Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent4All Open Research Sign Language Translation Datasets
May 05, 2021


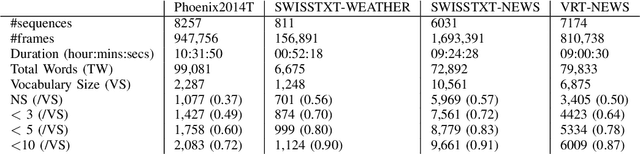
Computational sign language research lacks the large-scale datasets that enables the creation of useful reallife applications. To date, most research has been limited to prototype systems on small domains of discourse, e.g. weather forecasts. To address this issue and to push the field forward, we release six datasets comprised of 190 hours of footage on the larger domain of news. From this, 20 hours of footage have been annotated by Deaf experts and interpreters and is made publicly available for research purposes. In this paper, we share the dataset collection process and tools developed to enable the alignment of sign language video and subtitles, as well as baseline translation results to underpin future research.
Via