 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contrastive Vision-Language Learning with Predictive Embedding Alignment
Jan 31, 2026Vision-language models have transformed multimodal representation learning, yet dominant contrastive approaches like CLIP require large batch sizes, careful negative sampling, and extensive hyperparameter tuning. We introduce NOVA, a NOn-contrastive Vision-language Alignment framework based on joint embedding prediction with distributional regularization. NOVA aligns visual representations to a frozen, domain-specific text encoder by predicting text embeddings from augmented image views, while enforcing an isotropic Gaussian structure via Sketched Isotropic Gaussian Regularization (SIGReg). This eliminates the need for negative sampling, momentum encoders, or stop-gradients, reducing the training objective to a single hyperparameter. We evaluate NOVA on zeroshot chest X-ray classification using ClinicalBERT as the text encoder and Vision Transformers trained from scratch on MIMIC-CXR. On zero-shot classification across three benchmark datasets, NOVA outperforms multiple standard baselines while exhibiting substantially more consistent training runs. Our results demonstrate that non-contrastive vision-language pretraining offers a simpler, more stable, and more effective alternative to contrastive methods.
LVLM-Aided Alignment of Task-Specific Vision Models
Dec 26, 2025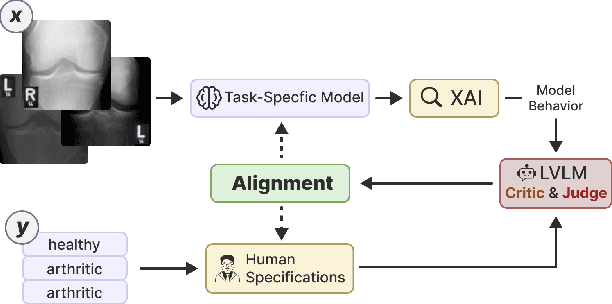
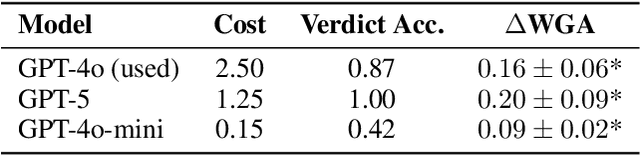
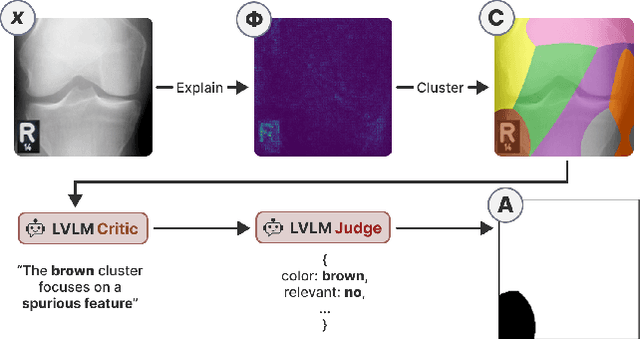

In high-stakes domains, small task-specific vision models are crucial due to their low computational requirements and the availability of numerous methods to explain their results. However, these explanations often reveal that the models do not align well with human domain knowledge, relying instead on spurious correlations. This might result in brittle behavior once deployed in the real-world. To address this issue, we introduce a novel and efficient method for aligning small task-specific vision models with human domain knowledge by leveraging the generalization capabilities of a Large Vision Language Model (LVLM). Our LVLM-Aided Visual Alignment (LVLM-VA) method provides a bidirectional interface that translates model behavior into natural language and maps human class-level specifications to image-level critiques, enabling effective interaction between domain experts and the model. Our method demonstrates substantial improvement in aligning model behavior with human specifications, as validated on both synthetic and real-world datasets. We show that it effectively reduces the model's dependence on spurious features and on group-specific biases, without requiring fine-grained feedback.
Improving Perturbation-based Explanations by Understanding the Role of Uncertainty Calibration
Nov 13, 2025Perturbation-based explanations are widely utilized to enhance the transparency of machine-learning models in practice. However, their reliability is often compromised by the unknown model behavior under the specific perturbations used. This paper investigates the relationship between uncertainty calibration - the alignment of model confidence with actual accuracy - and perturbation-based explanations. We show that models systematically produce unreliable probability estimates when subjected to explainability-specific perturbations and theoretically prove that this directly undermines global and local explanation quality. To address this, we introduce ReCalX, a novel approach to recalibrate models for improved explanations while preserving their original predictions. Empirical evaluations across diverse models and datasets demonstrate that ReCalX consistently reduces perturbation-specific miscalibration most effectively while enhancing explanation robustness and the identification of globally important input features.
Fine-Grained Uncertainty Decomposition in Large Language Models: A Spectral Approach
Sep 26, 2025As Large Language Models (LLMs) are increasingly integrated in diverse applications, obtaining reliable measures of their predictive uncertainty has become critically important. A precise distinction between aleatoric uncertainty, arising from inherent ambiguities within input data, and epistemic uncertainty, originating exclusively from model limitations, is essential to effectively address each uncertainty source. In this paper, we introduce Spectral Uncertainty, a novel approach to quantifying and decomposing uncertainties in LLMs. Leveraging the Von Neumann entropy from quantum information theory, Spectral Uncertainty provides a rigorous theoretical foundation for separating total uncertainty into distinct aleatoric and epistemic components. Unlike existing baseline methods, our approach incorporates a fine-grained representation of semantic similarity, enabling nuanced differentiation among various semantic interpretations in model responses. Empirical evaluations demonstrate that Spectral Uncertainty outperforms state-of-the-art methods in estimating both aleatoric and total uncertainty across diverse models and benchmark datasets.
Why Uncertainty Calibration Matters for Reliable Perturbation-based Explanations
Jun 24, 2025Perturbation-based explanations are widely utilized to enhance the transparency of modern machine-learning models. However, their reliability is often compromised by the unknown model behavior under the specific perturbations used. This paper investigates the relationship between uncertainty calibration - the alignment of model confidence with actual accuracy - and perturbation-based explanations. We show that models frequently produce unreliable probability estimates when subjected to explainability-specific perturbations and theoretically prove that this directly undermines explanation quality. To address this, we introduce ReCalX, a novel approach to recalibrate models for improved perturbation-based explanations while preserving their original predictions. Experiments on popular computer vision models demonstrate that our calibration strategy produces explanations that are more aligned with human perception and actual object locations.
Beyond Overconfidence: Foundation Models Redefine Calibration in Deep Neural Networks
Jun 11, 2025Reliable uncertainty calibration is essential for safely deploying deep neural networks in high-stakes applications. Deep neural networks are known to exhibit systematic overconfidence, especially under distribution shifts. Although foundation models such as ConvNeXt, EVA and BEiT have demonstrated significant improvements in predictive performance, their calibration properties remain underexplored. This paper presents a comprehensive investigation into the calibration behavior of foundation models, revealing insights that challenge established paradigms. Our empirical analysis shows that these models tend to be underconfident in in-distribution predictions, resulting in higher calibration errors, while demonstrating improved calibration under distribution shifts. Furthermore, we demonstrate that foundation models are highly responsive to post-hoc calibration techniques in the in-distribution setting, enabling practitioners to effectively mitigate underconfidence bias. However, these methods become progressively less reliable under severe distribution shifts and can occasionally produce counterproductive results. Our findings highlight the complex, non-monotonic effects of architectural and training innovations on calibration, challenging established narratives of continuous improvement.
Incremental Uncertainty-aware Performance Monitoring with Active Labeling Intervention
May 11, 2025We study the problem of monitoring machine learning models under gradual distribution shifts, where circumstances change slowly over time, often leading to unnoticed yet significant declines in accuracy. To address this, we propose Incremental Uncertainty-aware Performance Monitoring (IUPM), a novel label-free method that estimates performance changes by modeling gradual shifts using optimal transport. In addition, IUPM quantifies the uncertainty in the performance prediction and introduces an active labeling procedure to restore a reliable estimate under a limited labeling budget. Our experiments show that IUPM outperforms existing performance estimation baselines in various gradual shift scenarios and that its uncertainty awareness guides label acquisition more effectively compared to other strategies.
Grasping Partially Occluded Objects Using Autoencoder-Based Point Cloud Inpainting
Mar 16, 2025Flexible industrial production systems will play a central role in the future of manufacturing due to higher product individualization and customization. A key component in such systems is the robotic grasping of known or unknown objects in random positions. Real-world applications often come with challenges that might not be considered in grasping solutions tested in simulation or lab settings. Partial occlusion of the target object is the most prominent. Examples of occlusion can be supporting structures in the camera's field of view, sensor imprecision, or parts occluding each other due to the production process. In all these cases, the resulting lack of information leads to shortcomings in calculating grasping points. In this paper, we present an algorithm to reconstruct the missing information. Our inpainting solution facilitates the real-world utilization of robust object matching approaches for grasping point calculation. We demonstrate the benefit of our solution by enabling an existing grasping system embedded in a real-world industrial application to handle occlusions in the input. With our solution, we drastically decrease the number of objects discarded by the process.
Disentangling Mean Embeddings for Better Diagnostics of Image Generators
Sep 02, 2024The evaluation of image generators remains a challenge due to the limitations of traditional metrics in providing nuanced insights into specific image regions. This is a critical problem as not all regions of an image may be learned with similar ease. In this work, we propose a novel approach to disentangle the cosine similarity of mean embeddings into the product of cosine similarities for individual pixel clusters via central kernel alignment. Consequently, we can quantify the contribution of the cluster-wise performance to the overall image generation performance. We demonstrate how this enhances the explainability and the likelihood of identifying pixel regions of model misbehavior across various real-world use cases.
Explanatory Model Monitoring to Understand the Effects of Feature Shifts on Performance
Aug 24, 2024



Monitoring and maintaining machine learning models are among the most critical challenges in translating recent advances in the field into real-world applications. However, current monitoring methods lack the capability of provide actionable insights answering the question of why the performance of a particular model really degraded. In this work, we propose a novel approach to explain the behavior of a black-box model under feature shifts by attributing an estimated performance change to interpretable input characteristics. We refer to our method that combines concepts from Optimal Transport and Shapley Values as Explanatory Performance Estimation (XPE). We analyze the underlying assumptions and demonstrate the superiority of our approach over several baselines on different data sets across various data modalities such as images, audio, and tabular data. We also indicate how the generated results can lead to valuable insights, enabling explanatory model monitoring by revealing potential root causes for model deterioration and guiding toward actionable countermeasures.