 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage2Garment: Simulation-ready Garment Generation from a Single Image
Jan 15, 2026Estimating physically accurate, simulation-ready garments from a single image is challenging due to the absence of image-to-physics datasets and the ill-posed nature of this problem. Prior methods either require multi-view capture and expensive differentiable simulation or predict only garment geometry without the material properties required for realistic simulation. We propose a feed-forward framework that sidesteps these limitations by first fine-tuning a vision-language model to infer material composition and fabric attributes from real images, and then training a lightweight predictor that maps these attributes to the corresponding physical fabric parameters using a small dataset of material-physics measurements. Our approach introduces two new datasets (FTAG and T2P) and delivers simulation-ready garments from a single image without iterative optimization. Experiments show that our estimator achieves superior accuracy in material composition estimation and fabric attribute prediction, and by passing them through our physics parameter estimator, we further achieve higher-fidelity simulations compared to state-of-the-art image-to-garment methods.
GroomLight: Hybrid Inverse Rendering for Relightable Human Hair Appearance Modeling
Mar 13, 2025We present GroomLight, a novel method for relightable hair appearance modeling from multi-view images. Existing hair capture methods struggle to balance photorealistic rendering with relighting capabilities. Analytical material models, while physically grounded, often fail to fully capture appearance details. Conversely, neural rendering approaches excel at view synthesis but generalize poorly to novel lighting conditions. GroomLight addresses this challenge by combining the strengths of both paradigms. It employs an extended hair BSDF model to capture primary light transport and a light-aware residual model to reconstruct the remaining details. We further propose a hybrid inverse rendering pipeline to optimize both components, enabling high-fidelity relighting, view synthesis, and material editing. Extensive evaluations on real-world hair data demonstrate state-of-the-art performance of our method.
LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Sep 26, 2024
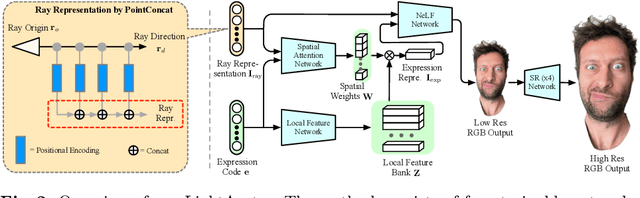


Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
Chat2Layout: Interactive 3D Furniture Layout with a Multimodal LLM
Jul 31, 2024Automatic furniture layout is long desired for convenient interior design. Leveraging the remarkable visual reasoning capabilities of multimodal large language models (MLLMs), recent methods address layout generation in a static manner, lacking the feedback-driven refinement essential for interactive user engagement. We introduce Chat2Layout, a novel interactive furniture layout generation system that extends the functionality of MLLMs into the realm of interactive layout design. To achieve this, we establish a unified vision-question paradigm for in-context learning, enabling seamless communication with MLLMs to steer their behavior without altering model weights. Within this framework, we present a novel training-free visual prompting mechanism. This involves a visual-text prompting technique that assist MLLMs in reasoning about plausible layout plans, followed by an Offline-to-Online search (O2O-Search) method, which automatically identifies the minimal set of informative references to provide exemplars for visual-text prompting. By employing an agent system with MLLMs as the core controller, we enable bidirectional interaction. The agent not only comprehends the 3D environment and user requirements through linguistic and visual perception but also plans tasks and reasons about actions to generate and arrange furniture within the virtual space. Furthermore, the agent iteratively updates based on visual feedback from execution results. Experimental results demonstrate that our approach facilitates language-interactive generation and arrangement for diverse and complex 3D furniture.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024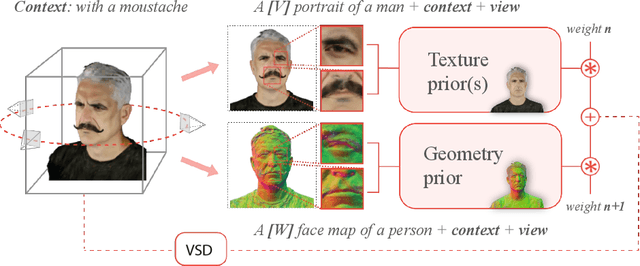



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
MVDD: Multi-View Depth Diffusion Models
Dec 19, 2023Denoising diffusion models have demonstrated outstanding results in 2D image generation, yet it remains a challenge to replicate its success in 3D shape generation. In this paper, we propose leveraging multi-view depth, which represents complex 3D shapes in a 2D data format that is easy to denoise. We pair this representation with a diffusion model, MVDD, that is capable of generating high-quality dense point clouds with 20K+ points with fine-grained details. To enforce 3D consistency in multi-view depth, we introduce an epipolar line segment attention that conditions the denoising step for a view on its neighboring views. Additionally, a depth fusion module is incorporated into diffusion steps to further ensure the alignment of depth maps. When augmented with surface reconstruction, MVDD can also produce high-quality 3D meshes. Furthermore, MVDD stands out in other tasks such as depth completion, and can serve as a 3D prior, significantly boosting many downstream tasks, such as GAN inversion. State-of-the-art results from extensive experiments demonstrate MVDD's excellent ability in 3D shape generation, depth completion, and its potential as a 3D prior for downstream tasks.
Mesh-Guided Neural Implicit Field Editing
Dec 04, 2023



Neural implicit fields have emerged as a powerful 3D representation for reconstructing and rendering photo-realistic views, yet they possess limited editability. Conversely, explicit 3D representations, such as polygonal meshes, offer ease of editing but may not be as suitable for rendering high-quality novel views. To harness the strengths of both representations, we propose a new approach that employs a mesh as a guiding mechanism in editing the neural radiance field. We first introduce a differentiable method using marching tetrahedra for polygonal mesh extraction from the neural implicit field and then design a differentiable color extractor to assign colors obtained from the volume renderings to this extracted mesh. This differentiable colored mesh allows gradient back-propagation from the explicit mesh to the implicit fields, empowering users to easily manipulate the geometry and color of neural implicit fields. To enhance user control from coarse-grained to fine-grained levels, we introduce an octree-based structure into its optimization. This structure prioritizes the edited regions and the surface part, making our method achieve fine-grained edits to the neural implicit field and accommodate various user modifications, including object additions, component removals, specific area deformations, and adjustments to local and global colors. Through extensive experiments involving diverse scenes and editing operations, we have demonstrated the capabilities and effectiveness of our method. Our project page is: \url{https://cassiepython.github.io/MNeuEdit/}
Efficient 3D Articulated Human Generation with Layered Surface Volumes
Jul 11, 2023Access to high-quality and diverse 3D articulated digital human assets is crucial in various applications, ranging from virtual reality to social platforms. Generative approaches, such as 3D generative adversarial networks (GANs), are rapidly replacing laborious manual content creation tools. However, existing 3D GAN frameworks typically rely on scene representations that leverage either template meshes, which are fast but offer limited quality, or volumes, which offer high capacity but are slow to render, thereby limiting the 3D fidelity in GAN settings. In this work, we introduce layered surface volumes (LSVs) as a new 3D object representation for articulated digital humans. LSVs represent a human body using multiple textured mesh layers around a conventional template. These layers are rendered using alpha compositing with fast differentiable rasterization, and they can be interpreted as a volumetric representation that allocates its capacity to a manifold of finite thickness around the template. Unlike conventional single-layer templates that struggle with representing fine off-surface details like hair or accessories, our surface volumes naturally capture such details. LSVs can be articulated, and they exhibit exceptional efficiency in GAN settings, where a 2D generator learns to synthesize the RGBA textures for the individual layers. Trained on unstructured, single-view 2D image datasets, our LSV-GAN generates high-quality and view-consistent 3D articulated digital humans without the need for view-inconsistent 2D upsampling networks.
AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control
Mar 30, 2023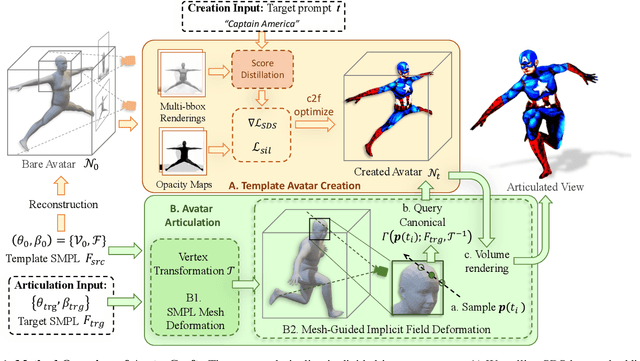
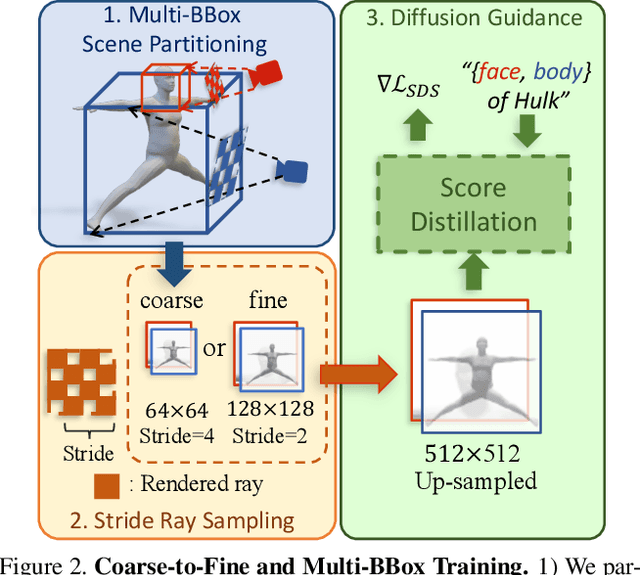
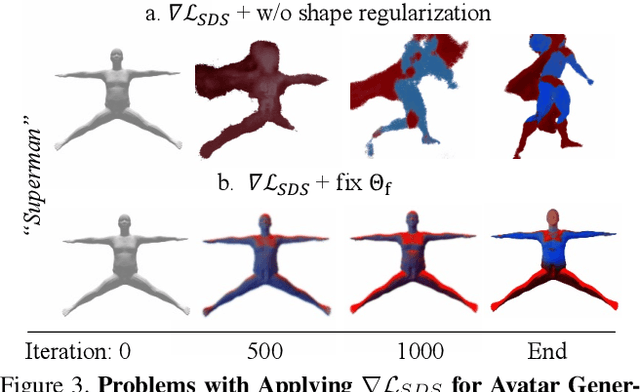
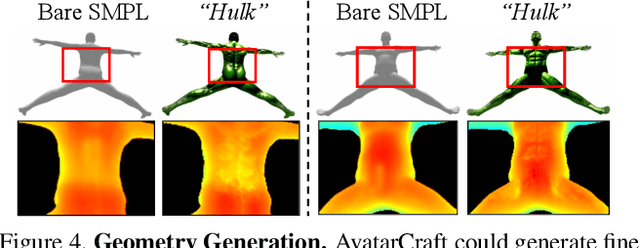
Neural implicit fields are powerful for representing 3D scenes and generating high-quality novel views, but it remains challenging to use such implicit representations for creating a 3D human avatar with a specific identity and artistic style that can be easily animated. Our proposed method, AvatarCraft, addresses this challenge by using diffusion models to guide the learning of geometry and texture for a neural avatar based on a single text prompt. We carefully design the optimization framework of neural implicit fields, including a coarse-to-fine multi-bounding box training strategy, shape regularization, and diffusion-based constraints, to produce high-quality geometry and texture. Additionally, we make the human avatar animatable by deforming the neural implicit field with an explicit warping field that maps the target human mesh to a template human mesh, both represented using parametric human models. This simplifies animation and reshaping of the generated avatar by controlling pose and shape parameters. Extensive experiments on various text descriptions show that AvatarCraft is effective and robust in creating human avatars and rendering novel views, poses, and shapes. Our project page is: \url{https://avatar-craft.github.io/}.
Invertible Neural Skinning
Feb 18, 2023



Building animatable and editable models of clothed humans from raw 3D scans and poses is a challenging problem. Existing reposing methods suffer from the limited expressiveness of Linear Blend Skinning (LBS), require costly mesh extraction to generate each new pose, and typically do not preserve surface correspondences across different poses. In this work, we introduce Invertible Neural Skinning (INS) to address these shortcomings. To maintain correspondences, we propose a Pose-conditioned Invertible Network (PIN) architecture, which extends the LBS process by learning additional pose-varying deformations. Next, we combine PIN with a differentiable LBS module to build an expressive and end-to-end Invertible Neural Skinning (INS) pipeline. We demonstrate the strong performance of our method by outperforming the state-of-the-art reposing techniques on clothed humans and preserving surface correspondences, while being an order of magnitude faster. We also perform an ablation study, which shows the usefulness of our pose-conditioning formulation, and our qualitative results display that INS can rectify artefacts introduced by LBS well. See our webpage for more details: https://yashkant.github.io/invertible-neural-skinning/