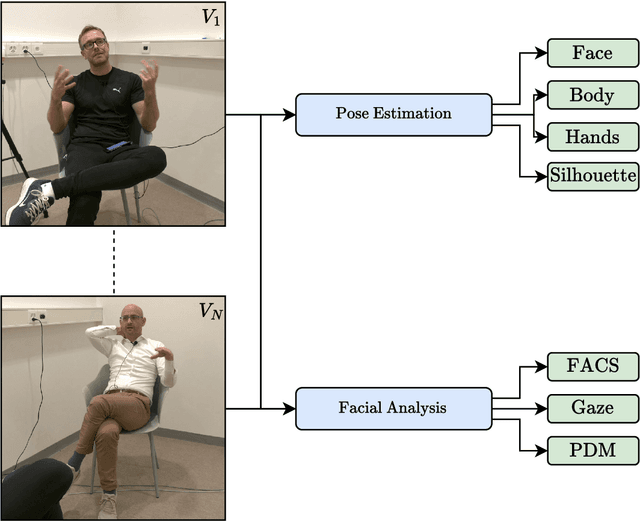



psifx is a plug-and-play multi-modal feature extraction toolkit, aiming to facilitate and democratize the use of state-of-the-art machine learning techniques for human sciences research. It is motivated by a need (a) to automate and standardize data annotation processes, otherwise involving expensive, lengthy, and inconsistent human labor, such as the transcription or coding of behavior changes from audio and video sources; (b) to develop and distribute open-source community-driven psychology research software; and (c) to enable large-scale access and ease of use to non-expert users. The framework contains an array of tools for tasks, such as speaker diarization, closed-caption transcription and translation from audio, as well as body, hand, and facial pose estimation and gaze tracking from video. The package has been designed with a modular and task-oriented approach, enabling the community to add or update new tools easily. We strongly hope that this package will provide psychologists a simple and practical solution for efficiently a range of audio, linguistic, and visual features from audio and video, thereby creating new opportunities for in-depth study of real-time behavioral phenomena.
Novel View Synthesis of Humans using Differentiable Rendering
Mar 28, 2023We present a new approach for synthesizing novel views of people in new poses. Our novel differentiable renderer enables the synthesis of highly realistic images from any viewpoint. Rather than operating over mesh-based structures, our renderer makes use of diffuse Gaussian primitives that directly represent the underlying skeletal structure of a human. Rendering these primitives gives results in a high-dimensional latent image, which is then transformed into an RGB image by a decoder network. The formulation gives rise to a fully differentiable framework that can be trained end-to-end. We demonstrate the effectiveness of our approach to image reconstruction on both the Human3.6M and Panoptic Studio datasets. We show how our approach can be used for motion transfer between individuals; novel view synthesis of individuals captured from just a single camera; to synthesize individuals from any virtual viewpoint; and to re-render people in novel poses. Code and video results are available at https://github.com/GuillaumeRochette/HumanViewSynthesis.
Human Pose Manipulation and Novel View Synthesis using Differentiable Rendering
Nov 24, 2021



We present a new approach for synthesizing novel views of people in new poses. Our novel differentiable renderer enables the synthesis of highly realistic images from any viewpoint. Rather than operating over mesh-based structures, our renderer makes use of diffuse Gaussian primitives that directly represent the underlying skeletal structure of a human. Rendering these primitives gives results in a high-dimensional latent image, which is then transformed into an RGB image by a decoder network. The formulation gives rise to a fully differentiable framework that can be trained end-to-end. We demonstrate the effectiveness of our approach to image reconstruction on both the Human3.6M and Panoptic Studio datasets. We show how our approach can be used for motion transfer between individuals; novel view synthesis of individuals captured from just a single camera; to synthesize individuals from any virtual viewpoint; and to re-render people in novel poses. Code and video results are available at https://github.com/GuillaumeRochette/HumanViewSynthesis.
Content4All Open Research Sign Language Translation Datasets
May 05, 2021


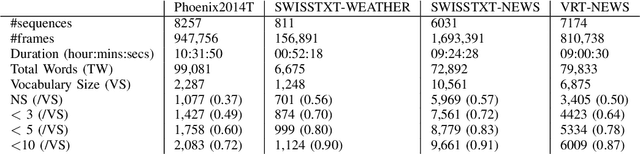
Computational sign language research lacks the large-scale datasets that enables the creation of useful reallife applications. To date, most research has been limited to prototype systems on small domains of discourse, e.g. weather forecasts. To address this issue and to push the field forward, we release six datasets comprised of 190 hours of footage on the larger domain of news. From this, 20 hours of footage have been annotated by Deaf experts and interpreters and is made publicly available for research purposes. In this paper, we share the dataset collection process and tools developed to enable the alignment of sign language video and subtitles, as well as baseline translation results to underpin future research.
Weakly-Supervised 3D Pose Estimation from a Single Image using Multi-View Consistency
Sep 13, 2019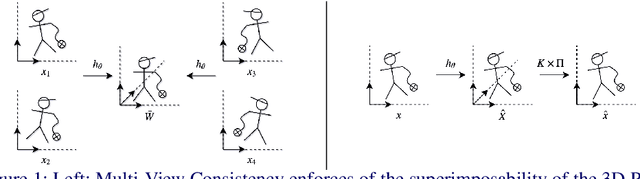



We present a novel data-driven regularizer for weakly-supervised learning of 3D human pose estimation that eliminates the drift problem that affects existing approaches. We do this by moving the stereo reconstruction problem into the loss of the network itself. This avoids the need to reconstruct 3D data prior to training and unlike previous semi-supervised approaches, avoids the need for a warm-up period of supervised training. The conceptual and implementational simplicity of our approach is fundamental to its appeal. Not only is it straightforward to augment many weakly-supervised approaches with our additional re-projection based loss, but it is obvious how it shapes reconstructions and prevents drift. As such we believe it will be a valuable tool for any researcher working in weakly-supervised 3D reconstruction. Evaluating on Panoptic, the largest multi-camera and markerless dataset available, we obtain an accuracy that is essentially indistinguishable from a strongly-supervised approach making full use of 3D groundtruth in training.