 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinematic Compositing Using Character-Environment-Harmonized Video Generation Models
Jun 17, 2026Cinematic compositing aims to integrate green-screen characters into novel environments while maintaining physical and photometric realism. Previous methods often fail to capture the complex bidirectional interactions between characters and their surroundings, which we characterize as Character-to-Environment (C2E) physical interaction and Environment-to-Character (E2C) lighting harmonization. To address this, we propose an end-to-end video diffusion framework that jointly models C2E and E2C interactions, specifically handling the challenges of interactive props. Our approach introduces a tri-mask-guided architecture with RGB-D joint denoising to ensure physically consistent interactions among the character, props, and environment. We further develop an efficient prior-driven data curation pipeline to construct high-quality relighting pairs without expensive rendering. Finally, a reference-conditioned mechanism enables controllable environment synthesis and precise prop replacement. Extensive experiments demonstrate that our framework significantly outperforms existing methods in cinematic-quality dynamic video compositing.
VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
Jun 01, 2026The recent "Reasoning with Video" paradigm utilizes Video Generation Models (VGMs) to generate temporally coherent visual trajectories to complete reasoning tasks. Although state-of-the-art VGMs excel at visual quality, they often struggle to understand and follow task-specific rules, leading to logical failures across diverse reasoning scenarios. Existing efforts try to utilize Vision-Language Models (VLMs) as problem pre-solvers to produce or refine textual guidance for the VGM. However, textual descriptions fail to capture intricate spatiotemporal details, and VGMs often struggle to faithfully execute fine-grained or long-tail instructions even with a valid plan. While VLMs struggle as solvers, they possess strong perception capabilities to evaluate process-constraint satisfaction and final-goal achievement. Leveraging this strength, we introduce a paradigm shift that transitions the role of VLMs to "teachers". Specifically, a VLM teacher extracts task-specific rules to formulate differentiable rewards, guiding a VGM Reasoner via test-time online optimization of a lightweight LoRA module. This strategy enables adaptive test-time optimization and extends the reasoning capabilities beyond the VGM's intrinsic boundaries. Evaluations on symbolic (VBVR-Bench) and general-purpose (RULER-Bench) video reasoning benchmarks show that the proposed method yields a 16.7-point average performance gain, outperforming the VLM-as-Solver paradigm (+0.4 points) and Best-of-N scaling (+2.2 points) by a large margin at comparable test-time cost. These findings reveal that integrating VLMs as test-time teachers offers a promising paradigm for achieving generalizable video reasoning. Project Page: https://VLM-as-Teacher.github.io/
Ani3DHuman: Photorealistic 3D Human Animation with Self-guided Stochastic Sampling
Feb 22, 2026Current 3D human animation methods struggle to achieve photorealism: kinematics-based approaches lack non-rigid dynamics (e.g., clothing dynamics), while methods that leverage video diffusion priors can synthesize non-rigid motion but suffer from quality artifacts and identity loss. To overcome these limitations, we present Ani3DHuman, a framework that marries kinematics-based animation with video diffusion priors. We first introduce a layered motion representation that disentangles rigid motion from residual non-rigid motion. Rigid motion is generated by a kinematic method, which then produces a coarse rendering to guide the video diffusion model in generating video sequences that restore the residual non-rigid motion. However, this restoration task, based on diffusion sampling, is highly challenging, as the initial renderings are out-of-distribution, causing standard deterministic ODE samplers to fail. Therefore, we propose a novel self-guided stochastic sampling method, which effectively addresses the out-of-distribution problem by combining stochastic sampling (for photorealistic quality) with self-guidance (for identity fidelity). These restored videos provide high-quality supervision, enabling the optimization of the residual non-rigid motion field. Extensive experiments demonstrate that \MethodName can generate photorealistic 3D human animation, outperforming existing methods. Code is available in https://github.com/qiisun/ani3dhuman.
X2HDR: HDR Image Generation in a Perceptually Uniform Space
Feb 04, 2026High-dynamic-range (HDR) formats and displays are becoming increasingly prevalent, yet state-of-the-art image generators (e.g., Stable Diffusion and FLUX) typically remain limited to low-dynamic-range (LDR) output due to the lack of large-scale HDR training data. In this work, we show that existing pretrained diffusion models can be easily adapted to HDR generation without retraining from scratch. A key challenge is that HDR images are natively represented in linear RGB, whose intensity and color statistics differ substantially from those of sRGB-encoded LDR images. This gap, however, can be effectively bridged by converting HDR inputs into perceptually uniform encodings (e.g., using PU21 or PQ). Empirically, we find that LDR-pretrained variational autoencoders (VAEs) reconstruct PU21-encoded HDR inputs with fidelity comparable to LDR data, whereas linear RGB inputs cause severe degradations. Motivated by this finding, we describe an efficient adaptation strategy that freezes the VAE and finetunes only the denoiser via low-rank adaptation in a perceptually uniform space. This results in a unified computational method that supports both text-to-HDR synthesis and single-image RAW-to-HDR reconstruction. Experiments demonstrate that our perceptually encoded adaptation consistently improves perceptual fidelity, text-image alignment, and effective dynamic range, relative to previous techniques.
FaceRefiner: High-Fidelity Facial Texture Refinement with Differentiable Rendering-based Style Transfer
Jan 08, 2026Recent facial texture generation methods prefer to use deep networks to synthesize image content and then fill in the UV map, thus generating a compelling full texture from a single image. Nevertheless, the synthesized texture UV map usually comes from a space constructed by the training data or the 2D face generator, which limits the methods' generalization ability for in-the-wild input images. Consequently, their facial details, structures and identity may not be consistent with the input. In this paper, we address this issue by proposing a style transfer-based facial texture refinement method named FaceRefiner. FaceRefiner treats the 3D sampled texture as style and the output of a texture generation method as content. The photo-realistic style is then expected to be transferred from the style image to the content image. Different from current style transfer methods that only transfer high and middle level information to the result, our style transfer method integrates differentiable rendering to also transfer low level (or pixel level) information in the visible face regions. The main benefit of such multi-level information transfer is that, the details, structures and semantics in the input can thus be well preserved. The extensive experiments on Multi-PIE, CelebA and FFHQ datasets demonstrate that our refinement method can improve the texture quality and the face identity preserving ability, compared with state-of-the-arts.
Animus3D: Text-driven 3D Animation via Motion Score Distillation
Dec 14, 2025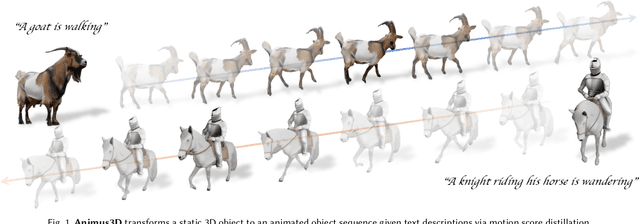
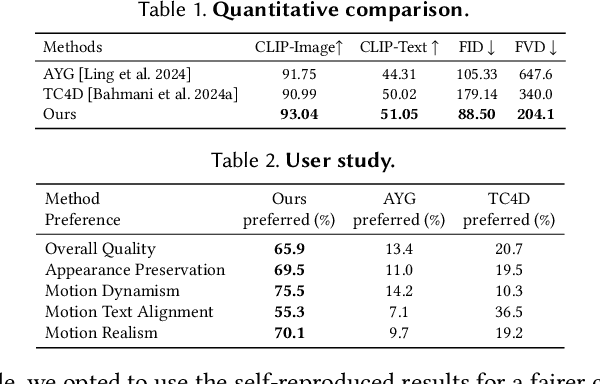
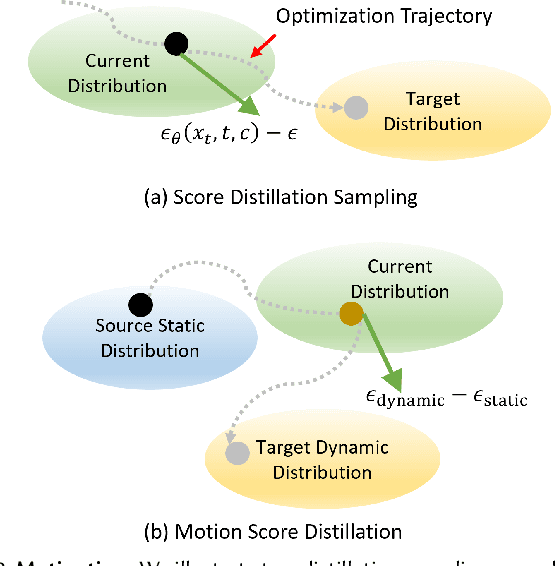
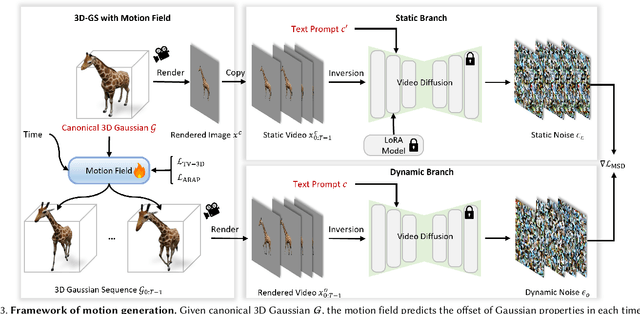
We present Animus3D, a text-driven 3D animation framework that generates motion field given a static 3D asset and text prompt. Previous methods mostly leverage the vanilla Score Distillation Sampling (SDS) objective to distill motion from pretrained text-to-video diffusion, leading to animations with minimal movement or noticeable jitter. To address this, our approach introduces a novel SDS alternative, Motion Score Distillation (MSD). Specifically, we introduce a LoRA-enhanced video diffusion model that defines a static source distribution rather than pure noise as in SDS, while another inversion-based noise estimation technique ensures appearance preservation when guiding motion. To further improve motion fidelity, we incorporate explicit temporal and spatial regularization terms that mitigate geometric distortions across time and space. Additionally, we propose a motion refinement module to upscale the temporal resolution and enhance fine-grained details, overcoming the fixed-resolution constraints of the underlying video model. Extensive experiments demonstrate that Animus3D successfully animates static 3D assets from diverse text prompts, generating significantly more substantial and detailed motion than state-of-the-art baselines while maintaining high visual integrity. Code will be released at https://qiisun.github.io/animus3d_page.
DuetSVG: Unified Multimodal SVG Generation with Internal Visual Guidance
Dec 11, 2025Recent vision-language model (VLM)-based approaches have achieved impressive results on SVG generation. However, because they generate only text and lack visual signals during decoding, they often struggle with complex semantics and fail to produce visually appealing or geometrically coherent SVGs. We introduce DuetSVG, a unified multimodal model that jointly generates image tokens and corresponding SVG tokens in an end-to-end manner. DuetSVG is trained on both image and SVG datasets. At inference, we apply a novel test-time scaling strategy that leverages the model's native visual predictions as guidance to improve SVG decoding quality. Extensive experiments show that our method outperforms existing methods, producing visually faithful, semantically aligned, and syntactically clean SVGs across a wide range of applications.
LayerPeeler: Autoregressive Peeling for Layer-wise Image Vectorization
May 29, 2025Image vectorization is a powerful technique that converts raster images into vector graphics, enabling enhanced flexibility and interactivity. However, popular image vectorization tools struggle with occluded regions, producing incomplete or fragmented shapes that hinder editability. While recent advancements have explored rule-based and data-driven layer-wise image vectorization, these methods face limitations in vectorization quality and flexibility. In this paper, we introduce LayerPeeler, a novel layer-wise image vectorization approach that addresses these challenges through a progressive simplification paradigm. The key to LayerPeeler's success lies in its autoregressive peeling strategy: by identifying and removing the topmost non-occluded layers while recovering underlying content, we generate vector graphics with complete paths and coherent layer structures. Our method leverages vision-language models to construct a layer graph that captures occlusion relationships among elements, enabling precise detection and description for non-occluded layers. These descriptive captions are used as editing instructions for a finetuned image diffusion model to remove the identified layers. To ensure accurate removal, we employ localized attention control that precisely guides the model to target regions while faithfully preserving the surrounding content. To support this, we contribute a large-scale dataset specifically designed for layer peeling tasks. Extensive quantitative and qualitative experiments demonstrate that LayerPeeler significantly outperforms existing techniques, producing vectorization results with superior path semantics, geometric regularity, and visual fidelity.
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
May 27, 2025Recent advances in CoT reasoning and RL post-training have been reported to enhance video reasoning capabilities of MLLMs. This progress naturally raises a question: can these models perform complex video reasoning in a manner comparable to human experts? However, existing video benchmarks primarily evaluate visual perception and grounding abilities, with questions that can be answered based on explicit prompts or isolated visual cues. Such benchmarks do not fully capture the intricacies of real-world reasoning, where humans must actively search for, integrate, and analyze multiple clues before reaching a conclusion. To address this issue, we present Video-Holmes, a benchmark inspired by the reasoning process of Sherlock Holmes, designed to evaluate the complex video reasoning capabilities of MLLMs. Video-Holmes consists of 1,837 questions derived from 270 manually annotated suspense short films, which spans seven carefully designed tasks. Each task is constructed by first identifying key events and causal relationships within films, and then designing questions that require models to actively locate and connect multiple relevant visual clues scattered across different video segments. Our comprehensive evaluation of state-of-the-art MLLMs reveals that, while these models generally excel at visual perception, they encounter substantial difficulties with integrating information and often miss critical clues. For example, the best-performing model, Gemini-2.5-Pro, achieves an accuracy of only 45%, with most models scoring below 40%. We aim that Video-Holmes can serve as a "Holmes-test" for multimodal reasoning, motivating models to reason more like humans and emphasizing the ongoing challenges in this field. The benchmark is released in https://github.com/TencentARC/Video-Holmes.
Style Customization of Text-to-Vector Generation with Image Diffusion Priors
May 15, 2025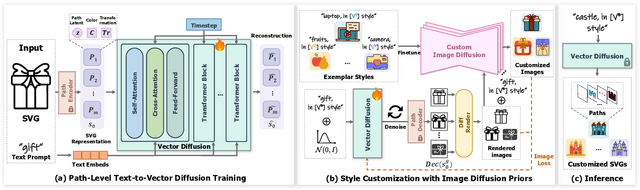

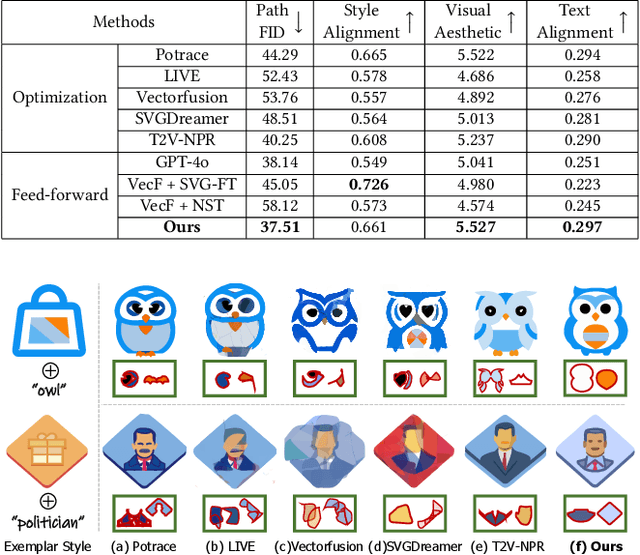
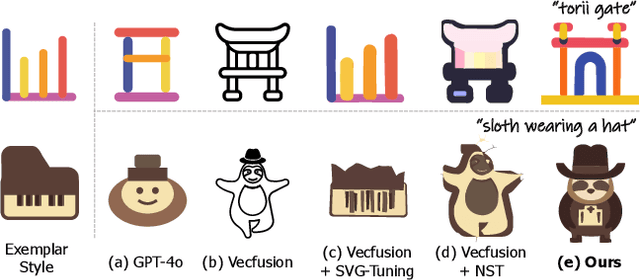
Scalable Vector Graphics (SVGs) are highly favored by designers due to their resolution independence and well-organized layer structure. Although existing text-to-vector (T2V) generation methods can create SVGs from text prompts, they often overlook an important need in practical applications: style customization, which is vital for producing a collection of vector graphics with consistent visual appearance and coherent aesthetics. Extending existing T2V methods for style customization poses certain challenges. Optimization-based T2V models can utilize the priors of text-to-image (T2I) models for customization, but struggle with maintaining structural regularity. On the other hand, feed-forward T2V models can ensure structural regularity, yet they encounter difficulties in disentangling content and style due to limited SVG training data. To address these challenges, we propose a novel two-stage style customization pipeline for SVG generation, making use of the advantages of both feed-forward T2V models and T2I image priors. In the first stage, we train a T2V diffusion model with a path-level representation to ensure the structural regularity of SVGs while preserving diverse expressive capabilities. In the second stage, we customize the T2V diffusion model to different styles by distilling customized T2I models. By integrating these techniques, our pipeline can generate high-quality and diverse SVGs in custom styles based on text prompts in an efficient feed-forward manner. The effectiveness of our method has been validated through extensive experiments. The project page is https://customsvg.github.io.