 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide, Deliberate, Decide: A Multi-Agent Framework for Fine-Grained Egocentric Action Recognition
Jun 16, 2026Fine-grained action recognition in egocentric video is challenging for Vision-Language Models (VLMs): actions often differ only in small visual cues, and a single model tends to be biased toward a subset of these cues. We propose Divide, Deliberate, Decide, a fully-local, zero-shot multi-agent framework in which (i) a VLM orchestrator chunks the video and proposes a top-k candidate label list per segment, (ii) an ensemble of heterogeneous VLM specialists, drawn from different open model families, engages in a structured deliberation that includes a peer-consultation round of questions, and (iii) agent rankings are aggregated with a Borda count and the orchestrator re-ranks its own prediction in light of the specialists' evidence. The entire pipeline runs locally with no fine-tuning. Experiments show that our method positively improves zero-shot action recognition performance over the baseline, highlighting the influence of a heterogeneous deliberation step, showing that the gain stems from decorrelated model priors rather than from additional compute.
Action-Guided Attention for Video Action Anticipation
Mar 02, 2026Anticipating future actions in videos is challenging, as the observed frames provide only evidence of past activities, requiring the inference of latent intentions to predict upcoming actions. Existing transformer-based approaches, which rely on dot-product attention over pixel representations, often lack the high-level semantics necessary to model video sequences for effective action anticipation. As a result, these methods tend to overfit to explicit visual cues present in the past frames, limiting their ability to capture underlying intentions and degrading generalization to unseen samples. To address this, we propose Action-Guided Attention (AGA), an attention mechanism that explicitly leverages predicted action sequences as queries and keys to guide sequence modeling. Our approach fosters the attention module to emphasize relevant moments from the past based on the upcoming activity and combine this information with the current frame embedding via a dedicated gating function. The design of AGA enables post-training analysis of the knowledge discovered from the training set. Experiments on the widely adopted EPIC-Kitchens-100 benchmark demonstrate that AGA generalizes well from validation to unseen test sets. Post-training analysis can further examine the action dependencies captured by the model and the counterfactual evidence it has internalized, offering transparent and interpretable insights into its anticipative predictions.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
L-SWAG: Layer-Sample Wise Activation with Gradients information for Zero-Shot NAS on Vision Transformers
May 12, 2025Training-free Neural Architecture Search (NAS) efficiently identifies high-performing neural networks using zero-cost (ZC) proxies. Unlike multi-shot and one-shot NAS approaches, ZC-NAS is both (i) time-efficient, eliminating the need for model training, and (ii) interpretable, with proxy designs often theoretically grounded. Despite rapid developments in the field, current SOTA ZC proxies are typically constrained to well-established convolutional search spaces. With the rise of Large Language Models shaping the future of deep learning, this work extends ZC proxy applicability to Vision Transformers (ViTs). We present a new benchmark using the Autoformer search space evaluated on 6 distinct tasks and propose Layer-Sample Wise Activation with Gradients information (L-SWAG), a novel, generalizable metric that characterizes both convolutional and transformer architectures across 14 tasks. Additionally, previous works highlighted how different proxies contain complementary information, motivating the need for a ML model to identify useful combinations. To further enhance ZC-NAS, we therefore introduce LIBRA-NAS (Low Information gain and Bias Re-Alignment), a method that strategically combines proxies to best represent a specific benchmark. Integrated into the NAS search, LIBRA-NAS outperforms evolution and gradient-based NAS techniques by identifying an architecture with a 17.0% test error on ImageNet1k in just 0.1 GPU days.
Gate-Shift-Pose: Enhancing Action Recognition in Sports with Skeleton Information
Mar 06, 2025This paper introduces Gate-Shift-Pose, an enhanced version of Gate-Shift-Fuse networks, designed for athlete fall classification in figure skating by integrating skeleton pose data alongside RGB frames. We evaluate two fusion strategies: early-fusion, which combines RGB frames with Gaussian heatmaps of pose keypoints at the input stage, and late-fusion, which employs a multi-stream architecture with attention mechanisms to combine RGB and pose features. Experiments on the FR-FS dataset demonstrate that Gate-Shift-Pose significantly outperforms the RGB-only baseline, improving accuracy by up to 40% with ResNet18 and 20% with ResNet50. Early-fusion achieves the highest accuracy (98.08%) with ResNet50, leveraging the model's capacity for effective multimodal integration, while late-fusion is better suited for lighter backbones like ResNet18. These results highlight the potential of multimodal architectures for sports action recognition and the critical role of skeleton pose information in capturing complex motion patterns.
GRASP-GCN: Graph-Shape Prioritization for Neural Architecture Search under Distribution Shifts
May 11, 2024Neural Architecture Search (NAS) methods have shown to output networks that largely outperform human-designed networks. However, conventional NAS methods have mostly tackled the single dataset scenario, incuring in a large computational cost as the procedure has to be run from scratch for every new dataset. In this work, we focus on predictor-based algorithms and propose a simple and efficient way of improving their prediction performance when dealing with data distribution shifts. We exploit the Kronecker-product on the randomly wired search-space and create a small NAS benchmark composed of networks trained over four different datasets. To improve the generalization abilities, we propose GRASP-GCN, a ranking Graph Convolutional Network that takes as additional input the shape of the layers of the neural networks. GRASP-GCN is trained with the not-at-convergence accuracies, and improves the state-of-the-art of 3.3 % for Cifar-10 and increasing moreover the generalization abilities under data distribution shift.
Your Image is My Video: Reshaping the Receptive Field via Image-To-Video Differentiable AutoAugmentation and Fusion
Mar 22, 2024The landscape of deep learning research is moving towards innovative strategies to harness the true potential of data. Traditionally, emphasis has been on scaling model architectures, resulting in large and complex neural networks, which can be difficult to train with limited computational resources. However, independently of the model size, data quality (i.e. amount and variability) is still a major factor that affects model generalization. In this work, we propose a novel technique to exploit available data through the use of automatic data augmentation for the tasks of image classification and semantic segmentation. We introduce the first Differentiable Augmentation Search method (DAS) to generate variations of images that can be processed as videos. Compared to previous approaches, DAS is extremely fast and flexible, allowing the search on very large search spaces in less than a GPU day. Our intuition is that the increased receptive field in the temporal dimension provided by DAS could lead to benefits also to the spatial receptive field. More specifically, we leverage DAS to guide the reshaping of the spatial receptive field by selecting task-dependant transformations. As a result, compared to standard augmentation alternatives, we improve in terms of accuracy on ImageNet, Cifar10, Cifar100, Tiny-ImageNet, Pascal-VOC-2012 and CityScapes datasets when plugging-in our DAS over different light-weight video backbones.
Inductive Attention for Video Action Anticipation
Dec 17, 2022



Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
A Feature-space Multimodal Data Augmentation Technique for Text-video Retrieval
Aug 03, 2022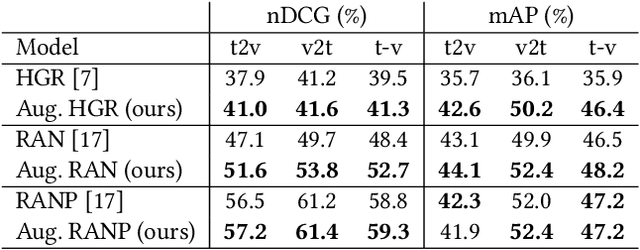

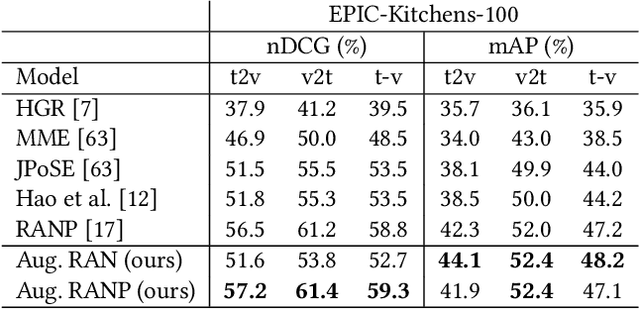
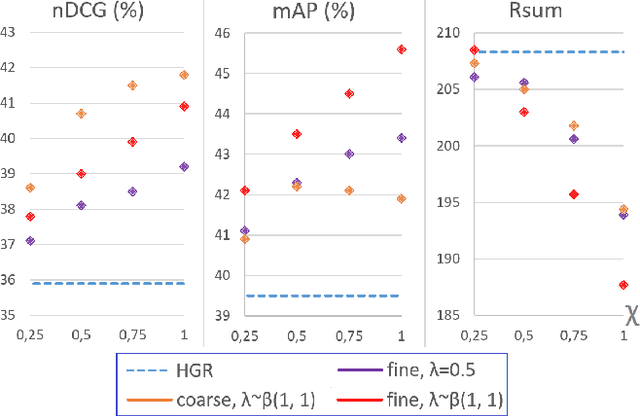
Every hour, huge amounts of visual contents are posted on social media and user-generated content platforms. To find relevant videos by means of a natural language query, text-video retrieval methods have received increased attention over the past few years. Data augmentation techniques were introduced to increase the performance on unseen test examples by creating new training samples with the application of semantics-preserving techniques, such as color space or geometric transformations on images. Yet, these techniques are usually applied on raw data, leading to more resource-demanding solutions and also requiring the shareability of the raw data, which may not always be true, e.g. copyright issues with clips from movies or TV series. To address this shortcoming, we propose a multimodal data augmentation technique which works in the feature space and creates new videos and captions by mixing semantically similar samples. We experiment our solution on a large scale public dataset, EPIC-Kitchens-100, and achieve considerable improvements over a baseline method, improved state-of-the-art performance, while at the same time performing multiple ablation studies. We release code and pretrained models on Github at https://github.com/aranciokov/FSMMDA_VideoRetrieval.
UniUD-FBK-UB-UniBZ Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022
Jun 22, 2022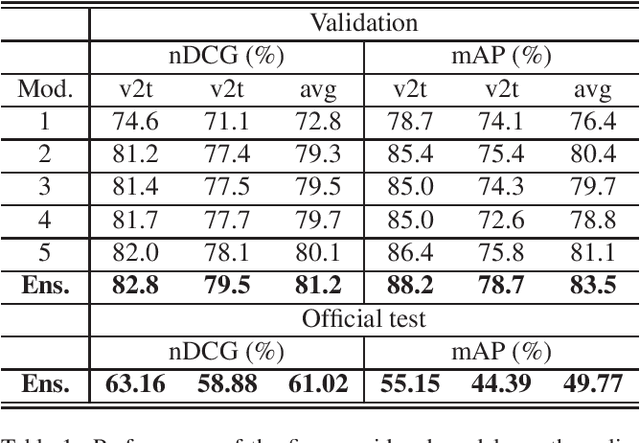
This report presents the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022. To participate in the challenge, we designed an ensemble consisting of different models trained with two recently developed relevance-augmented versions of the widely used triplet loss. Our submission, visible on the public leaderboard, obtains an average score of 61.02% nDCG and 49.77% mAP.