 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning on the Manifold: Unlocking Standard Diffusion Transformers with Representation Encoders
Feb 10, 2026Leveraging representation encoders for generative modeling offers a path for efficient, high-fidelity synthesis. However, standard diffusion transformers fail to converge on these representations directly. While recent work attributes this to a capacity bottleneck proposing computationally expensive width scaling of diffusion transformers we demonstrate that the failure is fundamentally geometric. We identify Geometric Interference as the root cause: standard Euclidean flow matching forces probability paths through the low-density interior of the hyperspherical feature space of representation encoders, rather than following the manifold surface. To resolve this, we propose Riemannian Flow Matching with Jacobi Regularization (RJF). By constraining the generative process to the manifold geodesics and correcting for curvature-induced error propagation, RJF enables standard Diffusion Transformer architectures to converge without width scaling. Our method RJF enables the standard DiT-B architecture (131M parameters) to converge effectively, achieving an FID of 3.37 where prior methods fail to converge. Code: https://github.com/amandpkr/RJF
Mitigating Long-Tail Bias via Prompt-Controlled Diffusion Augmentation
Feb 04, 2026Semantic segmentation of high-resolution remote-sensing imagery is critical for urban mapping and land-cover monitoring, yet training data typically exhibits severe long-tailed pixel imbalance. In the dataset LoveDA, this challenge is compounded by an explicit Urban/Rural split with distinct appearance and inconsistent class-frequency statistics across domains. We present a prompt-controlled diffusion augmentation framework that synthesizes paired label--image samples with explicit control of both domain and semantic composition. Stage~A uses a domain-aware, masked ratio-conditioned discrete diffusion model to generate layouts that satisfy user-specified class-ratio targets while respecting learned co-occurrence structure. Stage~B translates layouts into photorealistic, domain-consistent images using Stable Diffusion with ControlNet guidance. Mixing the resulting ratio and domain-controlled synthetic pairs with real data yields consistent improvements across multiple segmentation backbones, with gains concentrated on minority classes and improved Urban and Rural generalization, demonstrating controllable augmentation as a practical mechanism to mitigate long-tail bias in remote-sensing segmentation. Source codes, pretrained models, and synthetic datasets are available at \href{https://github.com/Buddhi19/SyntheticGen.git}{Github}
RemoteVAR: Autoregressive Visual Modeling for Remote Sensing Change Detection
Jan 17, 2026Remote sensing change detection aims to localize and characterize scene changes between two time points and is central to applications such as environmental monitoring and disaster assessment. Meanwhile, visual autoregressive models (VARs) have recently shown impressive image generation capability, but their adoption for pixel-level discriminative tasks remains limited due to weak controllability, suboptimal dense prediction performance and exposure bias. We introduce RemoteVAR, a new VAR-based change detection framework that addresses these limitations by conditioning autoregressive prediction on multi-resolution fused bi-temporal features via cross-attention, and by employing an autoregressive training strategy designed specifically for change map prediction. Extensive experiments on standard change detection benchmarks show that RemoteVAR delivers consistent and significant improvements over strong diffusion-based and transformer-based baselines, establishing a competitive autoregressive alternative for remote sensing change detection. Code will be available \href{https://github.com/yilmazkorkmaz1/RemoteVAR}{\underline{here}}.
Endless World: Real-Time 3D-Aware Long Video Generation
Dec 13, 2025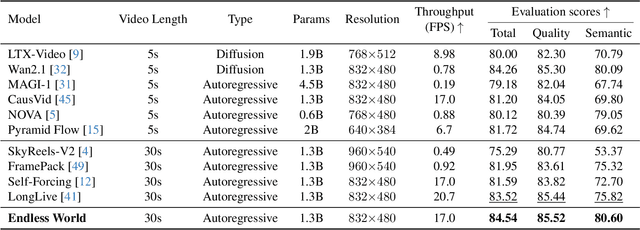
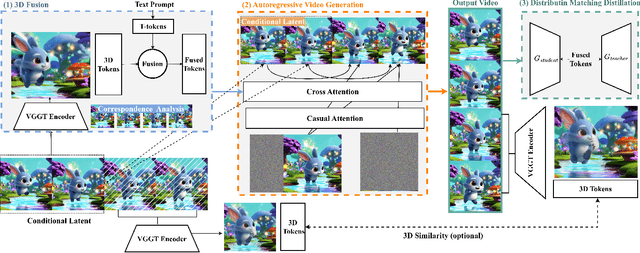
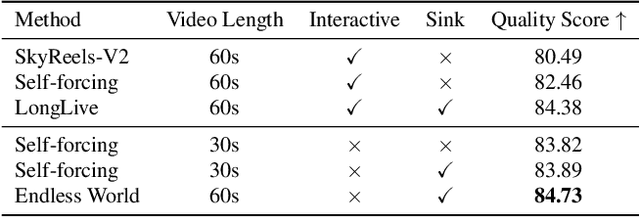

Producing long, coherent video sequences with stable 3D structure remains a major challenge, particularly in streaming scenarios. Motivated by this, we introduce Endless World, a real-time framework for infinite, 3D-consistent video generation.To support infinite video generation, we introduce a conditional autoregressive training strategy that aligns newly generated content with existing video frames. This design preserves long-range dependencies while remaining computationally efficient, enabling real-time inference on a single GPU without additional training overhead.Moreover, our Endless World integrates global 3D-aware attention to provide continuous geometric guidance across time. Our 3D injection mechanism enforces physical plausibility and geometric consistency throughout extended sequences, addressing key challenges in long-horizon and dynamic scene synthesis.Extensive experiments demonstrate that Endless World produces long, stable, and visually coherent videos, achieving competitive or superior performance to existing methods in both visual fidelity and spatial consistency. Our project has been available on https://bwgzk-keke.github.io/EndlessWorld/.
Referring Change Detection in Remote Sensing Imagery
Dec 12, 2025Change detection in remote sensing imagery is essential for applications such as urban planning, environmental monitoring, and disaster management. Traditional change detection methods typically identify all changes between two temporal images without distinguishing the types of transitions, which can lead to results that may not align with specific user needs. Although semantic change detection methods have attempted to address this by categorizing changes into predefined classes, these methods rely on rigid class definitions and fixed model architectures, making it difficult to mix datasets with different label sets or reuse models across tasks, as the output channels are tightly coupled with the number and type of semantic classes. To overcome these limitations, we introduce Referring Change Detection (RCD), which leverages natural language prompts to detect specific classes of changes in remote sensing images. By integrating language understanding with visual analysis, our approach allows users to specify the exact type of change they are interested in. However, training models for RCD is challenging due to the limited availability of annotated data and severe class imbalance in existing datasets. To address this, we propose a two-stage framework consisting of (I) \textbf{RCDNet}, a cross-modal fusion network designed for referring change detection, and (II) \textbf{RCDGen}, a diffusion-based synthetic data generation pipeline that produces realistic post-change images and change maps for a specified category using only pre-change image, without relying on semantic segmentation masks and thereby significantly lowering the barrier to scalable data creation. Experiments across multiple datasets show that our framework enables scalable and targeted change detection. Project website is here: https://yilmazkorkmaz1.github.io/RCD.
DiffRegCD: Integrated Registration and Change Detection with Diffusion Features
Nov 12, 2025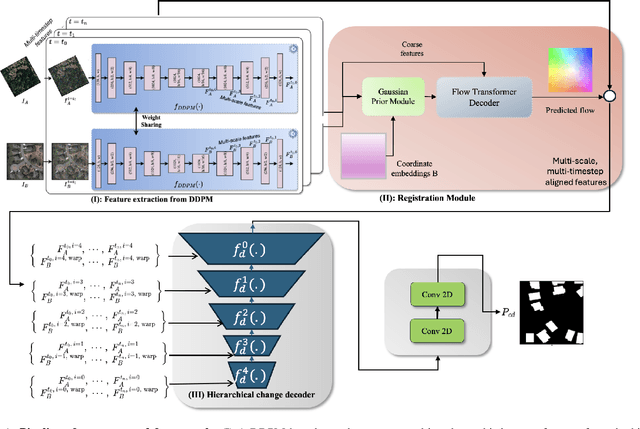

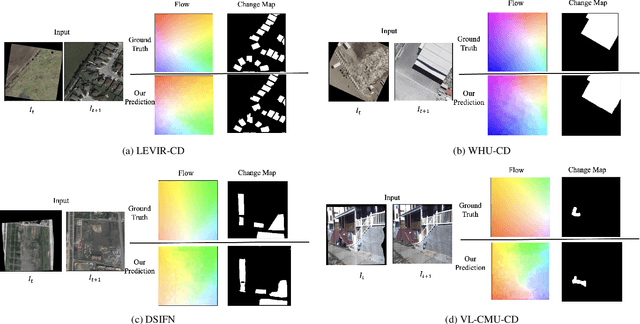

Change detection (CD) is fundamental to computer vision and remote sensing, supporting applications in environmental monitoring, disaster response, and urban development. Most CD models assume co-registered inputs, yet real-world imagery often exhibits parallax, viewpoint shifts, and long temporal gaps that cause severe misalignment. Traditional two stage methods that first register and then detect, as well as recent joint frameworks (e.g., BiFA, ChangeRD), still struggle under large displacements, relying on regression only flow, global homographies, or synthetic perturbations. We present DiffRegCD, an integrated framework that unifies dense registration and change detection in a single model. DiffRegCD reformulates correspondence estimation as a Gaussian smoothed classification task, achieving sub-pixel accuracy and stable training. It leverages frozen multi-scale features from a pretrained denoising diffusion model, ensuring robustness to illumination and viewpoint variation. Supervision is provided through controlled affine perturbations applied to standard CD datasets, yielding paired ground truth for both flow and change detection without pseudo labels. Extensive experiments on aerial (LEVIR-CD, DSIFN-CD, WHU-CD, SYSU-CD) and ground level (VL-CMU-CD) datasets show that DiffRegCD consistently surpasses recent baselines and remains reliable under wide temporal and geometric variation, establishing diffusion features and classification based correspondence as a strong foundation for unified change detection.
Morphing Through Time: Diffusion-Based Bridging of Temporal Gaps for Robust Alignment in Change Detection
Nov 11, 2025Remote sensing change detection is often challenged by spatial misalignment between bi-temporal images, especially when acquisitions are separated by long seasonal or multi-year gaps. While modern convolutional and transformer-based models perform well on aligned data, their reliance on precise co-registration limits their robustness in real-world conditions. Existing joint registration-detection frameworks typically require retraining and transfer poorly across domains. We introduce a modular pipeline that improves spatial and temporal robustness without altering existing change detection networks. The framework integrates diffusion-based semantic morphing, dense registration, and residual flow refinement. A diffusion module synthesizes intermediate morphing frames that bridge large appearance gaps, enabling RoMa to estimate stepwise correspondences between consecutive frames. The composed flow is then refined through a lightweight U-Net to produce a high-fidelity warp that co-registers the original image pair. Extensive experiments on LEVIR-CD, WHU-CD, and DSIFN-CD show consistent gains in both registration accuracy and downstream change detection across multiple backbones, demonstrating the generality and effectiveness of the proposed approach.
CGCE: Classifier-Guided Concept Erasure in Generative Models
Nov 08, 2025Recent advancements in large-scale generative models have enabled the creation of high-quality images and videos, but have also raised significant safety concerns regarding the generation of unsafe content. To mitigate this, concept erasure methods have been developed to remove undesirable concepts from pre-trained models. However, existing methods remain vulnerable to adversarial attacks that can regenerate the erased content. Moreover, achieving robust erasure often degrades the model's generative quality for safe, unrelated concepts, creating a difficult trade-off between safety and performance. To address this challenge, we introduce Classifier-Guided Concept Erasure (CGCE), an efficient plug-and-play framework that provides robust concept erasure for diverse generative models without altering their original weights. CGCE uses a lightweight classifier operating on text embeddings to first detect and then refine prompts containing undesired concepts. This approach is highly scalable, allowing for multi-concept erasure by aggregating guidance from several classifiers. By modifying only unsafe embeddings at inference time, our method prevents harmful content generation while preserving the model's original quality on benign prompts. Extensive experiments show that CGCE achieves state-of-the-art robustness against a wide range of red-teaming attacks. Our approach also maintains high generative utility, demonstrating a superior balance between safety and performance. We showcase the versatility of CGCE through its successful application to various modern T2I and T2V models, establishing it as a practical and effective solution for safe generative AI.
DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Oct 14, 2025Multimodal Large Language Models (MLLMs) in real-world applications require access to external knowledge sources and must remain responsive to the dynamic and ever-changing real-world information in order to address information-seeking and knowledge-intensive user queries. Existing approaches, such as retrieval augmented generation (RAG) methods, search agents, and search equipped MLLMs, often suffer from rigid pipelines, excessive search calls, and poorly constructed search queries, which result in inefficiencies and suboptimal outcomes. To address these limitations, we present DeepMMSearch-R1, the first multimodal LLM capable of performing on-demand, multi-turn web searches and dynamically crafting queries for both image and text search tools. Specifically, DeepMMSearch-R1 can initiate web searches based on relevant crops of the input image making the image search more effective, and can iteratively adapt text search queries based on retrieved information, thereby enabling self-reflection and self-correction. Our approach relies on a two-stage training pipeline: a cold start supervised finetuning phase followed by an online reinforcement learning optimization. For training, we introduce DeepMMSearchVQA, a novel multimodal VQA dataset created through an automated pipeline intermixed with real-world information from web search tools. This dataset contains diverse, multi-hop queries that integrate textual and visual information, teaching the model when to search, what to search for, which search tool to use and how to reason over the retrieved information. We conduct extensive experiments across a range of knowledge-intensive benchmarks to demonstrate the superiority of our approach. Finally, we analyze the results and provide insights that are valuable for advancing multimodal web-search.
FreeViS: Training-free Video Stylization with Inconsistent References
Oct 02, 2025Video stylization plays a key role in content creation, but it remains a challenging problem. Na\"ively applying image stylization frame-by-frame hurts temporal consistency and reduces style richness. Alternatively, training a dedicated video stylization model typically requires paired video data and is computationally expensive. In this paper, we propose FreeViS, a training-free video stylization framework that generates stylized videos with rich style details and strong temporal coherence. Our method integrates multiple stylized references to a pretrained image-to-video (I2V) model, effectively mitigating the propagation errors observed in prior works, without introducing flickers and stutters. In addition, it leverages high-frequency compensation to constrain the content layout and motion, together with flow-based motion cues to preserve style textures in low-saliency regions. Through extensive evaluations, FreeViS delivers higher stylization fidelity and superior temporal consistency, outperforming recent baselines and achieving strong human preference. Our training-free pipeline offers a practical and economic solution for high-quality, temporally coherent video stylization. The code and videos can be accessed via https://xujiacong.github.io/FreeViS/