 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaCNOT: Learning CNOT Minimization with Model-Based Planning
Apr 15, 2026Quantum circuit optimization is a central task in Quantum Computing, as current Noisy Intermediate Scale Quantum devices suffer from error propagation that often scales with the number of operations. Among quantum operations, the CNOT gate is of fundamental importance, being the only 2-qubit gate in the universal Clifford+T set. The problem of CNOT gates minimization has been addressed by heuristic algorithms such as the well-known Patel-Markov-Hayes (PMH) for linear reversible synthesis (i.e., CNOT minimization with no topological constraints), and more recently by Reinforcement Learning (RL) based strategies in the more complex case of topology-aware synthesis, where each CNOT can act on a subset of all qubits pairs. In this work we introduce AlphaCNOT, a RL framework based on Monte Carlo Tree Search (MCTS) that address effectively the CNOT minimization problem by modeling it as a planning problem. In contrast to other RL- based solution, our method is model-based, i.e. it can leverage lookahead search to evaluate future trajectories, thus finding more efficient sequences of CNOTs. Our method achieves a reduction of up to 32% in CNOT gate count compared to PMH baseline on linear reversible synthesis, while in the constraint version we report a consistent gate count reduction on a variety of topologies with up to 8 qubits, with respect to state-of-the-art RL-based solutions. Our results suggest the combination of RL with search-based strategies can be applied to different circuit optimization tasks, such as Clifford minimization, thus fostering the transition toward the "quantum utility" era.
Non-Contrastive Vision-Language Learning with Predictive Embedding Alignment
Jan 31, 2026Vision-language models have transformed multimodal representation learning, yet dominant contrastive approaches like CLIP require large batch sizes, careful negative sampling, and extensive hyperparameter tuning. We introduce NOVA, a NOn-contrastive Vision-language Alignment framework based on joint embedding prediction with distributional regularization. NOVA aligns visual representations to a frozen, domain-specific text encoder by predicting text embeddings from augmented image views, while enforcing an isotropic Gaussian structure via Sketched Isotropic Gaussian Regularization (SIGReg). This eliminates the need for negative sampling, momentum encoders, or stop-gradients, reducing the training objective to a single hyperparameter. We evaluate NOVA on zeroshot chest X-ray classification using ClinicalBERT as the text encoder and Vision Transformers trained from scratch on MIMIC-CXR. On zero-shot classification across three benchmark datasets, NOVA outperforms multiple standard baselines while exhibiting substantially more consistent training runs. Our results demonstrate that non-contrastive vision-language pretraining offers a simpler, more stable, and more effective alternative to contrastive methods.
Quantum Circuit Pre-Synthesis: Learning Local Edits to Reduce $T$-count
Jan 27, 2026Compiling quantum circuits into Clifford+$T$ gates is a central task for fault-tolerant quantum computing using stabilizer codes. In the near term, $T$ gates will dominate the cost of fault tolerant implementations, and any reduction in the number of such expensive gates could mean the difference between being able to run a circuit or not. While exact synthesis is exponentially hard in the number of qubits, local synthesis approaches are commonly used to compile large circuits by decomposing them into substructures. However, composing local methods leads to suboptimal compilations in key metrics such as $T$-count or circuit depth, and their performance strongly depends on circuit representation. In this work, we address this challenge by proposing \textsc{Q-PreSyn}, a strategy that, given a set of local edits preserving circuit equivalence, uses a RL agent to identify effective sequences of such actions and thereby obtain circuit representations that yield a reduced $T$-count upon synthesis. Experimental results of our proposed strategy, applied on top of well-known synthesis algorithms, show up to a $20\%$ reduction in $T$-count on circuits with up to 25 qubits, without introducing any additional approximation error prior to synthesis.
BA-BFL: Barycentric Aggregation for Bayesian Federated Learning
Dec 16, 2024



In this work, we study the problem of aggregation in the context of Bayesian Federated Learning (BFL). Using an information geometric perspective, we interpret the BFL aggregation step as finding the barycenter of the trained posteriors for a pre-specified divergence metric. We study the barycenter problem for the parametric family of $\alpha$-divergences and, focusing on the standard case of independent and Gaussian distributed parameters, we recover the closed-form solution of the reverse Kullback-Leibler barycenter and develop the analytical form of the squared Wasserstein-2 barycenter. Considering a non-IID setup, where clients possess heterogeneous data, we analyze the performance of the developed algorithms against state-of-the-art (SOTA) Bayesian aggregation methods in terms of accuracy, uncertainty quantification (UQ), model calibration (MC), and fairness. Finally, we extend our analysis to the framework of Hybrid Bayesian Deep Learning (HBDL), where we study how the number of Bayesian layers in the architecture impacts the considered performance metrics. Our experimental results show that the proposed methodology presents comparable performance with the SOTA while offering a geometric interpretation of the aggregation phase.
Integrated Encoding and Quantization to Enhance Quanvolutional Neural Networks
Oct 08, 2024
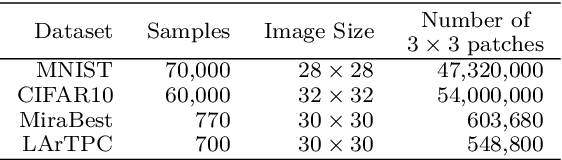


Image processing is one of the most promising applications for quantum machine learning (QML). Quanvolutional Neural Networks with non-trainable parameters are the preferred solution to run on current and near future quantum devices. The typical input preprocessing pipeline for quanvolutional layers comprises of four steps: optional input binary quantization, encoding classical data into quantum states, processing the data to obtain the final quantum states, decoding quantum states back to classical outputs. In this paper we propose two ways to enhance the efficiency of quanvolutional models. First, we propose a flexible data quantization approach with memoization, applicable to any encoding method. This allows us to increase the number of quantization levels to retain more information or lower them to reduce the amount of circuit executions. Second, we introduce a new integrated encoding strategy, which combines the encoding and processing steps in a single circuit. This method allows great flexibility on several architectural parameters (e.g., number of qubits, filter size, and circuit depth) making them adjustable to quantum hardware requirements. We compare our proposed integrated model with a classical convolutional neural network and the well-known rotational encoding method, on two different classification tasks. The results demonstrate that our proposed model encoding exhibits a comparable or superior performance to the other models while requiring fewer quantum resources.
Alternating Minimization Schemes for Computing Rate-Distortion-Perception Functions with $f$-Divergence Perception Constraints
Aug 27, 2024We study the computation of the rate-distortion-perception function (RDPF) for discrete memoryless sources subject to a single-letter average distortion constraint and a perception constraint that belongs to the family of $f$-divergences. In this setting, the RDPF forms a convex programming problem for which we characterize the optimal parametric solutions. We employ the developed solutions in an alternating minimization scheme, namely Optimal Alternating Minimization (OAM), for which we provide convergence guarantees. Nevertheless, the OAM scheme does not lead to a direct implementation of a generalized Blahut-Arimoto (BA) type of algorithm due to the presence of implicit equations in the structure of the iteration. To overcome this difficulty, we propose two alternative minimization approaches whose applicability depends on the smoothness of the used perception metric: a Newton-based Alternating Minimization (NAM) scheme, relying on Newton's root-finding method for the approximation of the optimal iteration solution, and a Relaxed Alternating Minimization (RAM) scheme, based on a relaxation of the OAM iterates. Both schemes are shown, via the derivation of necessary and sufficient conditions, to guarantee convergence to a globally optimal solution. We also provide sufficient conditions on the distortion and the perception constraints which guarantee that the proposed algorithms converge exponentially fast in the number of iteration steps. We corroborate our theoretical results with numerical simulations and draw connections with existing results.
How to Leverage Predictive Uncertainty Estimates for Reducing Catastrophic Forgetting in Online Continual Learning
Jul 10, 2024



Many real-world applications require machine-learning models to be able to deal with non-stationary data distributions and thus learn autonomously over an extended period of time, often in an online setting. One of the main challenges in this scenario is the so-called catastrophic forgetting (CF) for which the learning model tends to focus on the most recent tasks while experiencing predictive degradation on older ones. In the online setting, the most effective solutions employ a fixed-size memory buffer to store old samples used for replay when training on new tasks. Many approaches have been presented to tackle this problem. However, it is not clear how predictive uncertainty information for memory management can be leveraged in the most effective manner and conflicting strategies are proposed to populate the memory. Are the easiest-to-forget or the easiest-to-remember samples more effective in combating CF? Starting from the intuition that predictive uncertainty provides an idea of the samples' location in the decision space, this work presents an in-depth analysis of different uncertainty estimates and strategies for populating the memory. The investigation provides a better understanding of the characteristics data points should have for alleviating CF. Then, we propose an alternative method for estimating predictive uncertainty via the generalised variance induced by the negative log-likelihood. Finally, we demonstrate that the use of predictive uncertainty measures helps in reducing CF in different settings.
An Interpretable Alternative to Neural Representation Learning for Rating Prediction -- Transparent Latent Class Modeling of User Reviews
Jul 02, 2024



Nowadays, neural network (NN) and deep learning (DL) techniques are widely adopted in many applications, including recommender systems. Given the sparse and stochastic nature of collaborative filtering (CF) data, recent works have critically analyzed the effective improvement of neural-based approaches compared to simpler and often transparent algorithms for recommendation. Previous results showed that NN and DL models can be outperformed by traditional algorithms in many tasks. Moreover, given the largely black-box nature of neural-based methods, interpretable results are not naturally obtained. Following on this debate, we first present a transparent probabilistic model that topologically organizes user and product latent classes based on the review information. In contrast to popular neural techniques for representation learning, we readily obtain a statistical, visualization-friendly tool that can be easily inspected to understand user and product characteristics from a textual-based perspective. Then, given the limitations of common embedding techniques, we investigate the possibility of using the estimated interpretable quantities as model input for a rating prediction task. To contribute to the recent debates, we evaluate our results in terms of both capacity for interpretability and predictive performances in comparison with popular text-based neural approaches. The results demonstrate that the proposed latent class representations can yield competitive predictive performances, compared to popular, but difficult-to-interpret approaches.
Federated Continual Learning Goes Online: Leveraging Uncertainty for Modality-Agnostic Class-Incremental Learning
May 29, 2024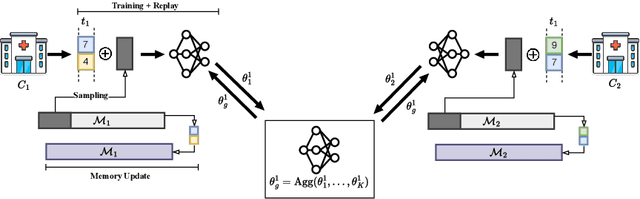
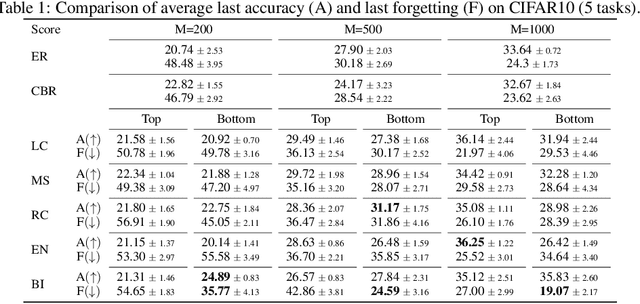
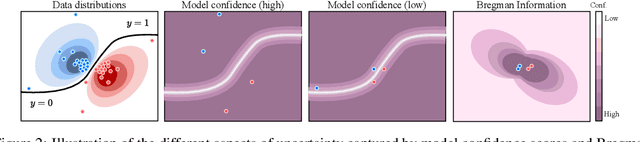
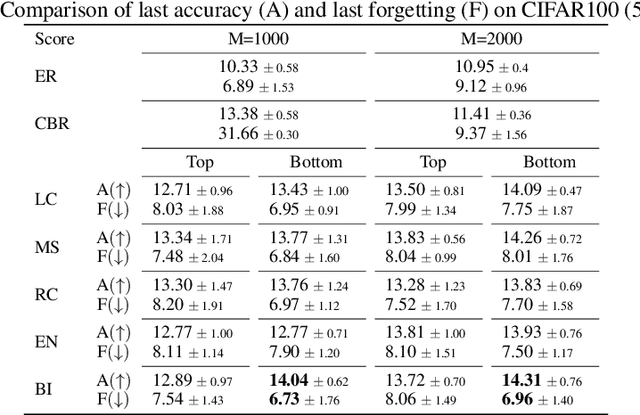
Given the ability to model more realistic and dynamic problems, Federated Continual Learning (FCL) has been increasingly investigated recently. A well-known problem encountered in this setting is the so-called catastrophic forgetting, for which the learning model is inclined to focus on more recent tasks while forgetting the previously learned knowledge. The majority of the current approaches in FCL propose generative-based solutions to solve said problem. However, this setting requires multiple training epochs over the data, implying an offline setting where datasets are stored locally and remain unchanged over time. Furthermore, the proposed solutions are tailored for vision tasks solely. To overcome these limitations, we propose a new modality-agnostic approach to deal with the online scenario where new data arrive in streams of mini-batches that can only be processed once. To solve catastrophic forgetting, we propose an uncertainty-aware memory-based approach. In particular, we suggest using an estimator based on the Bregman Information (BI) to compute the model's variance at the sample level. Through measures of predictive uncertainty, we retrieve samples with specific characteristics, and - by retraining the model on such samples - we demonstrate the potential of this approach to reduce the forgetting effect in realistic settings.
A Language-based solution to enable Metaverse Retrieval
Dec 22, 2023
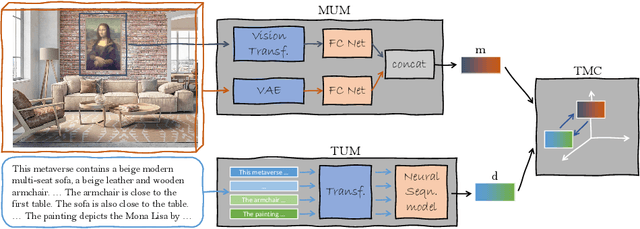

Recently, the Metaverse is becoming increasingly attractive, with millions of users accessing the many available virtual worlds. However, how do users find the one Metaverse which best fits their current interests? So far, the search process is mostly done by word of mouth, or by advertisement on technology-oriented websites. However, the lack of search engines similar to those available for other multimedia formats (e.g., YouTube for videos) is showing its limitations, since it is often cumbersome to find a Metaverse based on some specific interests using the available methods, while also making it difficult to discover user-created ones which lack strong advertisement. To address this limitation, we propose to use language to naturally describe the desired contents of the Metaverse a user wishes to find. Second, we highlight that, differently from more conventional 3D scenes, Metaverse scenarios represent a more complex data format since they often contain one or more types of multimedia which influence the relevance of the scenario itself to a user query. Therefore, in this work, we create a novel task, called Text-to-Metaverse retrieval, which aims at modeling these aspects while also taking the cross-modal relations with the textual data into account. Since we are the first ones to tackle this problem, we also collect a dataset of 33000 Metaverses, each of which consists of a 3D scene enriched with multimedia content. Finally, we design and implement a deep learning framework based on contrastive learning, resulting in a thorough experimental setup.