 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hyperbolic Perspective on Hierarchical Structure in Object-Centric Scene Representations
Mar 14, 2026Slot attention has emerged as a powerful framework for unsupervised object-centric learning, decomposing visual scenes into a small set of compact vector representations called \emph{slots}, each capturing a distinct region or object. However, these slots are learned in Euclidean space, which provides no geometric inductive bias for the hierarchical relationships that naturally structure visual scenes. In this work, we propose a simple post-hoc pipeline to project Euclidean slot embeddings onto the Lorentz hyperboloid of hyperbolic space, without modifying the underlying training pipeline. We construct five-level visual hierarchies directly from slot attention masks and analyse whether hyperbolic geometry reveals latent hierarchical structure that remains invisible in Euclidean space. Integrating our pipeline with SPOT (images), VideoSAUR (video), and SlotContrast (video), We find that hyperbolic projection exposes a consistent scene-level to object-level organisation, where coarse slots occupy greater manifold depth than fine slots, which is absent in Euclidean space. We further identify a "curvature--task tradeoff": low curvature ($c{=}0.2$) matches or outperforms Euclidean on parent slot retrieval, while moderate curvature ($c{=}0.5$) achieves better inter-level separation. Together, these findings suggest that slot representations already encode latent hierarchy that hyperbolic geometry reveals, motivating end-to-end hyperbolic training as a natural next step. Code and models are available at \href{https://github.com/NeeluMadan/HHS}{github.com/NeeluMadan/HHS}.
MV-Fashion: Towards Enabling Virtual Try-On and Size Estimation with Multi-View Paired Data
Mar 09, 2026Existing 4D human datasets fall short for fashion-specific research, lacking either realistic garment dynamics or task-specific annotations. Synthetic datasets suffer from a realism gap, whereas real-world captures lack the detailed annotations and paired data required for virtual try-on (VTON) and size estimation tasks. To bridge this gap, we introduce MV-Fashion, a large-scale, multi-view video dataset engineered for domain-specific fashion analysis. MV-Fashion features 3,273 sequences (72.5 million frames) from 80 diverse subjects wearing 3-10 outfits each. It is designed to capture complex, real-world garment dynamics, including multiple layers and varied styling (e.g. rolled sleeves, tucked shirt). A core contribution is a rich data representation that includes pixel-level semantic annotations, ground-truth material properties like elasticity, and 3D point clouds. Crucially for VTON applications, MV-Fashion provides paired data: multi-view synchronized captures of worn garments alongside their corresponding flat, catalogue images. We leverage this dataset to establish baselines for fashion-centric tasks, including virtual try-on, clothing size estimation, and novel view synthesis. The dataset is available at https://hunorlaczko.github.io/MV-Fashion .
Beyond Caption-Based Queries for Video Moment Retrieval
Mar 02, 2026In this work, we investigate the degradation of existing VMR methods, particularly of DETR architectures, when trained on caption-based queries but evaluated on search queries. For this, we introduce three benchmarks by modifying the textual queries in three public VMR datasets -- i.e., HD-EPIC, YouCook2 and ActivityNet-Captions. Our analysis reveals two key generalization challenges: (i) A language gap, arising from the linguistic under-specification of search queries, and (ii) a multi-moment gap, caused by the shift from single-moment to multi-moment queries. We also identify a critical issue in these architectures -- an active decoder-query collapse -- as a primary cause of the poor generalization to multi-moment instances. We mitigate this issue with architectural modifications that effectively increase the number of active decoder queries. Extensive experiments demonstrate that our approach improves performance on search queries by up to 14.82% mAP_m, and up to 21.83% mAP_m on multi-moment search queries. The code, models and data are available in the project webpage: https://davidpujol.github.io/beyond-vmr/
AdaSpot: Spend Resolution Where It Matters for Precise Event Spotting
Feb 25, 2026Precise Event Spotting aims to localize fast-paced actions or events in videos with high temporal precision, a key task for applications in sports analytics, robotics, and autonomous systems. Existing methods typically process all frames uniformly, overlooking the inherent spatio-temporal redundancy in video data. This leads to redundant computation on non-informative regions while limiting overall efficiency. To remain tractable, they often spatially downsample inputs, losing fine-grained details crucial for precise localization. To address these limitations, we propose \textbf{AdaSpot}, a simple yet effective framework that processes low-resolution videos to extract global task-relevant features while adaptively selecting the most informative region-of-interest in each frame for high-resolution processing. The selection is performed via an unsupervised, task-aware strategy that maintains spatio-temporal consistency across frames and avoids the training instability of learnable alternatives. This design preserves essential fine-grained visual cues with a marginal computational overhead compared to low-resolution-only baselines, while remaining far more efficient than uniform high-resolution processing. Experiments on standard PES benchmarks demonstrate that \textbf{AdaSpot} achieves state-of-the-art performance under strict evaluation metrics (\eg, $+3.96$ and $+2.26$ mAP$@0$ frames on Tennis and FineDiving), while also maintaining strong results under looser metrics. Code is available at: \href{https://github.com/arturxe2/AdaSpot}{https://github.com/arturxe2/AdaSpot}.
Enhancing Personality Recognition by Comparing the Predictive Power of Traits, Facets, and Nuances
Feb 05, 2026Personality is a complex, hierarchical construct typically assessed through item-level questionnaires aggregated into broad trait scores. Personality recognition models aim to infer personality traits from different sources of behavioral data. However, reliance on broad trait scores as ground truth, combined with limited training data, poses challenges for generalization, as similar trait scores can manifest through diverse, context dependent behaviors. In this work, we explore the predictive impact of the more granular hierarchical levels of the Big-Five Personality Model, facets and nuances, to enhance personality recognition from audiovisual interaction data. Using the UDIVA v0.5 dataset, we trained a transformer-based model including cross-modal (audiovisual) and cross-subject (dyad-aware) attention mechanisms. Results show that nuance-level models consistently outperform facet and trait-level models, reducing mean squared error by up to 74% across interaction scenarios.
SOVABench: A Vehicle Surveillance Action Retrieval Benchmark for Multimodal Large Language Models
Jan 08, 2026Automatic identification of events and recurrent behavior analysis are critical for video surveillance. However, most existing content-based video retrieval benchmarks focus on scene-level similarity and do not evaluate the action discrimination required in surveillance. To address this gap, we introduce SOVABench (Surveillance Opposite Vehicle Actions Benchmark), a real-world retrieval benchmark built from surveillance footage and centered on vehicle-related actions. SOVABench defines two evaluation protocols (inter-pair and intra-pair) to assess cross-action discrimination and temporal direction understanding. Although action distinctions are generally intuitive for human observers, our experiments show that they remain challenging for state-of-the-art vision and multimodal models. Leveraging the visual reasoning and instruction-following capabilities of Multimodal Large Language Models (MLLMs), we present a training-free framework for producing interpretable embeddings from MLLM-generated descriptions for both images and videos. The framework achieves strong performance on SOVABench as well as on several spatial and counting benchmarks where contrastive Vision-Language Models often fail. The code, annotations, and instructions to construct the benchmark are publicly available.
PrismVAU: Prompt-Refined Inference System for Multimodal Video Anomaly Understanding
Jan 07, 2026Video Anomaly Understanding (VAU) extends traditional Video Anomaly Detection (VAD) by not only localizing anomalies but also describing and reasoning about their context. Existing VAU approaches often rely on fine-tuned multimodal large language models (MLLMs) or external modules such as video captioners, which introduce costly annotations, complex training pipelines, and high inference overhead. In this work, we introduce PrismVAU, a lightweight yet effective system for real-time VAU that leverages a single off-the-shelf MLLM for anomaly scoring, explanation, and prompt optimization. PrismVAU operates in two complementary stages: (1) a coarse anomaly scoring module that computes frame-level anomaly scores via similarity to textual anchors, and (2) an MLLM-based refinement module that contextualizes anomalies through system and user prompts. Both textual anchors and prompts are optimized with a weakly supervised Automatic Prompt Engineering (APE) framework. Extensive experiments on standard VAD benchmarks demonstrate that PrismVAU delivers competitive detection performance and interpretable anomaly explanations -- without relying on instruction tuning, frame-level annotations, and external modules or dense processing -- making it an efficient and practical solution for real-world applications.
Interact2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models
Dec 22, 2025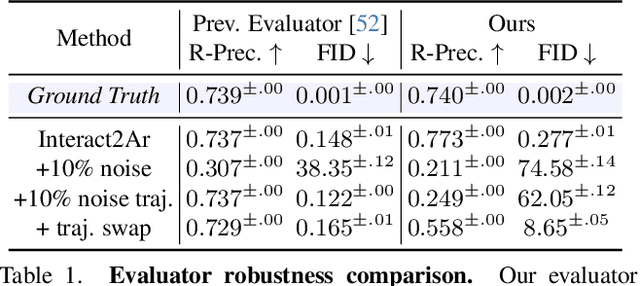
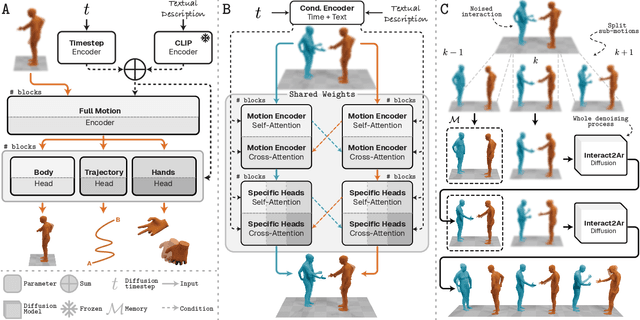
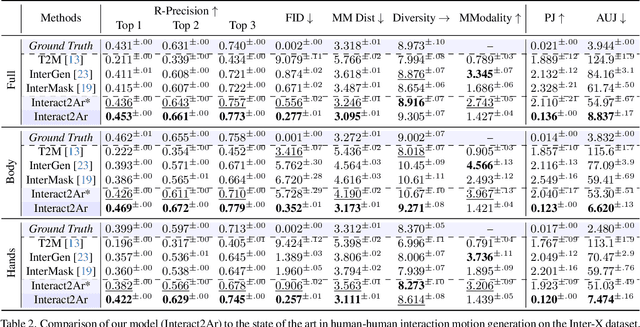
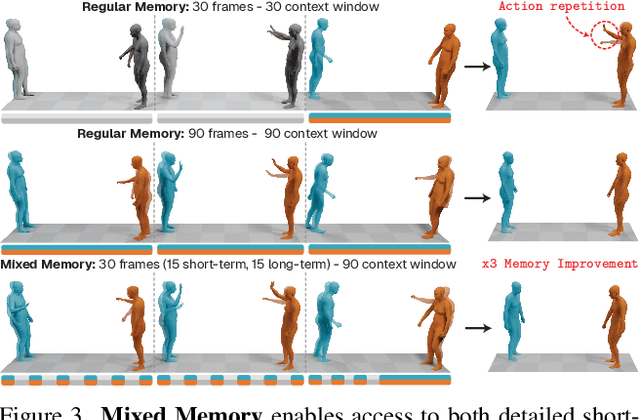
Generating realistic human-human interactions is a challenging task that requires not only high-quality individual body and hand motions, but also coherent coordination among all interactants. Due to limitations in available data and increased learning complexity, previous methods tend to ignore hand motions, limiting the realism and expressivity of the interactions. Additionally, current diffusion-based approaches generate entire motion sequences simultaneously, limiting their ability to capture the reactive and adaptive nature of human interactions. To address these limitations, we introduce Interact2Ar, the first end-to-end text-conditioned autoregressive diffusion model for generating full-body, human-human interactions. Interact2Ar incorporates detailed hand kinematics through dedicated parallel branches, enabling high-fidelity full-body generation. Furthermore, we introduce an autoregressive pipeline coupled with a novel memory technique that facilitates adaptation to the inherent variability of human interactions using efficient large context windows. The adaptability of our model enables a series of downstream applications, including temporal motion composition, real-time adaptation to disturbances, and extension beyond dyadic to multi-person scenarios. To validate the generated motions, we introduce a set of robust evaluators and extended metrics designed specifically for assessing full-body interactions. Through quantitative and qualitative experiments, we demonstrate the state-of-the-art performance of Interact2Ar.
RVLF: A Reinforcing Vision-Language Framework for Gloss-Free Sign Language Translation
Dec 08, 2025Gloss-free sign language translation (SLT) is hindered by two key challenges: **inadequate sign representation** that fails to capture nuanced visual cues, and **sentence-level semantic misalignment** in current LLM-based methods, which limits translation quality. To address these issues, we propose a three-stage **r**einforcing **v**ision-**l**anguage **f**ramework (**RVLF**). We build a large vision-language model (LVLM) specifically designed for sign language, and then combine it with reinforcement learning (RL) to adaptively enhance translation performance. First, for a sufficient representation of sign language, RVLF introduces an effective semantic representation learning mechanism that fuses skeleton-based motion cues with semantically rich visual features extracted via DINOv2, followed by instruction tuning to obtain a strong SLT-SFT baseline. Then, to improve sentence-level semantic misalignment, we introduce a GRPO-based optimization strategy that fine-tunes the SLT-SFT model with a reward function combining translation fidelity (BLEU) and sentence completeness (ROUGE), yielding the optimized model termed SLT-GRPO. Our conceptually simple framework yields substantial gains under the gloss-free SLT setting without pre-training on any external large-scale sign language datasets, improving BLEU-4 scores by +5.1, +1.11, +1.4, and +1.61 on the CSL-Daily, PHOENIX-2014T, How2Sign, and OpenASL datasets, respectively. To the best of our knowledge, this is the first work to incorporate GRPO into SLT. Extensive experiments and ablation studies validate the effectiveness of GRPO-based optimization in enhancing both translation quality and semantic consistency.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.