 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.
GeomHair: Reconstruction of Hair Strands from Colorless 3D Scans
May 08, 2025We propose a novel method that reconstructs hair strands directly from colorless 3D scans by leveraging multi-modal hair orientation extraction. Hair strand reconstruction is a fundamental problem in computer vision and graphics that can be used for high-fidelity digital avatar synthesis, animation, and AR/VR applications. However, accurately recovering hair strands from raw scan data remains challenging due to human hair's complex and fine-grained structure. Existing methods typically rely on RGB captures, which can be sensitive to the environment and can be a challenging domain for extracting the orientation of guiding strands, especially in the case of challenging hairstyles. To reconstruct the hair purely from the observed geometry, our method finds sharp surface features directly on the scan and estimates strand orientation through a neural 2D line detector applied to the renderings of scan shading. Additionally, we incorporate a diffusion prior trained on a diverse set of synthetic hair scans, refined with an improved noise schedule, and adapted to the reconstructed contents via a scan-specific text prompt. We demonstrate that this combination of supervision signals enables accurate reconstruction of both simple and intricate hairstyles without relying on color information. To facilitate further research, we introduce Strands400, the largest publicly available dataset of hair strands with detailed surface geometry extracted from real-world data, which contains reconstructed hair strands from the scans of 400 subjects.
Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars
Feb 27, 2025Traditionally, creating photo-realistic 3D head avatars requires a studio-level multi-view capture setup and expensive optimization during test-time, limiting the use of digital human doubles to the VFX industry or offline renderings. To address this shortcoming, we present Avat3r, which regresses a high-quality and animatable 3D head avatar from just a few input images, vastly reducing compute requirements during inference. More specifically, we make Large Reconstruction Models animatable and learn a powerful prior over 3D human heads from a large multi-view video dataset. For better 3D head reconstructions, we employ position maps from DUSt3R and generalized feature maps from the human foundation model Sapiens. To animate the 3D head, our key discovery is that simple cross-attention to an expression code is already sufficient. Finally, we increase robustness by feeding input images with different expressions to our model during training, enabling the reconstruction of 3D head avatars from inconsistent inputs, e.g., an imperfect phone capture with accidental movement, or frames from a monocular video. We compare Avat3r with current state-of-the-art methods for few-input and single-input scenarios, and find that our method has a competitive advantage in both tasks. Finally, we demonstrate the wide applicability of our proposed model, creating 3D head avatars from images of different sources, smartphone captures, single images, and even out-of-domain inputs like antique busts. Project website: https://tobias-kirschstein.github.io/avat3r/
GaussianSpeech: Audio-Driven Gaussian Avatars
Nov 27, 2024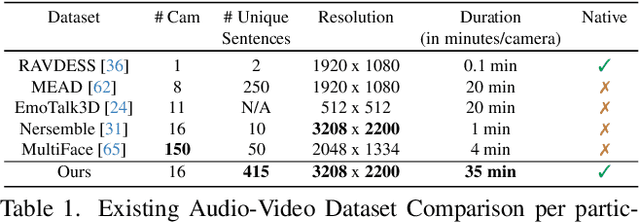
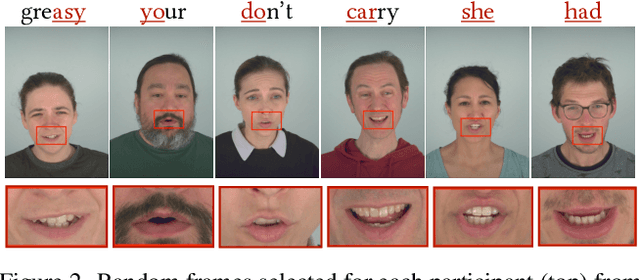
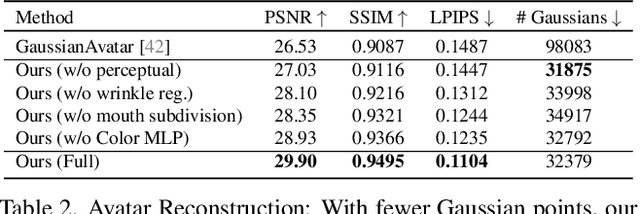
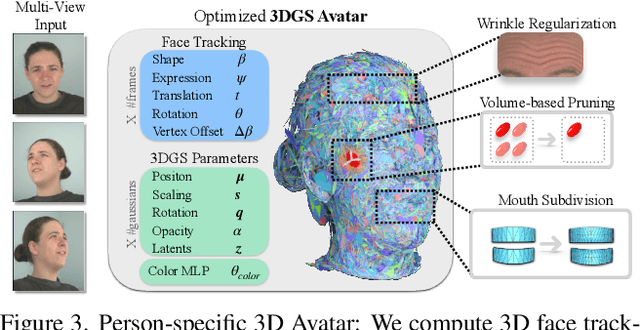
We introduce GaussianSpeech, a novel approach that synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. To capture the expressive, detailed nature of human heads, including skin furrowing and finer-scale facial movements, we propose to couple speech signal with 3D Gaussian splatting to create realistic, temporally coherent motion sequences. We propose a compact and efficient 3DGS-based avatar representation that generates expression-dependent color and leverages wrinkle- and perceptually-based losses to synthesize facial details, including wrinkles that occur with different expressions. To enable sequence modeling of 3D Gaussian splats with audio, we devise an audio-conditioned transformer model capable of extracting lip and expression features directly from audio input. Due to the absence of high-quality datasets of talking humans in correspondence with audio, we captured a new large-scale multi-view dataset of audio-visual sequences of talking humans with native English accents and diverse facial geometry. GaussianSpeech consistently achieves state-of-the-art performance with visually natural motion at real time rendering rates, while encompassing diverse facial expressions and styles.
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
TriPlaneNet: An Encoder for EG3D Inversion
Mar 23, 2023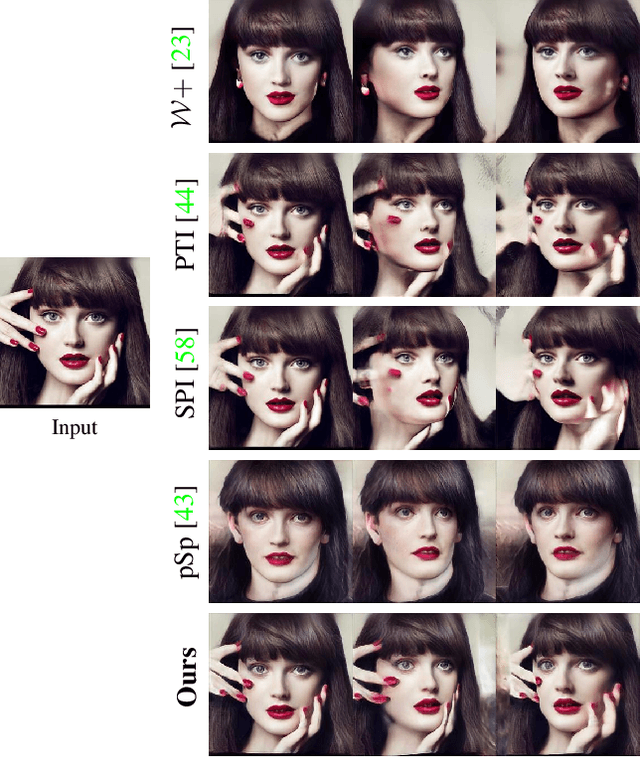
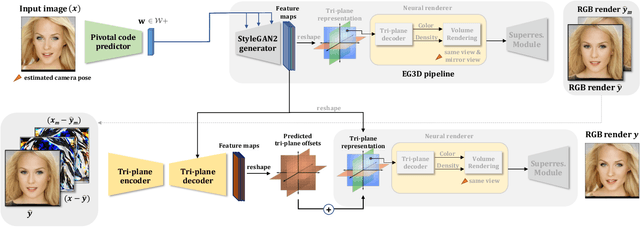
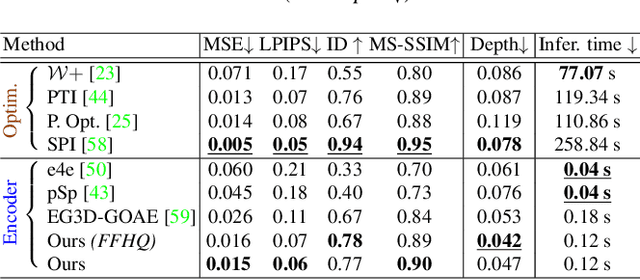

Recent progress in NeRF-based GANs has introduced a number of approaches for high-resolution and high-fidelity generative modeling of human heads with a possibility for novel view rendering. At the same time, one must solve an inverse problem to be able to re-render or modify an existing image or video. Despite the success of universal optimization-based methods for 2D GAN inversion, those, applied to 3D GANs, may fail to produce 3D-consistent renderings. Fast encoder-based techniques, such as those developed for StyleGAN, may also be less appealing due to the lack of identity preservation. In our work, we introduce a real-time method that bridges the gap between the two approaches by directly utilizing the tri-plane representation introduced for EG3D generative model. In particular, we build upon a feed-forward convolutional encoder for the latent code and extend it with a fully-convolutional predictor of tri-plane numerical offsets. As shown in our work, the renderings are similar in quality to optimization-based techniques and significantly outperform the baselines for novel view. As we empirically prove, this is a consequence of directly operating in the tri-plane space, not in the GAN parameter space, while making use of an encoder-based trainable approach.
How to Boost Face Recognition with StyleGAN?
Oct 18, 2022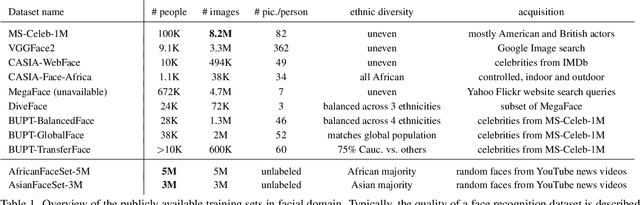
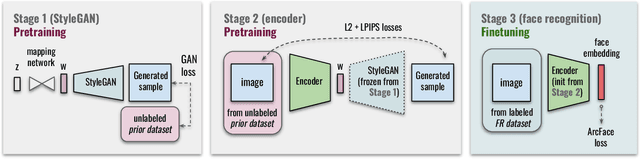
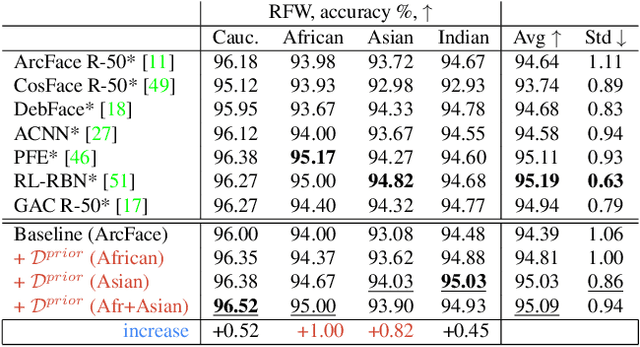

State-of-the-art face recognition systems require huge amounts of labeled training data. Given the priority of privacy in face recognition applications, the data is limited to celebrity web crawls, which have issues such as skewed distributions of ethnicities and limited numbers of identities. On the other hand, the self-supervised revolution in the industry motivates research on adaptation of the related techniques to facial recognition. One of the most popular practical tricks is to augment the dataset by the samples drawn from the high-resolution high-fidelity models (e.g. StyleGAN-like), while preserving the identity. We show that a simple approach based on fine-tuning an encoder for StyleGAN allows to improve upon the state-of-the-art facial recognition and performs better compared to training on synthetic face identities. We also collect large-scale unlabeled datasets with controllable ethnic constitution -- AfricanFaceSet-5M (5 million images of different people) and AsianFaceSet-3M (3 million images of different people) and we show that pretraining on each of them improves recognition of the respective ethnicities (as well as also others), while combining all unlabeled datasets results in the biggest performance increase. Our self-supervised strategy is the most useful with limited amounts of labeled training data, which can be beneficial for more tailored face recognition tasks and when facing privacy concerns. Evaluation is provided based on a standard RFW dataset and a new large-scale RB-WebFace benchmark.
Relightable 3D Head Portraits from a Smartphone Video
Dec 17, 2020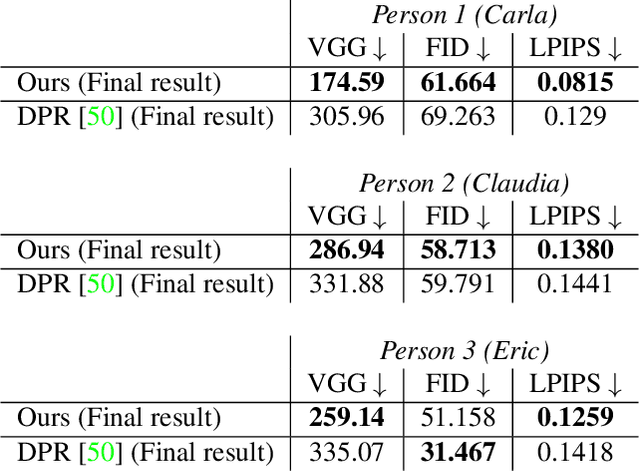
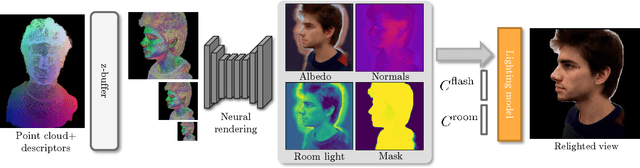


In this work, a system for creating a relightable 3D portrait of a human head is presented. Our neural pipeline operates on a sequence of frames captured by a smartphone camera with the flash blinking (flash-no flash sequence). A coarse point cloud reconstructed via structure-from-motion software and multi-view denoising is then used as a geometric proxy. Afterwards, a deep rendering network is trained to regress dense albedo, normals, and environmental lighting maps for arbitrary new viewpoints. Effectively, the proxy geometry and the rendering network constitute a relightable 3D portrait model, that can be synthesized from an arbitrary viewpoint and under arbitrary lighting, e.g. directional light, point light, or an environment map. The model is fitted to the sequence of frames with human face-specific priors that enforce the plausibility of albedo-lighting decomposition and operates at the interactive frame rate. We evaluate the performance of the method under varying lighting conditions and at the extrapolated viewpoints and compare with existing relighting methods.
TRANSPR: Transparency Ray-Accumulating Neural 3D Scene Point Renderer
Sep 06, 2020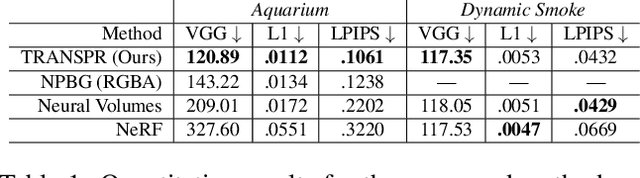
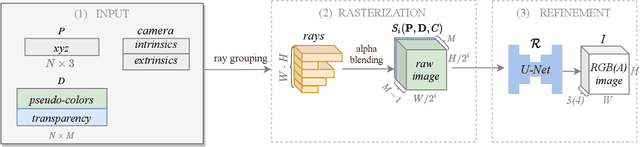
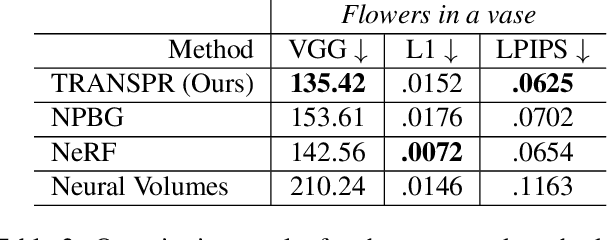
We propose and evaluate a neural point-based graphics method that can model semi-transparent scene parts. Similarly to its predecessor pipeline, ours uses point clouds to model proxy geometry, and augments each point with a neural descriptor. Additionally, a learnable transparency value is introduced in our approach for each point. Our neural rendering procedure consists of two steps. Firstly, the point cloud is rasterized using ray grouping into a multi-channel image. This is followed by the neural rendering step that "translates" the rasterized image into an RGB output using a learnable convolutional network. New scenes can be modeled using gradient-based optimization of neural descriptors and of the rendering network. We show that novel views of semi-transparent point cloud scenes can be generated after training with our approach. Our experiments demonstrate the benefit of introducing semi-transparency into the neural point-based modeling for a range of scenes with semi-transparent parts.
Coordinate-based Texture Inpainting for Pose-Guided Image Generation
Nov 28, 2018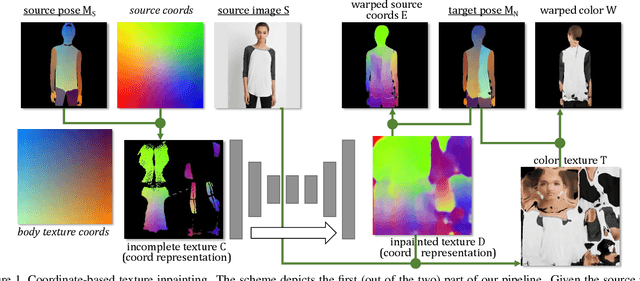



We present a new deep learning approach to pose-guided resynthesis of human photographs. At the heart of the new approach is the estimation of the complete body surface texture based on a single photograph. Since the input photograph always observes only a part of the surface, we suggest a new inpainting method that completes the texture of the human body. Rather than working directly with colors of texture elements, the inpainting network estimates an appropriate source location in the input image for each element of the body surface. This correspondence field between the input image and the texture is then further warped into the target image coordinate frame based on the desired pose, effectively establishing the correspondence between the source and the target view even when the pose change is drastic. The final convolutional network then uses the established correspondence and all other available information to synthesize the output image using a fully-convolutional architecture with deformable convolutions. We show the state-of-the-art result for pose-guided image synthesis. Additionally, we demonstrate the performance of our system for garment transfer and pose-guided face resynthesis.