 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralFur: Animal Fur Reconstruction From Multi-View Images
Jan 18, 2026Reconstructing realistic animal fur geometry from images is a challenging task due to the fine-scale details, self-occlusion, and view-dependent appearance of fur. In contrast to human hairstyle reconstruction, there are also no datasets that can be leveraged to learn a fur prior for different animals. In this work, we present a first multi-view-based method for high-fidelity 3D fur modeling of animals using a strand-based representation, leveraging the general knowledge of a vision language model. Given multi-view RGB images, we first reconstruct a coarse surface geometry using traditional multi-view stereo techniques. We then use a vision language model (VLM) system to retrieve information about the realistic length structure of the fur for each part of the body. We use this knowledge to construct the animal's furless geometry and grow strands atop it. The fur reconstruction is supervised with both geometric and photometric losses computed from multi-view images. To mitigate orientation ambiguities stemming from the Gabor filters that are applied to the input images, we additionally utilize the VLM to guide the strands' growth direction and their relation to the gravity vector that we incorporate as a loss. With this new schema of using a VLM to guide 3D reconstruction from multi-view inputs, we show generalization across a variety of animals with different fur types. For additional results and code, please refer to https://neuralfur.is.tue.mpg.de.
3D Blood Pulsation Maps
Dec 11, 2025We present Pulse3DFace, the first dataset of its kind for estimating 3D blood pulsation maps. These maps can be used to develop models of dynamic facial blood pulsation, enabling the creation of synthetic video data to improve and validate remote pulse estimation methods via photoplethysmography imaging. Additionally, the dataset facilitates research into novel multi-view-based approaches for mitigating illumination effects in blood pulsation analysis. Pulse3DFace consists of raw videos from 15 subjects recorded at 30 Hz with an RGB camera from 23 viewpoints, blood pulse reference measurements, and facial 3D scans generated using monocular structure-from-motion techniques. It also includes processed 3D pulsation maps compatible with the texture space of the 3D head model FLAME. These maps provide signal-to-noise ratio, local pulse amplitude, phase information, and supplementary data. We offer a comprehensive evaluation of the dataset's illumination conditions, map consistency, and its ability to capture physiologically meaningful features in the facial and neck skin regions.
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Jan 12, 2025We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
GaussianSpeech: Audio-Driven Gaussian Avatars
Nov 27, 2024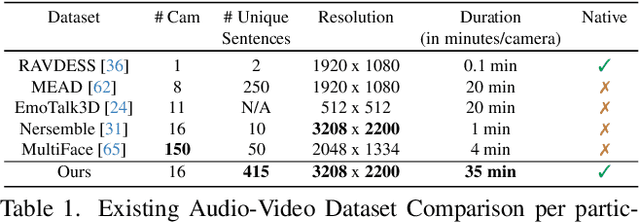
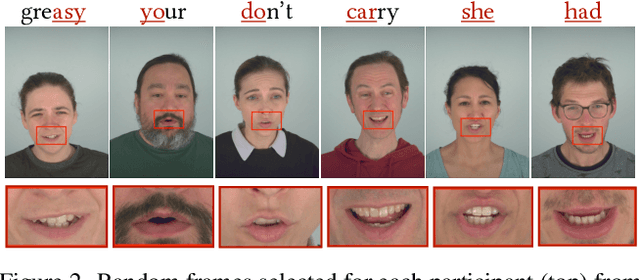
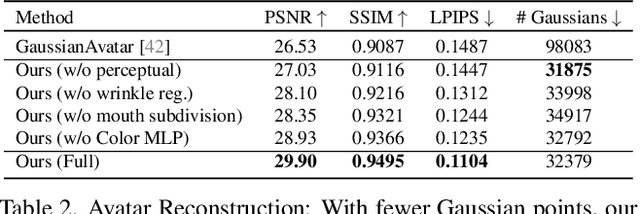
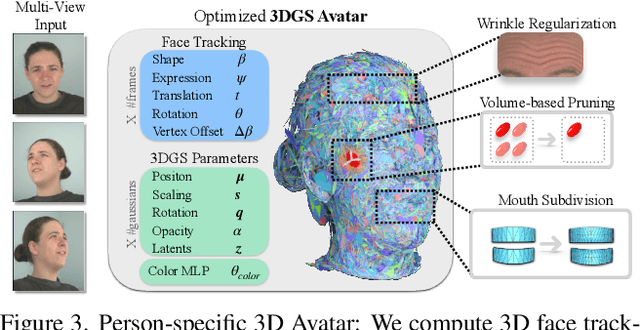
We introduce GaussianSpeech, a novel approach that synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. To capture the expressive, detailed nature of human heads, including skin furrowing and finer-scale facial movements, we propose to couple speech signal with 3D Gaussian splatting to create realistic, temporally coherent motion sequences. We propose a compact and efficient 3DGS-based avatar representation that generates expression-dependent color and leverages wrinkle- and perceptually-based losses to synthesize facial details, including wrinkles that occur with different expressions. To enable sequence modeling of 3D Gaussian splats with audio, we devise an audio-conditioned transformer model capable of extracting lip and expression features directly from audio input. Due to the absence of high-quality datasets of talking humans in correspondence with audio, we captured a new large-scale multi-view dataset of audio-visual sequences of talking humans with native English accents and diverse facial geometry. GaussianSpeech consistently achieves state-of-the-art performance with visually natural motion at real time rendering rates, while encompassing diverse facial expressions and styles.
Joker: Conditional 3D Head Synthesis with Extreme Facial Expressions
Oct 21, 2024



We introduce Joker, a new method for the conditional synthesis of 3D human heads with extreme expressions. Given a single reference image of a person, we synthesize a volumetric human head with the reference identity and a new expression. We offer control over the expression via a 3D morphable model (3DMM) and textual inputs. This multi-modal conditioning signal is essential since 3DMMs alone fail to define subtle emotional changes and extreme expressions, including those involving the mouth cavity and tongue articulation. Our method is built upon a 2D diffusion-based prior that generalizes well to out-of-domain samples, such as sculptures, heavy makeup, and paintings while achieving high levels of expressiveness. To improve view consistency, we propose a new 3D distillation technique that converts predictions of our 2D prior into a neural radiance field (NeRF). Both the 2D prior and our distillation technique produce state-of-the-art results, which are confirmed by our extensive evaluations. Also, to the best of our knowledge, our method is the first to achieve view-consistent extreme tongue articulation.
Stable Video Portraits
Sep 26, 2024



Rapid advances in the field of generative AI and text-to-image methods in particular have transformed the way we interact with and perceive computer-generated imagery today. In parallel, much progress has been made in 3D face reconstruction, using 3D Morphable Models (3DMM). In this paper, we present SVP, a novel hybrid 2D/3D generation method that outputs photorealistic videos of talking faces leveraging a large pre-trained text-to-image prior (2D), controlled via a 3DMM (3D). Specifically, we introduce a person-specific fine-tuning of a general 2D stable diffusion model which we lift to a video model by providing temporal 3DMM sequences as conditioning and by introducing a temporal denoising procedure. As an output, this model generates temporally smooth imagery of a person with 3DMM-based controls, i.e., a person-specific avatar. The facial appearance of this person-specific avatar can be edited and morphed to text-defined celebrities, without any fine-tuning at test time. The method is analyzed quantitatively and qualitatively, and we show that our method outperforms state-of-the-art monocular head avatar methods.
Gaussian Eigen Models for Human Heads
Jul 05, 2024

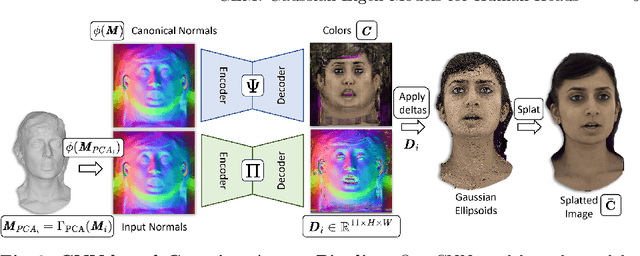
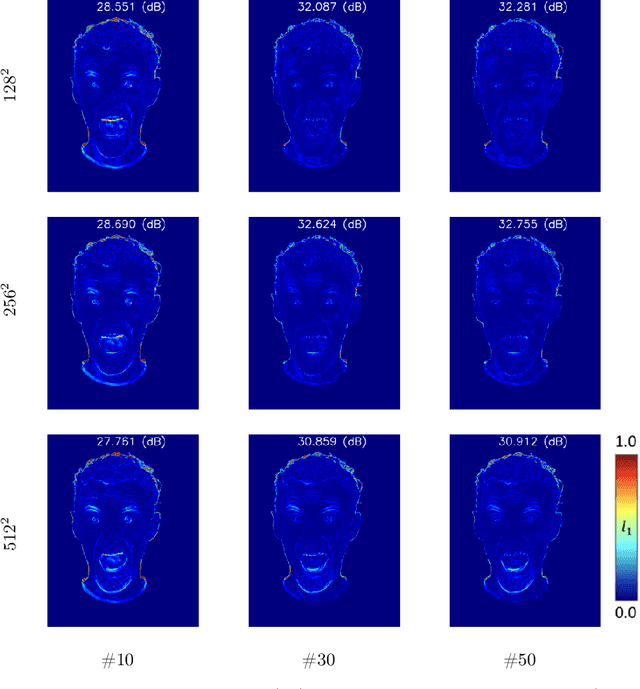
We present personalized Gaussian Eigen Models (GEMs) for human heads, a novel method that compresses dynamic 3D Gaussians into low-dimensional linear spaces. Our approach is inspired by the seminal work of Blanz and Vetter, where a mesh-based 3D morphable model (3DMM) is constructed from registered meshes. Based on dynamic 3D Gaussians, we create a lower-dimensional representation of primitives that applies to most 3DGS head avatars. Specifically, we propose a universal method to distill the appearance of a mesh-controlled UNet Gaussian avatar using an ensemble of linear eigenbasis. We replace heavy CNN-based architectures with a single linear layer improving speed and enabling a range of real-time downstream applications. To create a particular facial expression, one simply needs to perform a dot product between the eigen coefficients and the distilled basis. This efficient method removes the requirement for an input mesh during testing, enhancing simplicity and speed in expression generation. This process is highly efficient and supports real-time rendering on everyday devices, leveraging the effectiveness of standard Gaussian Splatting. In addition, we demonstrate how the GEM can be controlled using a ResNet-based regression architecture. We show and compare self-reenactment and cross-person reenactment to state-of-the-art 3D avatar methods, demonstrating higher quality and better control. A real-time demo showcases the applicability of the GEM representation.
Generating Human Interaction Motions in Scenes with Text Control
Apr 16, 2024We present TeSMo, a method for text-controlled scene-aware motion generation based on denoising diffusion models. Previous text-to-motion methods focus on characters in isolation without considering scenes due to the limited availability of datasets that include motion, text descriptions, and interactive scenes. Our approach begins with pre-training a scene-agnostic text-to-motion diffusion model, emphasizing goal-reaching constraints on large-scale motion-capture datasets. We then enhance this model with a scene-aware component, fine-tuned using data augmented with detailed scene information, including ground plane and object shapes. To facilitate training, we embed annotated navigation and interaction motions within scenes. The proposed method produces realistic and diverse human-object interactions, such as navigation and sitting, in different scenes with various object shapes, orientations, initial body positions, and poses. Extensive experiments demonstrate that our approach surpasses prior techniques in terms of the plausibility of human-scene interactions, as well as the realism and variety of the generated motions. Code will be released upon publication of this work at https://research.nvidia.com/labs/toronto-ai/tesmo.
Environment-Specific People
Dec 22, 2023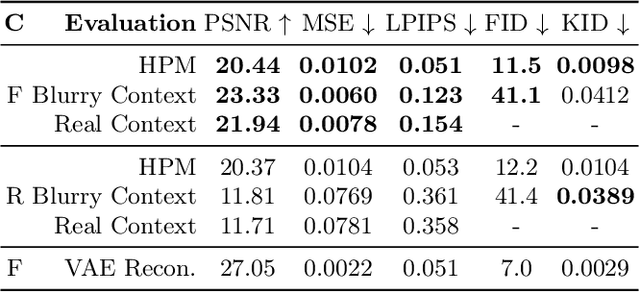
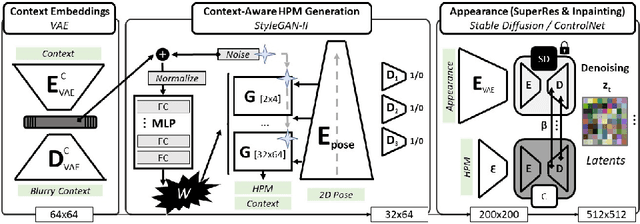

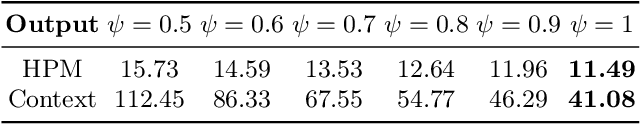
Despite significant progress in generative image synthesis and full-body generation in particular, state-of-the-art methods are either context-independent, overly reliant to text prompts, or bound to the curated training datasets, such as fashion images with monotonous backgrounds. Here, our goal is to generate people in clothing that is semantically appropriate for a given scene. To this end, we present ESP, a novel method for context-aware full-body generation, that enables photo-realistic inpainting of people into existing "in-the-wild" photographs. ESP is conditioned on a 2D pose and contextual cues that are extracted from the environment photograph and integrated into the generation process. Our models are trained on a dataset containing a set of in-the-wild photographs of people covering a wide range of different environments. The method is analyzed quantitatively and qualitatively, and we show that ESP outperforms state-of-the-art on the task of contextual full-body generation.
HAAR: Text-Conditioned Generative Model of 3D Strand-based Human Hairstyles
Dec 18, 2023We present HAAR, a new strand-based generative model for 3D human hairstyles. Specifically, based on textual inputs, HAAR produces 3D hairstyles that could be used as production-level assets in modern computer graphics engines. Current AI-based generative models take advantage of powerful 2D priors to reconstruct 3D content in the form of point clouds, meshes, or volumetric functions. However, by using the 2D priors, they are intrinsically limited to only recovering the visual parts. Highly occluded hair structures can not be reconstructed with those methods, and they only model the ''outer shell'', which is not ready to be used in physics-based rendering or simulation pipelines. In contrast, we propose a first text-guided generative method that uses 3D hair strands as an underlying representation. Leveraging 2D visual question-answering (VQA) systems, we automatically annotate synthetic hair models that are generated from a small set of artist-created hairstyles. This allows us to train a latent diffusion model that operates in a common hairstyle UV space. In qualitative and quantitative studies, we demonstrate the capabilities of the proposed model and compare it to existing hairstyle generation approaches.