 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoRelight: Egocentric Human Capture and Illumination Recovery for Relightable and Photoreal Avatar Rendering
May 27, 2026Mixed Reality (MR) headsets promise a future of immersive telepresence where virtual humans blend indistinguishably into real or virtual surroundings. Achieving this vision requires a method for capturing a user's motion, estimating appearance under novel lighting, and understanding the environment - all from the constrained viewpoint of a head-mounted display (HMD). Existing approaches treat these as isolated problems: they either focus on driving avatars with baked-in lighting or rely on studio setups for relighting. In this paper, we present EgoRelight, a holistic framework for egocentric telepresence that simultaneously captures full-body human performance, synthesizes photorealistic and relightable appearance, and estimates high dynamic range (HDR) environment maps from a single HMD. First, to ensure motion and surface reconstruction, we propose an egocentric perception module that leverages stereo down-facing cameras to extract dense depth maps, which serve as geometric control signals to drive a mesh-based avatar. Second, we introduce a novel neural appearance model that learns to synthesize view-dependent specular and view-independent diffuse shading separately. By employing a specialized ray-sampling strategy, our model generalizes to unseen illumination without relying on restrictive analytical BRDF priors. Third, we enable seamless avatar integration into the physical world via a test-time inverse rendering process, which recovers an HDR environment map by matching the pre-trained avatar's appearance to live egocentric camera observations. We demonstrate our system through a social telepresence application, where remote users are coherently relit according to their physical environment. Extensive experiments show that our components and the integrated system significantly outperform state-of-the-art baselines in geometric accuracy and rendering as well as relighting fidelity.
3DRealHead: Few-Shot Detailed Head Avatar
Apr 14, 2026The human face is central to communication. For immersive applications, the digital presence of a person should mirror the physical reality, capturing the users idiosyncrasies and detailed facial expressions. However, current 3D head avatar methods often struggle to faithfully reproduce the identity and facial expressions, despite having multi-view data or learned priors. Learning priors that capture the diversity of human appearances, especially, for regions with highly person-specific features, like the mouth and teeth region is challenging as the underlying training data is limited. In addition, many of the avatar methods are purely relying on 3D morphable model-based expression control which strongly limits expressivity. To address these challenges, we are introducing 3DRealHead, a few-shot head avatar reconstruction method with a novel expression control signal that is extracted from a monocular video stream of the subject. Specifically, the subject can take a few pictures of themselves, recover a 3D head avatar and drive it with a consumer-level webcam. The avatar reconstruction is enabled via a novel few-shot inversion process of a 3D human head prior which is represented as a Style U-Net that emits 3D Gaussian primitives which can be rendered under novel views. The prior is learned on the NeRSemble dataset. For animating the avatar, the U-Net is conditioned on 3DMM-based facial expression signals, as well as features of the mouth region extracted from the driving video. These additional mouth features allow us to recover facial expressions that cannot be represented by the 3DMM leading to a higher expressivity and closer resemblance to the physical reality.
Grasp in Gaussians: Fast Monocular Reconstruction of Dynamic Hand-Object Interactions
Apr 14, 2026We present Grasp in Gaussians (GraG), a fast and robust method for reconstructing dynamic 3D hand-object interactions from a single monocular video. Unlike recent approaches that optimize heavy neural representations, our method focuses on tracking the hand and the object efficiently, once initialized from pretrained large models. Our key insight is that accurate and temporally stable hand-object motion can be recovered using a compact Sum-of-Gaussians (SoG) representation, revived from classical tracking literature and integrated with generative Gaussian-based initializations. We initialize object pose and geometry using a video-adapted SAM3D pipeline, then convert the resulting dense Gaussian representation into a lightweight SoG via subsampling. This compact representation enables efficient and fast tracking while preserving geometric fidelity. For the hand, we adopt a complementary strategy: starting from off-the-shelf monocular hand pose initialization, we refine hand motion using simple yet effective 2D joint and depth alignment losses, avoiding per-frame refinement of a detailed 3D hand appearance model while maintaining stable articulation. Extensive experiments on public benchmarks demonstrate that GraG reconstructs temporally coherent hand-object interactions on long sequences 6.4x faster than prior work while improving object reconstruction by 13.4% and reducing hand's per-joint position error by over 65%.
LegacyAvatars: Volumetric Face Avatars For Traditional Graphics Pipelines
Jan 18, 2026We introduce a novel representation for efficient classical rendering of photorealistic 3D face avatars. Leveraging recent advances in radiance fields anchored to parametric face models, our approach achieves controllable volumetric rendering of complex facial features, including hair, skin, and eyes. At enrollment time, we learn a set of radiance manifolds in 3D space to extract an explicit layered mesh, along with appearance and warp textures. During deployment, this allows us to control and animate the face through simple linear blending and alpha compositing of textures over a static mesh. This explicit representation also enables the generated avatar to be efficiently streamed online and then rendered using classical mesh and shader-based rendering on legacy graphics platforms, eliminating the need for any custom engineering or integration.
Image2Garment: Simulation-ready Garment Generation from a Single Image
Jan 15, 2026Estimating physically accurate, simulation-ready garments from a single image is challenging due to the absence of image-to-physics datasets and the ill-posed nature of this problem. Prior methods either require multi-view capture and expensive differentiable simulation or predict only garment geometry without the material properties required for realistic simulation. We propose a feed-forward framework that sidesteps these limitations by first fine-tuning a vision-language model to infer material composition and fabric attributes from real images, and then training a lightweight predictor that maps these attributes to the corresponding physical fabric parameters using a small dataset of material-physics measurements. Our approach introduces two new datasets (FTAG and T2P) and delivers simulation-ready garments from a single image without iterative optimization. Experiments show that our estimator achieves superior accuracy in material composition estimation and fabric attribute prediction, and by passing them through our physics parameter estimator, we further achieve higher-fidelity simulations compared to state-of-the-art image-to-garment methods.
VHOI: Controllable Video Generation of Human-Object Interactions from Sparse Trajectories via Motion Densification
Dec 10, 2025Synthesizing realistic human-object interactions (HOI) in video is challenging due to the complex, instance-specific interaction dynamics of both humans and objects. Incorporating controllability in video generation further adds to the complexity. Existing controllable video generation approaches face a trade-off: sparse controls like keypoint trajectories are easy to specify but lack instance-awareness, while dense signals such as optical flow, depths or 3D meshes are informative but costly to obtain. We propose VHOI, a two-stage framework that first densifies sparse trajectories into HOI mask sequences, and then fine-tunes a video diffusion model conditioned on these dense masks. We introduce a novel HOI-aware motion representation that uses color encodings to distinguish not only human and object motion, but also body-part-specific dynamics. This design incorporates a human prior into the conditioning signal and strengthens the model's ability to understand and generate realistic HOI dynamics. Experiments demonstrate state-of-the-art results in controllable HOI video generation. VHOI is not limited to interaction-only scenarios and can also generate full human navigation leading up to object interactions in an end-to-end manner. Project page: https://vcai.mpi-inf.mpg.de/projects/vhoi/.
ECHO: Ego-Centric modeling of Human-Object interactions
Aug 29, 2025
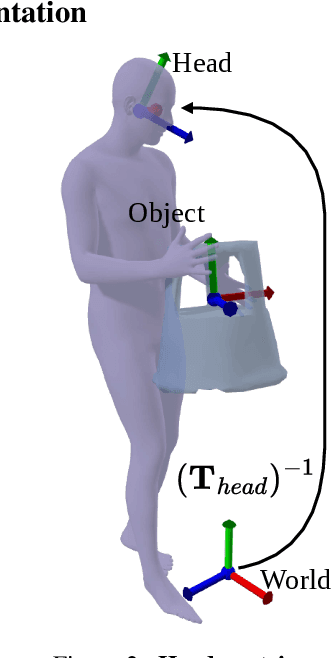
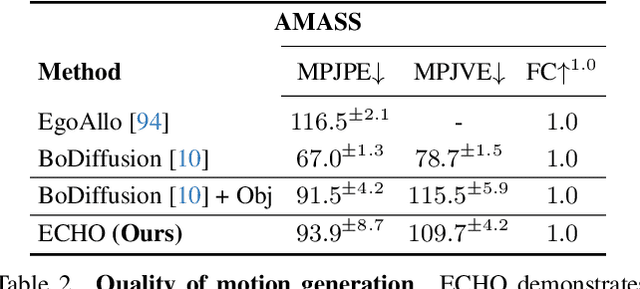
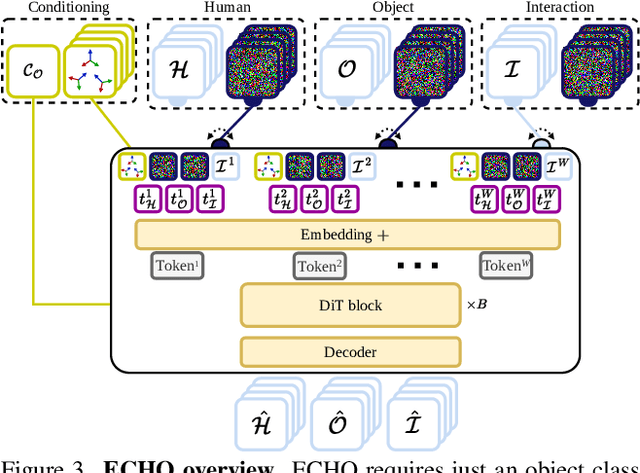
Modeling human-object interactions (HOI) from an egocentric perspective is a largely unexplored yet important problem due to the increasing adoption of wearable devices, such as smart glasses and watches. We investigate how much information about interaction can be recovered from only head and wrists tracking. Our answer is ECHO (Ego-Centric modeling of Human-Object interactions), which, for the first time, proposes a unified framework to recover three modalities: human pose, object motion, and contact from such minimal observation. ECHO employs a Diffusion Transformer architecture and a unique three-variate diffusion process, which jointly models human motion, object trajectory, and contact sequence, allowing for flexible input configurations. Our method operates in a head-centric canonical space, enhancing robustness to global orientation. We propose a conveyor-based inference, which progressively increases the diffusion timestamp with the frame position, allowing us to process sequences of any length. Through extensive evaluation, we demonstrate that ECHO outperforms existing methods that do not offer the same flexibility, setting a state-of-the-art in egocentric HOI reconstruction.
TeGA: Texture Space Gaussian Avatars for High-Resolution Dynamic Head Modeling
May 08, 2025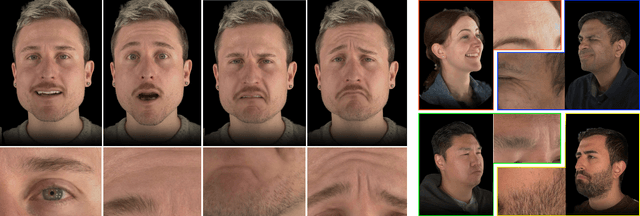
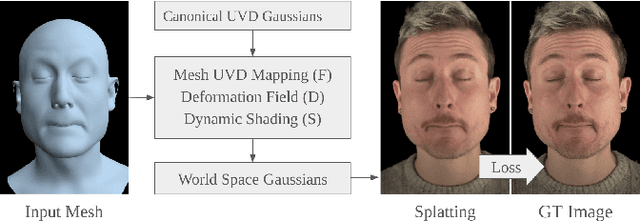


Sparse volumetric reconstruction and rendering via 3D Gaussian splatting have recently enabled animatable 3D head avatars that are rendered under arbitrary viewpoints with impressive photorealism. Today, such photoreal avatars are seen as a key component in emerging applications in telepresence, extended reality, and entertainment. Building a photoreal avatar requires estimating the complex non-rigid motion of different facial components as seen in input video images; due to inaccurate motion estimation, animatable models typically present a loss of fidelity and detail when compared to their non-animatable counterparts, built from an individual facial expression. Also, recent state-of-the-art models are often affected by memory limitations that reduce the number of 3D Gaussians used for modeling, leading to lower detail and quality. To address these problems, we present a new high-detail 3D head avatar model that improves upon the state of the art, largely increasing the number of 3D Gaussians and modeling quality for rendering at 4K resolution. Our high-quality model is reconstructed from multiview input video and builds on top of a mesh-based 3D morphable model, which provides a coarse deformation layer for the head. Photoreal appearance is modelled by 3D Gaussians embedded within the continuous UVD tangent space of this mesh, allowing for more effective densification where most needed. Additionally, these Gaussians are warped by a novel UVD deformation field to capture subtle, localized motion. Our key contribution is the novel deformable Gaussian encoding and overall fitting procedure that allows our head model to preserve appearance detail, while capturing facial motion and other transient high-frequency features such as skin wrinkling.
Pixels2Points: Fusing 2D and 3D Features for Facial Skin Segmentation
Apr 28, 2025Face registration deforms a template mesh to closely fit a 3D face scan, the quality of which commonly degrades in non-skin regions (e.g., hair, beard, accessories), because the optimized template-to-scan distance pulls the template mesh towards the noisy scan surface. Improving registration quality requires a clean separation of skin and non-skin regions on the scan mesh. Existing image-based (2D) or scan-based (3D) segmentation methods however perform poorly. Image-based segmentation outputs multi-view inconsistent masks, and they cannot account for scan inaccuracies or scan-image misalignment, while scan-based methods suffer from lower spatial resolution compared to images. In this work, we introduce a novel method that accurately separates skin from non-skin geometry on 3D human head scans. For this, our method extracts features from multi-view images using a frozen image foundation model and aggregates these features in 3D. These lifted 2D features are then fused with 3D geometric features extracted from the scan mesh, to then predict a segmentation mask directly on the scan mesh. We show that our segmentations improve the registration accuracy over pure 2D or 3D segmentation methods by 8.89% and 14.3%, respectively. Although trained only on synthetic data, our model generalizes well to real data.
Ego4o: Egocentric Human Motion Capture and Understanding from Multi-Modal Input
Apr 11, 2025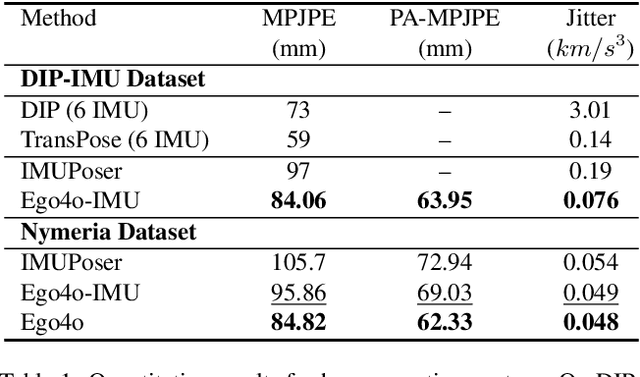
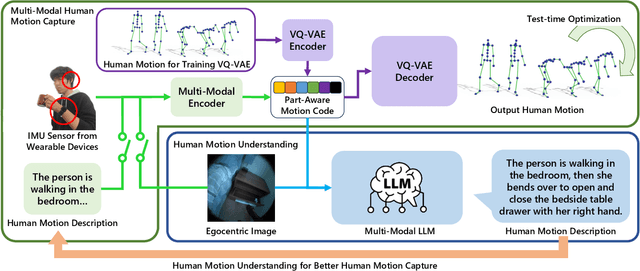

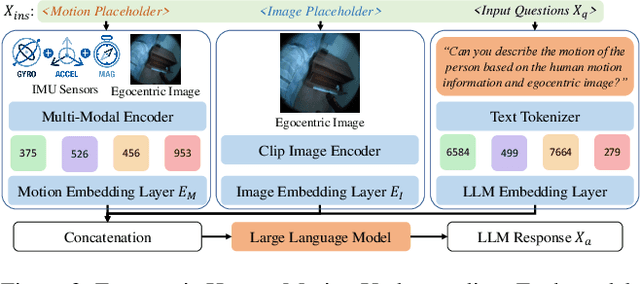
This work focuses on tracking and understanding human motion using consumer wearable devices, such as VR/AR headsets, smart glasses, cellphones, and smartwatches. These devices provide diverse, multi-modal sensor inputs, including egocentric images, and 1-3 sparse IMU sensors in varied combinations. Motion descriptions can also accompany these signals. The diverse input modalities and their intermittent availability pose challenges for consistent motion capture and understanding. In this work, we present Ego4o (o for omni), a new framework for simultaneous human motion capture and understanding from multi-modal egocentric inputs. This method maintains performance with partial inputs while achieving better results when multiple modalities are combined. First, the IMU sensor inputs, the optional egocentric image, and text description of human motion are encoded into the latent space of a motion VQ-VAE. Next, the latent vectors are sent to the VQ-VAE decoder and optimized to track human motion. When motion descriptions are unavailable, the latent vectors can be input into a multi-modal LLM to generate human motion descriptions, which can further enhance motion capture accuracy. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in predicting accurate human motion and high-quality motion descriptions.