 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractor-free Generalizable 3D Gaussian Splatting
Nov 26, 2024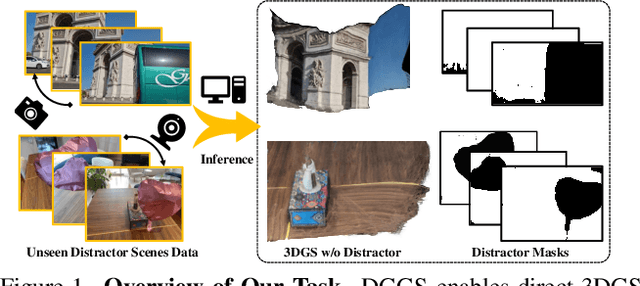
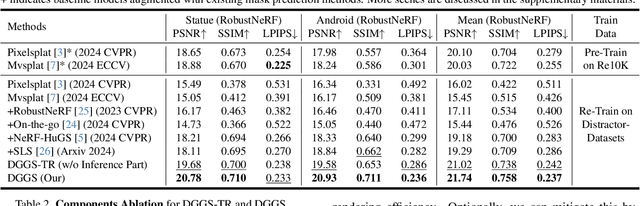
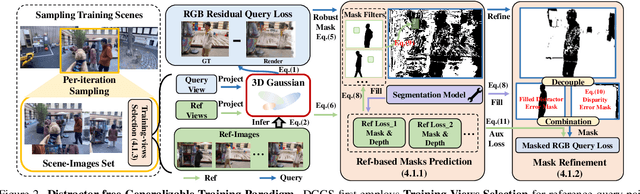
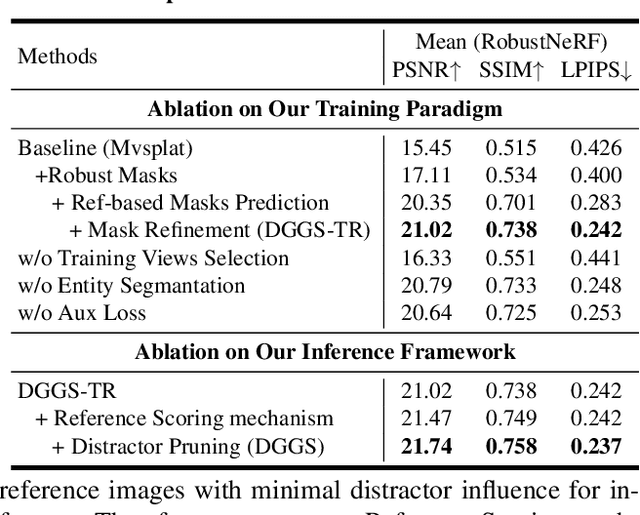
We present DGGS, a novel framework addressing the previously unexplored challenge of Distractor-free Generalizable 3D Gaussian Splatting (3DGS). It accomplishes two key objectives: fortifying generalizable 3DGS against distractor-laden data during both training and inference phases, while successfully extending cross-scene adaptation capabilities to conventional distractor-free approaches. To achieve these objectives, DGGS introduces a scene-agnostic reference-based mask prediction and refinement methodology during training phase, coupled with a training view selection strategy, effectively improving distractor prediction accuracy and training stability. Moreover, to address distractor-induced voids and artifacts during inference stage, we propose a two-stage inference framework for better reference selection based on the predicted distractor masks, complemented by a distractor pruning module to eliminate residual distractor effects. Extensive generalization experiments demonstrate DGGS's advantages under distractor-laden conditions. Additionally, experimental results show that our scene-agnostic mask inference achieves accuracy comparable to scene-specific trained methods. Homepage is \url{https://github.com/bbbbby-99/DGGS}.
3D Gaussian Splatting: Survey, Technologies, Challenges, and Opportunities
Jul 24, 2024



3D Gaussian Splatting (3DGS) has emerged as a prominent technique with the potential to become a mainstream method for 3D representations. It can effectively transform multi-view images into explicit 3D Gaussian representations through efficient training, and achieve real-time rendering of novel views. This survey aims to analyze existing 3DGS-related works from multiple intersecting perspectives, including related tasks, technologies, challenges, and opportunities. The primary objective is to provide newcomers with a rapid understanding of the field and to assist researchers in methodically organizing existing technologies and challenges. Specifically, we delve into the optimization, application, and extension of 3DGS, categorizing them based on their focuses or motivations. Additionally, we summarize and classify nine types of technical modules and corresponding improvements identified in existing works. Based on these analyses, we further examine the common challenges and technologies across various tasks, proposing potential research opportunities.
Zero-Shot Video Editing through Adaptive Sliding Score Distillation
Jun 07, 2024



The burgeoning field of text-based video generation (T2V) has reignited significant interest in the research of controllable video editing. Although pre-trained T2V-based editing models have achieved efficient editing capabilities, current works are still plagued by two major challenges. Firstly, the inherent limitations of T2V models lead to content inconsistencies and motion discontinuities between frames. Secondly, the notorious issue of over-editing significantly disrupts areas that are intended to remain unaltered. To address these challenges, our work aims to explore a robust video-based editing paradigm based on score distillation. Specifically, we propose an Adaptive Sliding Score Distillation strategy, which not only enhances the stability of T2V supervision but also incorporates both global and local video guidance to mitigate the impact of generation errors. Additionally, we modify the self-attention layers during the editing process to further preserve the key features of the original video. Extensive experiments demonstrate that these strategies enable us to effectively address the aforementioned challenges, achieving superior editing performance compared to existing state-of-the-art methods.
InsertNeRF: Instilling Generalizability into NeRF with HyperNet Modules
Aug 26, 2023



Generalizing Neural Radiance Fields (NeRF) to new scenes is a significant challenge that existing approaches struggle to address without extensive modifications to vanilla NeRF framework. We introduce InsertNeRF, a method for INStilling gEneRalizabiliTy into NeRF. By utilizing multiple plug-and-play HyperNet modules, InsertNeRF dynamically tailors NeRF's weights to specific reference scenes, transforming multi-scale sampling-aware features into scene-specific representations. This novel design allows for more accurate and efficient representations of complex appearances and geometries. Experiments show that this method not only achieves superior generalization performance but also provides a flexible pathway for integration with other NeRF-like systems, even in sparse input settings. Code will be available https://github.com/bbbbby-99/InsertNeRF.
Where and How: Mitigating Confusion in Neural Radiance Fields from Sparse Inputs
Aug 05, 2023Neural Radiance Fields from Sparse input} (NeRF-S) have shown great potential in synthesizing novel views with a limited number of observed viewpoints. However, due to the inherent limitations of sparse inputs and the gap between non-adjacent views, rendering results often suffer from over-fitting and foggy surfaces, a phenomenon we refer to as "CONFUSION" during volume rendering. In this paper, we analyze the root cause of this confusion and attribute it to two fundamental questions: "WHERE" and "HOW". To this end, we present a novel learning framework, WaH-NeRF, which effectively mitigates confusion by tackling the following challenges: (i)"WHERE" to Sample? in NeRF-S -- we introduce a Deformable Sampling strategy and a Weight-based Mutual Information Loss to address sample-position confusion arising from the limited number of viewpoints; and (ii) "HOW" to Predict? in NeRF-S -- we propose a Semi-Supervised NeRF learning Paradigm based on pose perturbation and a Pixel-Patch Correspondence Loss to alleviate prediction confusion caused by the disparity between training and testing viewpoints. By integrating our proposed modules and loss functions, WaH-NeRF outperforms previous methods under the NeRF-S setting. Code is available https://github.com/bbbbby-99/WaH-NeRF.
Few-shot Semantic Segmentation with Support-induced Graph Convolutional Network
Jan 09, 2023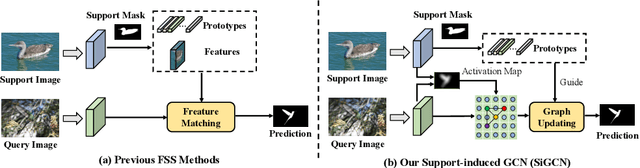
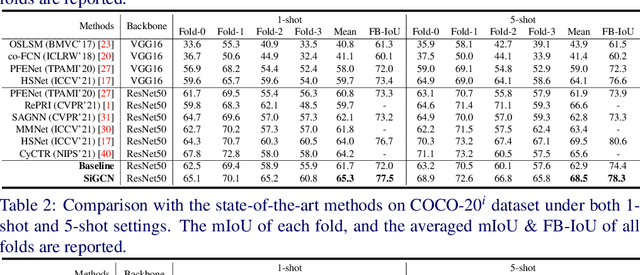
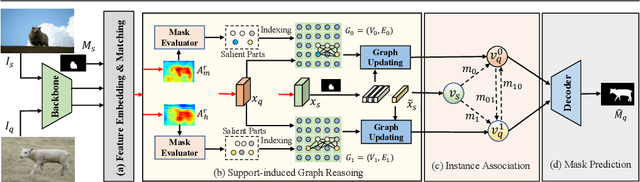
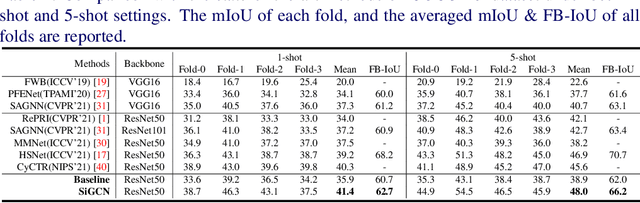
Few-shot semantic segmentation (FSS) aims to achieve novel objects segmentation with only a few annotated samples and has made great progress recently. Most of the existing FSS models focus on the feature matching between support and query to tackle FSS. However, the appearance variations between objects from the same category could be extremely large, leading to unreliable feature matching and query mask prediction. To this end, we propose a Support-induced Graph Convolutional Network (SiGCN) to explicitly excavate latent context structure in query images. Specifically, we propose a Support-induced Graph Reasoning (SiGR) module to capture salient query object parts at different semantic levels with a Support-induced GCN. Furthermore, an instance association (IA) module is designed to capture high-order instance context from both support and query instances. By integrating the proposed two modules, SiGCN can learn rich query context representation, and thus being more robust to appearance variations. Extensive experiments on PASCAL-5i and COCO-20i demonstrate that our SiGCN achieves state-of-the-art performance.
Dynamic Prototype Convolution Network for Few-Shot Semantic Segmentation
Apr 22, 2022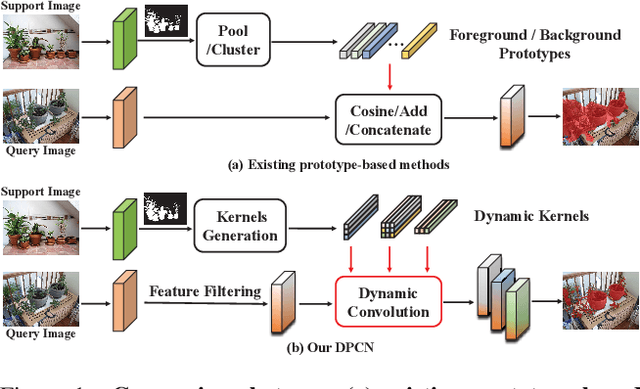
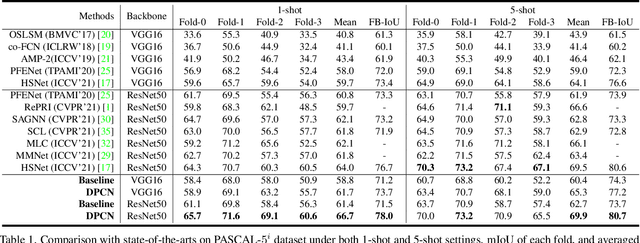
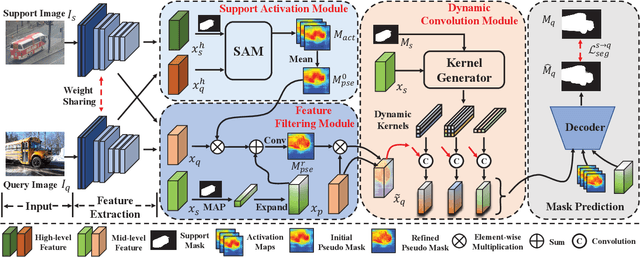
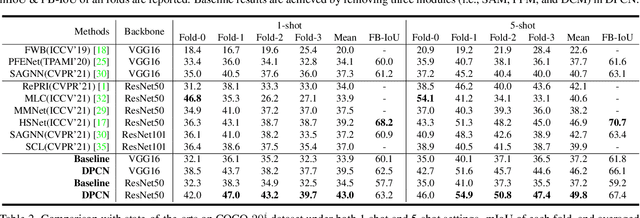
The key challenge for few-shot semantic segmentation (FSS) is how to tailor a desirable interaction among support and query features and/or their prototypes, under the episodic training scenario. Most existing FSS methods implement such support-query interactions by solely leveraging plain operations - e.g., cosine similarity and feature concatenation - for segmenting the query objects. However, these interaction approaches usually cannot well capture the intrinsic object details in the query images that are widely encountered in FSS, e.g., if the query object to be segmented has holes and slots, inaccurate segmentation almost always happens. To this end, we propose a dynamic prototype convolution network (DPCN) to fully capture the aforementioned intrinsic details for accurate FSS. Specifically, in DPCN, a dynamic convolution module (DCM) is firstly proposed to generate dynamic kernels from support foreground, then information interaction is achieved by convolution operations over query features using these kernels. Moreover, we equip DPCN with a support activation module (SAM) and a feature filtering module (FFM) to generate pseudo mask and filter out background information for the query images, respectively. SAM and FFM together can mine enriched context information from the query features. Our DPCN is also flexible and efficient under the k-shot FSS setting. Extensive experiments on PASCAL-5i and COCO-20i show that DPCN yields superior performances under both 1-shot and 5-shot settings.