 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Depth Anything: Test-Time Depth Refinement via Self-Supervised Re-lighting
Dec 19, 2025Monocular depth estimation remains challenging as recent foundation models, such as Depth Anything V2 (DA-V2), struggle with real-world images that are far from the training distribution. We introduce Re-Depth Anything, a test-time self-supervision framework that bridges this domain gap by fusing DA-V2 with the powerful priors of large-scale 2D diffusion models. Our method performs label-free refinement directly on the input image by re-lighting predicted depth maps and augmenting the input. This re-synthesis method replaces classical photometric reconstruction by leveraging shape from shading (SfS) cues in a new, generative context with Score Distillation Sampling (SDS). To prevent optimization collapse, our framework employs a targeted optimization strategy: rather than optimizing depth directly or fine-tuning the full model, we freeze the encoder and only update intermediate embeddings while also fine-tuning the decoder. Across diverse benchmarks, Re-Depth Anything yields substantial gains in depth accuracy and realism over the DA-V2, showcasing new avenues for self-supervision by augmenting geometric reasoning.
DreamTexture: Shape from Virtual Texture with Analysis by Augmentation
Mar 20, 2025DreamFusion established a new paradigm for unsupervised 3D reconstruction from virtual views by combining advances in generative models and differentiable rendering. However, the underlying multi-view rendering, along with supervision from large-scale generative models, is computationally expensive and under-constrained. We propose DreamTexture, a novel Shape-from-Virtual-Texture approach that leverages monocular depth cues to reconstruct 3D objects. Our method textures an input image by aligning a virtual texture with the real depth cues in the input, exploiting the inherent understanding of monocular geometry encoded in modern diffusion models. We then reconstruct depth from the virtual texture deformation with a new conformal map optimization, which alleviates memory-intensive volumetric representations. Our experiments reveal that generative models possess an understanding of monocular shape cues, which can be extracted by augmenting and aligning texture cues -- a novel monocular reconstruction paradigm that we call Analysis by Augmentation.
Provably Better Explanations with Optimized Aggregation of Feature Attributions
Jun 07, 2024Using feature attributions for post-hoc explanations is a common practice to understand and verify the predictions of opaque machine learning models. Despite the numerous techniques available, individual methods often produce inconsistent and unstable results, putting their overall reliability into question. In this work, we aim to systematically improve the quality of feature attributions by combining multiple explanations across distinct methods or their variations. For this purpose, we propose a novel approach to derive optimal convex combinations of feature attributions that yield provable improvements of desired quality criteria such as robustness or faithfulness to the model behavior. Through extensive experiments involving various model architectures and popular feature attribution techniques, we demonstrate that our combination strategy consistently outperforms individual methods and existing baselines.
Towards Scenario-based Safety Validation for Autonomous Trains with Deep Generative Models
Oct 16, 2023Modern AI techniques open up ever-increasing possibilities for autonomous vehicles, but how to appropriately verify the reliability of such systems remains unclear. A common approach is to conduct safety validation based on a predefined Operational Design Domain (ODD) describing specific conditions under which a system under test is required to operate properly. However, collecting sufficient realistic test cases to ensure comprehensive ODD coverage is challenging. In this paper, we report our practical experiences regarding the utility of data simulation with deep generative models for scenario-based ODD validation. We consider the specific use case of a camera-based rail-scene segmentation system designed to support autonomous train operation. We demonstrate the capabilities of semantically editing railway scenes with deep generative models to make a limited amount of test data more representative. We also show how our approach helps to analyze the degree to which a system complies with typical ODD requirements. Specifically, we focus on evaluating proper operation under different lighting and weather conditions as well as while transitioning between them.
TriPlaneNet: An Encoder for EG3D Inversion
Mar 23, 2023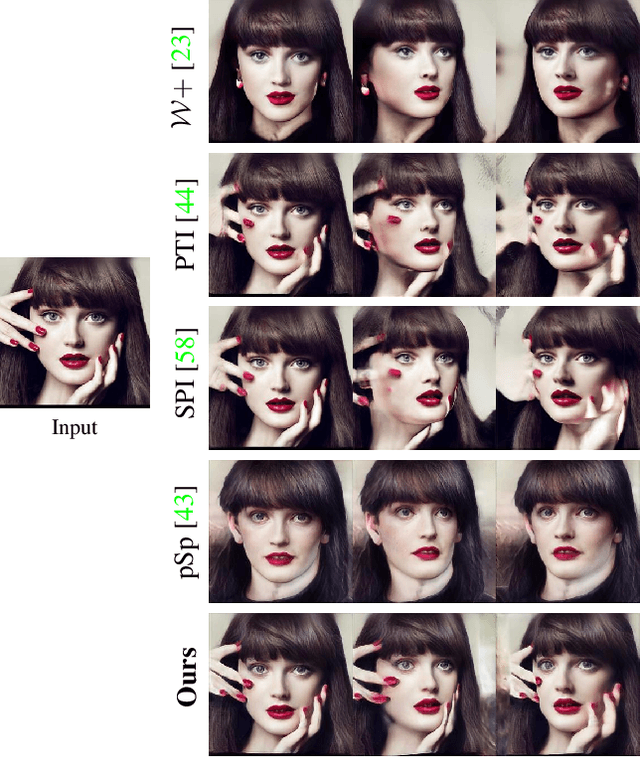
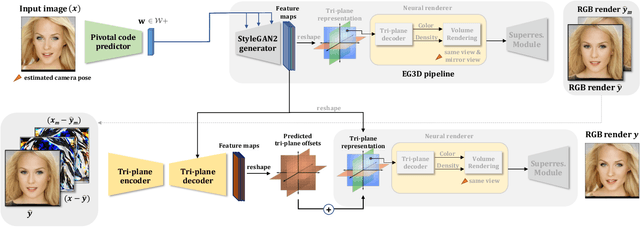
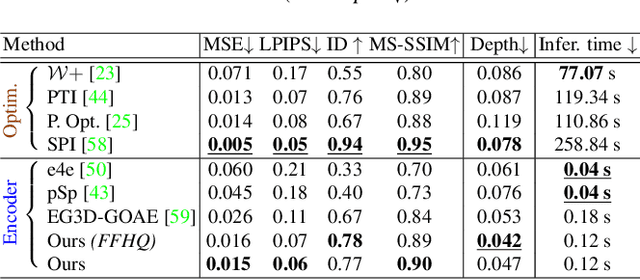

Recent progress in NeRF-based GANs has introduced a number of approaches for high-resolution and high-fidelity generative modeling of human heads with a possibility for novel view rendering. At the same time, one must solve an inverse problem to be able to re-render or modify an existing image or video. Despite the success of universal optimization-based methods for 2D GAN inversion, those, applied to 3D GANs, may fail to produce 3D-consistent renderings. Fast encoder-based techniques, such as those developed for StyleGAN, may also be less appealing due to the lack of identity preservation. In our work, we introduce a real-time method that bridges the gap between the two approaches by directly utilizing the tri-plane representation introduced for EG3D generative model. In particular, we build upon a feed-forward convolutional encoder for the latent code and extend it with a fully-convolutional predictor of tri-plane numerical offsets. As shown in our work, the renderings are similar in quality to optimization-based techniques and significantly outperform the baselines for novel view. As we empirically prove, this is a consequence of directly operating in the tri-plane space, not in the GAN parameter space, while making use of an encoder-based trainable approach.