 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep Policy Gradient in Charge: Sibling-Guided Credit Distillation for Long-Horizon Tool-Use Agents
Jun 10, 2026Long-horizon tool-use reinforcement learning can learn from outcome verification, but its trajectory-level advantage is broadcast across many reasoning, API, and answer tokens. Self-distillation promises a denser signal by reusing a policy's own rollouts or a privileged teacher. We show, however, that direct token-level self-distillation can silently destroy tool use: it rehearses teacher behavior without knowing which actions the verifier rewards, so useful skills and harmful shortcuts are amplified together. We introduce Sibling-Guided Credit Distillation (SGCD), which uses distillation for credit assignment rather than as a competing actor loss. Dynamic sampling produces mixed successful and failed sibling rollouts; an external LLM summarizes their contrast into a training-only stepwise credit reference; dense teacher/student divergence drives credit reassignment; and bounded detached credit weights reshape GRPO token advantages. The deployed student sees no external LLM, sibling evidence, or oracle. Across AppWorld and $τ^3$-airline, SGCD improves over matched GRPO comparators: AppWorld TGC $42.9 \to 45.6$ on test_normal and $24.7 \to 27.0$ on test_challenge, and $τ^3$-airline pass@1 $0.583 \to 0.602$.
DeltaEvolve: Accelerating Scientific Discovery through Momentum-Driven Evolution
Feb 02, 2026LLM-driven evolutionary systems have shown promise for automated science discovery, yet existing approaches such as AlphaEvolve rely on full-code histories that are context-inefficient and potentially provide weak evolutionary guidance. In this work, we first formalize the evolutionary agents as a general Expectation-Maximization framework, where the language model samples candidate programs (E-step) and the system updates the control context based on evaluation feedback (M-step). Under this view, constructing context via full-code snapshots constitutes a suboptimal M-step, as redundant implement details dilutes core algorithmic ideas, making it difficult to provide clear inspirations for evolution. To address this, we propose DeltaEvolve, a momentum-driven evolutionary framework that replaces full-code history with structured semantic delta capturing how and why modifications between successive nodes affect performance. As programs are often decomposable, semantic delta usually contains many effective components which are transferable and more informative to drive improvement. By organizing semantic delta through multi-level database and progressive disclosure mechanism, input tokens are further reduced. Empirical evaluations on tasks across diverse scientific domains show that our framework can discover better solution with less token consumption over full-code-based evolutionary agents.
ProCrop: Learning Aesthetic Image Cropping from Professional Compositions
May 28, 2025Image cropping is crucial for enhancing the visual appeal and narrative impact of photographs, yet existing rule-based and data-driven approaches often lack diversity or require annotated training data. We introduce ProCrop, a retrieval-based method that leverages professional photography to guide cropping decisions. By fusing features from professional photographs with those of the query image, ProCrop learns from professional compositions, significantly boosting performance. Additionally, we present a large-scale dataset of 242K weakly-annotated images, generated by out-painting professional images and iteratively refining diverse crop proposals. This composition-aware dataset generation offers diverse high-quality crop proposals guided by aesthetic principles and becomes the largest publicly available dataset for image cropping. Extensive experiments show that ProCrop significantly outperforms existing methods in both supervised and weakly-supervised settings. Notably, when trained on the new dataset, our ProCrop surpasses previous weakly-supervised methods and even matches fully supervised approaches. Both the code and dataset will be made publicly available to advance research in image aesthetics and composition analysis.
Robust Dataset Distillation by Matching Adversarial Trajectories
Mar 15, 2025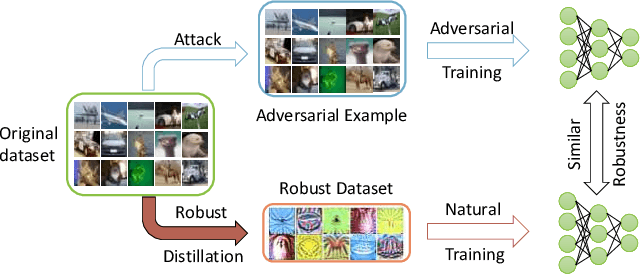
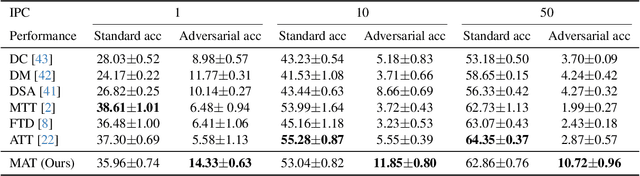
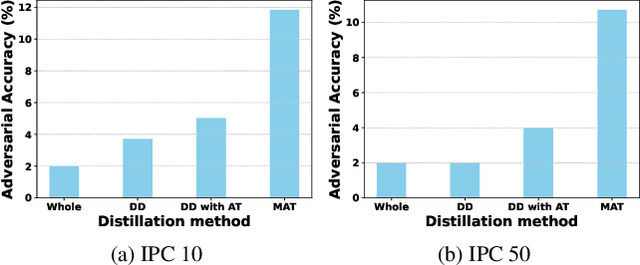
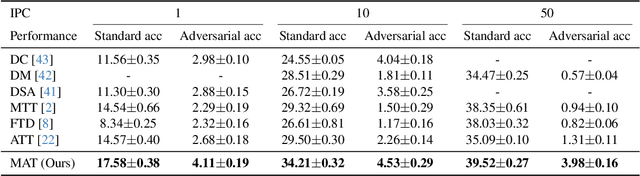
Dataset distillation synthesizes compact datasets that enable models to achieve performance comparable to training on the original large-scale datasets. However, existing distillation methods overlook the robustness of the model, resulting in models that are vulnerable to adversarial attacks when trained on distilled data. To address this limitation, we introduce the task of ``robust dataset distillation", a novel paradigm that embeds adversarial robustness into the synthetic datasets during the distillation process. We propose Matching Adversarial Trajectories (MAT), a method that integrates adversarial training into trajectory-based dataset distillation. MAT incorporates adversarial samples during trajectory generation to obtain robust training trajectories, which are then used to guide the distillation process. As experimentally demonstrated, even through natural training on our distilled dataset, models can achieve enhanced adversarial robustness while maintaining competitive accuracy compared to existing distillation methods. Our work highlights robust dataset distillation as a new and important research direction and provides a strong baseline for future research to bridge the gap between efficient training and adversarial robustness.
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs
Mar 10, 2025



Despite the success of distillation in large language models (LLMs), most prior work applies identical loss functions to both teacher- and student-generated data. These strategies overlook the synergy between loss formulations and data types, leading to a suboptimal performance boost in student models. To address this, we propose DistiLLM-2, a contrastive approach that simultaneously increases the likelihood of teacher responses and decreases that of student responses by harnessing this synergy. Our extensive experiments show that DistiLLM-2 not only builds high-performing student models across a wide range of tasks, including instruction-following and code generation, but also supports diverse applications, such as preference alignment and vision-language extensions. These findings highlight the potential of a contrastive approach to enhance the efficacy of LLM distillation by effectively aligning teacher and student models across varied data types.
Automatic Joint Structured Pruning and Quantization for Efficient Neural Network Training and Compression
Feb 23, 2025Structured pruning and quantization are fundamental techniques used to reduce the size of deep neural networks (DNNs) and typically are applied independently. Applying these techniques jointly via co-optimization has the potential to produce smaller, high-quality models. However, existing joint schemes are not widely used because of (1) engineering difficulties (complicated multi-stage processes), (2) black-box optimization (extensive hyperparameter tuning to control the overall compression), and (3) insufficient architecture generalization. To address these limitations, we present the framework GETA, which automatically and efficiently performs joint structured pruning and quantization-aware training on any DNNs. GETA introduces three key innovations: (i) a quantization-aware dependency graph (QADG) that constructs a pruning search space for generic quantization-aware DNN, (ii) a partially projected stochastic gradient method that guarantees layerwise bit constraints are satisfied, and (iii) a new joint learning strategy that incorporates interpretable relationships between pruning and quantization. We present numerical experiments on both convolutional neural networks and transformer architectures that show that our approach achieves competitive (often superior) performance compared to existing joint pruning and quantization methods.
StructSR: Refuse Spurious Details in Real-World Image Super-Resolution
Jan 16, 2025



Diffusion-based models have shown great promise in real-world image super-resolution (Real-ISR), but often generate content with structural errors and spurious texture details due to the empirical priors and illusions of these models. To address this issue, we introduce StructSR, a simple, effective, and plug-and-play method that enhances structural fidelity and suppresses spurious details for diffusion-based Real-ISR. StructSR operates without the need for additional fine-tuning, external model priors, or high-level semantic knowledge. At its core is the Structure-Aware Screening (SAS) mechanism, which identifies the image with the highest structural similarity to the low-resolution (LR) input in the early inference stage, allowing us to leverage it as a historical structure knowledge to suppress the generation of spurious details. By intervening in the diffusion inference process, StructSR seamlessly integrates with existing diffusion-based Real-ISR models. Our experimental results demonstrate that StructSR significantly improves the fidelity of structure and texture, improving the PSNR and SSIM metrics by an average of 5.27% and 9.36% on a synthetic dataset (DIV2K-Val) and 4.13% and 8.64% on two real-world datasets (RealSR and DRealSR) when integrated with four state-of-the-art diffusion-based Real-ISR methods.
Analyzing and Improving Model Collapse in Rectified Flow Models
Dec 11, 2024



Generative models aim to produce synthetic data indistinguishable from real distributions, but iterative training on self-generated data can lead to \emph{model collapse (MC)}, where performance degrades over time. In this work, we provide the first theoretical analysis of MC in Rectified Flow by framing it within the context of Denoising Autoencoders (DAEs). We show that when DAE models are trained on recursively generated synthetic data with small noise variance, they suffer from MC with progressive diminishing generation quality. To address this MC issue, we propose methods that strategically incorporate real data into the training process, even when direct noise-image pairs are unavailable. Our proposed techniques, including Reverse Collapse-Avoiding (RCA) Reflow and Online Collapse-Avoiding Reflow (OCAR), effectively prevent MC while maintaining the efficiency benefits of Rectified Flow. Extensive experiments on standard image datasets demonstrate that our methods not only mitigate MC but also improve sampling efficiency, leading to higher-quality image generation with fewer sampling steps.
OFER: Occluded Face Expression Reconstruction
Oct 29, 2024Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity, where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. Although this addresses the ambiguity problem, the challenge remains to pick the best matching shape to ensure consistency across diverse expressions. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on the predicted shape accuracy scores to select the best match. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, with added ability to generate multiple expressions for a given image.
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Aug 24, 2024



Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.