 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Beyond Gloss: A Hand-Centric Framework for Gloss-Free Sign Language Translation
Jul 31, 2025Sign Language Translation (SLT) is a challenging task that requires bridging the modality gap between visual and linguistic information while capturing subtle variations in hand shapes and movements. To address these challenges, we introduce \textbf{BeyondGloss}, a novel gloss-free SLT framework that leverages the spatio-temporal reasoning capabilities of Video Large Language Models (VideoLLMs). Since existing VideoLLMs struggle to model long videos in detail, we propose a novel approach to generate fine-grained, temporally-aware textual descriptions of hand motion. A contrastive alignment module aligns these descriptions with video features during pre-training, encouraging the model to focus on hand-centric temporal dynamics and distinguish signs more effectively. To further enrich hand-specific representations, we distill fine-grained features from HaMeR. Additionally, we apply a contrastive loss between sign video representations and target language embeddings to reduce the modality gap in pre-training. \textbf{BeyondGloss} achieves state-of-the-art performance on the Phoenix14T and CSL-Daily benchmarks, demonstrating the effectiveness of the proposed framework. We will release the code upon acceptance of the paper.
Hands-On: Segmenting Individual Signs from Continuous Sequences
Apr 14, 2025This work tackles the challenge of continuous sign language segmentation, a key task with huge implications for sign language translation and data annotation. We propose a transformer-based architecture that models the temporal dynamics of signing and frames segmentation as a sequence labeling problem using the Begin-In-Out (BIO) tagging scheme. Our method leverages the HaMeR hand features, and is complemented with 3D Angles. Extensive experiments show that our model achieves state-of-the-art results on the DGS Corpus, while our features surpass prior benchmarks on BSLCorpus.
Modelling the Distribution of Human Motion for Sign Language Assessment
Aug 19, 2024



Sign Language Assessment (SLA) tools are useful to aid in language learning and are underdeveloped. Previous work has focused on isolated signs or comparison against a single reference video to assess Sign Languages (SL). This paper introduces a novel SLA tool designed to evaluate the comprehensibility of SL by modelling the natural distribution of human motion. We train our pipeline on data from native signers and evaluate it using SL learners. We compare our results to ratings from a human raters study and find strong correlation between human ratings and our tool. We visually demonstrate our tools ability to detect anomalous results spatio-temporally, providing actionable feedback to aid in SL learning and assessment.
Using an LLM to Turn Sign Spottings into Spoken Language Sentences
Mar 15, 2024Sign Language Translation (SLT) is a challenging task that aims to generate spoken language sentences from sign language videos. In this paper, we introduce a hybrid SLT approach, Spotter+GPT, that utilizes a sign spotter and a pretrained large language model to improve SLT performance. Our method builds upon the strengths of both components. The videos are first processed by the spotter, which is trained on a linguistic sign language dataset, to identify individual signs. These spotted signs are then passed to the powerful language model, which transforms them into coherent and contextually appropriate spoken language sentences.
Giving a Hand to Diffusion Models: a Two-Stage Approach to Improving Conditional Human Image Generation
Mar 15, 2024Recent years have seen significant progress in human image generation, particularly with the advancements in diffusion models. However, existing diffusion methods encounter challenges when producing consistent hand anatomy and the generated images often lack precise control over the hand pose. To address this limitation, we introduce a novel approach to pose-conditioned human image generation, dividing the process into two stages: hand generation and subsequent body out-painting around the hands. We propose training the hand generator in a multi-task setting to produce both hand images and their corresponding segmentation masks, and employ the trained model in the first stage of generation. An adapted ControlNet model is then used in the second stage to outpaint the body around the generated hands, producing the final result. A novel blending technique is introduced to preserve the hand details during the second stage that combines the results of both stages in a coherent way. This involves sequential expansion of the out-painted region while fusing the latent representations, to ensure a seamless and cohesive synthesis of the final image. Experimental evaluations demonstrate the superiority of our proposed method over state-of-the-art techniques, in both pose accuracy and image quality, as validated on the HaGRID dataset. Our approach not only enhances the quality of the generated hands but also offers improved control over hand pose, advancing the capabilities of pose-conditioned human image generation. The source code of the proposed approach is available at https://github.com/apelykh/hand-to-diffusion.
Is context all you need? Scaling Neural Sign Language Translation to Large Domains of Discourse
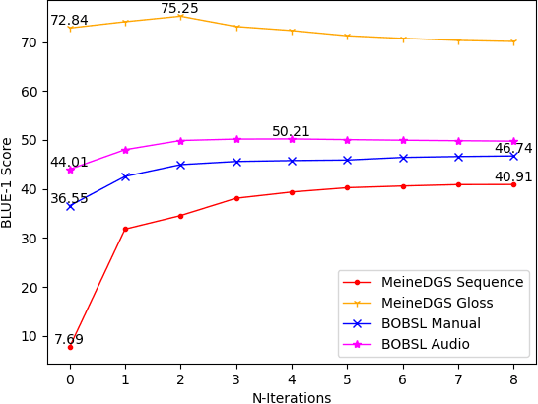
Aug 18, 2023Sign Language Translation (SLT) is a challenging task that aims to generate spoken language sentences from sign language videos, both of which have different grammar and word/gloss order. From a Neural Machine Translation (NMT) perspective, the straightforward way of training translation models is to use sign language phrase-spoken language sentence pairs. However, human interpreters heavily rely on the context to understand the conveyed information, especially for sign language interpretation, where the vocabulary size may be significantly smaller than their spoken language equivalent. Taking direct inspiration from how humans translate, we propose a novel multi-modal transformer architecture that tackles the translation task in a context-aware manner, as a human would. We use the context from previous sequences and confident predictions to disambiguate weaker visual cues. To achieve this we use complementary transformer encoders, namely: (1) A Video Encoder, that captures the low-level video features at the frame-level, (2) A Spotting Encoder, that models the recognized sign glosses in the video, and (3) A Context Encoder, which captures the context of the preceding sign sequences. We combine the information coming from these encoders in a final transformer decoder to generate spoken language translations. We evaluate our approach on the recently published large-scale BOBSL dataset, which contains ~1.2M sequences, and on the SRF dataset, which was part of the WMT-SLT 2022 challenge. We report significant improvements on state-of-the-art translation performance using contextual information, nearly doubling the reported BLEU-4 scores of baseline approaches.
Gloss Alignment Using Word Embeddings
Aug 08, 2023

Capturing and annotating Sign language datasets is a time consuming and costly process. Current datasets are orders of magnitude too small to successfully train unconstrained \acf{slt} models. As a result, research has turned to TV broadcast content as a source of large-scale training data, consisting of both the sign language interpreter and the associated audio subtitle. However, lack of sign language annotation limits the usability of this data and has led to the development of automatic annotation techniques such as sign spotting. These spottings are aligned to the video rather than the subtitle, which often results in a misalignment between the subtitle and spotted signs. In this paper we propose a method for aligning spottings with their corresponding subtitles using large spoken language models. Using a single modality means our method is computationally inexpensive and can be utilized in conjunction with existing alignment techniques. We quantitatively demonstrate the effectiveness of our method on the \acf{mdgs} and \acf{bobsl} datasets, recovering up to a 33.22 BLEU-1 score in word alignment.
Using Motion History Images with 3D Convolutional Networks in Isolated Sign Language Recognition
Oct 24, 2021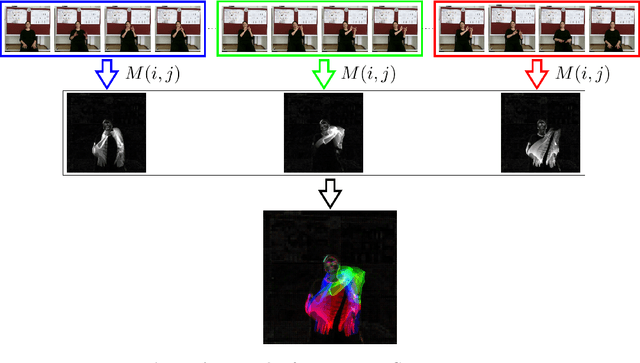

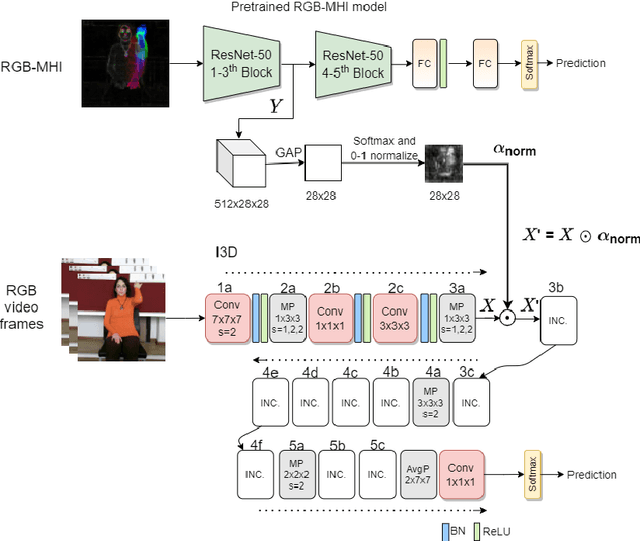

Sign language recognition using computational models is a challenging problem that requires simultaneous spatio-temporal modeling of the multiple sources, i.e. faces, hands, body etc. In this paper, we propose an isolated sign language recognition model based on a model trained using Motion History Images (MHI) that are generated from RGB video frames. RGB-MHI images represent spatio-temporal summary of each sign video effectively in a single RGB image. We propose two different approaches using this model. In the first approach, we use RGB-MHI model as a motion-based spatial attention module integrated in a 3D-CNN architecture. In the second approach, we use RGB-MHI model features directly with a late fusion technique with the features of a 3D-CNN model. We perform extensive experiments on two recently released large-scale isolated sign language datasets, namely AUTSL and BosphorusSign22k datasets. Our experiments show that our models, which use only RGB data, can compete with the state-of-the-art models in the literature that use multi-modal data.
ChaLearn LAP Large Scale Signer Independent Isolated Sign Language Recognition Challenge: Design, Results and Future Research
May 11, 2021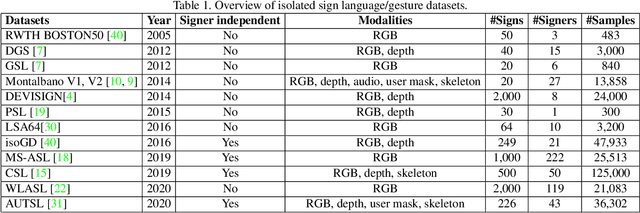

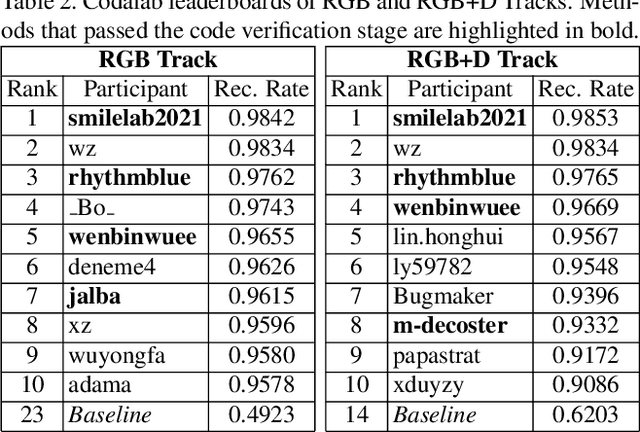
The performances of Sign Language Recognition (SLR) systems have improved considerably in recent years. However, several open challenges still need to be solved to allow SLR to be useful in practice. The research in the field is in its infancy in regards to the robustness of the models to a large diversity of signs and signers, and to fairness of the models to performers from different demographics. This work summarises the ChaLearn LAP Large Scale Signer Independent Isolated SLR Challenge, organised at CVPR 2021 with the goal of overcoming some of the aforementioned challenges. We analyse and discuss the challenge design, top winning solutions and suggestions for future research. The challenge attracted 132 participants in the RGB track and 59 in the RGB+Depth track, receiving more than 1.5K submissions in total. Participants were evaluated using a new large-scale multi-modal Turkish Sign Language (AUTSL) dataset, consisting of 226 sign labels and 36,302 isolated sign video samples performed by 43 different signers. Winning teams achieved more than 96% recognition rate, and their approaches benefited from pose/hand/face estimation, transfer learning, external data, fusion/ensemble of modalities and different strategies to model spatio-temporal information. However, methods still fail to distinguish among very similar signs, in particular those sharing similar hand trajectories.