 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Oct 14, 2025Multimodal Large Language Models (MLLMs) in real-world applications require access to external knowledge sources and must remain responsive to the dynamic and ever-changing real-world information in order to address information-seeking and knowledge-intensive user queries. Existing approaches, such as retrieval augmented generation (RAG) methods, search agents, and search equipped MLLMs, often suffer from rigid pipelines, excessive search calls, and poorly constructed search queries, which result in inefficiencies and suboptimal outcomes. To address these limitations, we present DeepMMSearch-R1, the first multimodal LLM capable of performing on-demand, multi-turn web searches and dynamically crafting queries for both image and text search tools. Specifically, DeepMMSearch-R1 can initiate web searches based on relevant crops of the input image making the image search more effective, and can iteratively adapt text search queries based on retrieved information, thereby enabling self-reflection and self-correction. Our approach relies on a two-stage training pipeline: a cold start supervised finetuning phase followed by an online reinforcement learning optimization. For training, we introduce DeepMMSearchVQA, a novel multimodal VQA dataset created through an automated pipeline intermixed with real-world information from web search tools. This dataset contains diverse, multi-hop queries that integrate textual and visual information, teaching the model when to search, what to search for, which search tool to use and how to reason over the retrieved information. We conduct extensive experiments across a range of knowledge-intensive benchmarks to demonstrate the superiority of our approach. Finally, we analyze the results and provide insights that are valuable for advancing multimodal web-search.
Training Free Stylized Abstraction
May 28, 2025Stylized abstraction synthesizes visually exaggerated yet semantically faithful representations of subjects, balancing recognizability with perceptual distortion. Unlike image-to-image translation, which prioritizes structural fidelity, stylized abstraction demands selective retention of identity cues while embracing stylistic divergence, especially challenging for out-of-distribution individuals. We propose a training-free framework that generates stylized abstractions from a single image using inference-time scaling in vision-language models (VLLMs) to extract identity-relevant features, and a novel cross-domain rectified flow inversion strategy that reconstructs structure based on style-dependent priors. Our method adapts structural restoration dynamically through style-aware temporal scheduling, enabling high-fidelity reconstructions that honor both subject and style. It supports multi-round abstraction-aware generation without fine-tuning. To evaluate this task, we introduce StyleBench, a GPT-based human-aligned metric suited for abstract styles where pixel-level similarity fails. Experiments across diverse abstraction (e.g., LEGO, knitted dolls, South Park) show strong generalization to unseen identities and styles in a fully open-source setup.
RestoreVAR: Visual Autoregressive Generation for All-in-One Image Restoration
May 23, 2025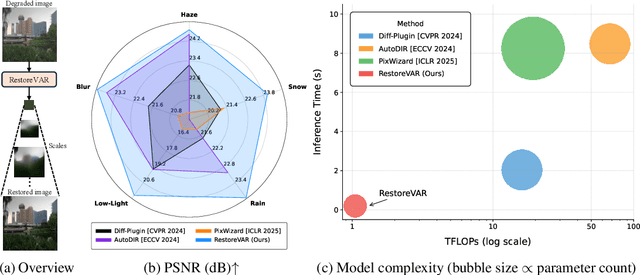
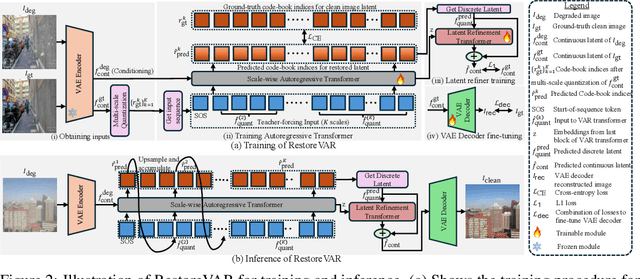
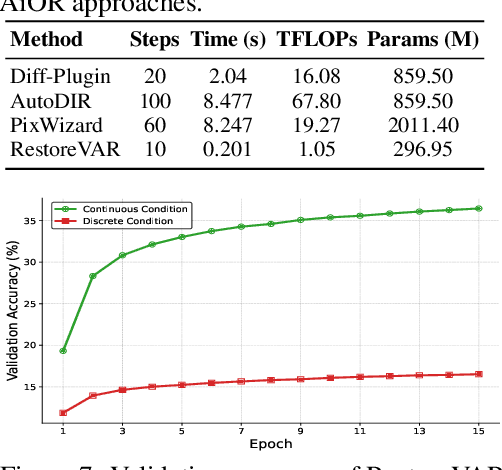
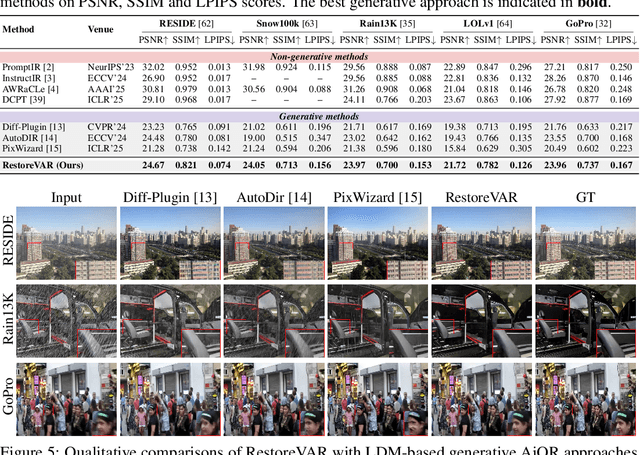
The use of latent diffusion models (LDMs) such as Stable Diffusion has significantly improved the perceptual quality of All-in-One image Restoration (AiOR) methods, while also enhancing their generalization capabilities. However, these LDM-based frameworks suffer from slow inference due to their iterative denoising process, rendering them impractical for time-sensitive applications. To address this, we propose RestoreVAR, a novel generative approach for AiOR that significantly outperforms LDM-based models in restoration performance while achieving over $\mathbf{10\times}$ faster inference. RestoreVAR leverages visual autoregressive modeling (VAR), a recently introduced approach which performs scale-space autoregression for image generation. VAR achieves comparable performance to that of state-of-the-art diffusion transformers with drastically reduced computational costs. To optimally exploit these advantages of VAR for AiOR, we propose architectural modifications and improvements, including intricately designed cross-attention mechanisms and a latent-space refinement module, tailored for the AiOR task. Extensive experiments show that RestoreVAR achieves state-of-the-art performance among generative AiOR methods, while also exhibiting strong generalization capabilities.
FaceXBench: Evaluating Multimodal LLMs on Face Understanding
Jan 17, 2025Multimodal Large Language Models (MLLMs) demonstrate impressive problem-solving abilities across a wide range of tasks and domains. However, their capacity for face understanding has not been systematically studied. To address this gap, we introduce FaceXBench, a comprehensive benchmark designed to evaluate MLLMs on complex face understanding tasks. FaceXBench includes 5,000 multimodal multiple-choice questions derived from 25 public datasets and a newly created dataset, FaceXAPI. These questions cover 14 tasks across 6 broad categories, assessing MLLMs' face understanding abilities in bias and fairness, face authentication, recognition, analysis, localization and tool retrieval. Using FaceXBench, we conduct an extensive evaluation of 26 open-source MLLMs alongside 2 proprietary models, revealing the unique challenges in complex face understanding tasks. We analyze the models across three evaluation settings: zero-shot, in-context task description, and chain-of-thought prompting. Our detailed analysis reveals that current MLLMs, including advanced models like GPT-4o, and GeminiPro 1.5, show significant room for improvement. We believe FaceXBench will be a crucial resource for developing MLLMs equipped to perform sophisticated face understanding. Code: https://github.com/Kartik-3004/facexbench
SegFace: Face Segmentation of Long-Tail Classes
Dec 11, 2024Face parsing refers to the semantic segmentation of human faces into key facial regions such as eyes, nose, hair, etc. It serves as a prerequisite for various advanced applications, including face editing, face swapping, and facial makeup, which often require segmentation masks for classes like eyeglasses, hats, earrings, and necklaces. These infrequently occurring classes are called long-tail classes, which are overshadowed by more frequently occurring classes known as head classes. Existing methods, primarily CNN-based, tend to be dominated by head classes during training, resulting in suboptimal representation for long-tail classes. Previous works have largely overlooked the problem of poor segmentation performance of long-tail classes. To address this issue, we propose SegFace, a simple and efficient approach that uses a lightweight transformer-based model which utilizes learnable class-specific tokens. The transformer decoder leverages class-specific tokens, allowing each token to focus on its corresponding class, thereby enabling independent modeling of each class. The proposed approach improves the performance of long-tail classes, thereby boosting overall performance. To the best of our knowledge, SegFace is the first work to employ transformer models for face parsing. Moreover, our approach can be adapted for low-compute edge devices, achieving 95.96 FPS. We conduct extensive experiments demonstrating that SegFace significantly outperforms previous state-of-the-art models, achieving a mean F1 score of 88.96 (+2.82) on the CelebAMask-HQ dataset and 93.03 (+0.65) on the LaPa dataset. Code: https://github.com/Kartik-3004/SegFace
PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition
Dec 10, 2024



Pre-training on large-scale datasets and utilizing margin-based loss functions have been highly successful in training models for high-resolution face recognition. However, these models struggle with low-resolution face datasets, in which the faces lack the facial attributes necessary for distinguishing different faces. Full fine-tuning on low-resolution datasets, a naive method for adapting the model, yields inferior performance due to catastrophic forgetting of pre-trained knowledge. Additionally the domain difference between high-resolution (HR) gallery images and low-resolution (LR) probe images in low resolution datasets leads to poor convergence for a single model to adapt to both gallery and probe after fine-tuning. To this end, we propose PETALface, a Parameter-Efficient Transfer Learning approach for low-resolution face recognition. Through PETALface, we attempt to solve both the aforementioned problems. (1) We solve catastrophic forgetting by leveraging the power of parameter efficient fine-tuning(PEFT). (2) We introduce two low-rank adaptation modules to the backbone, with weights adjusted based on the input image quality to account for the difference in quality for the gallery and probe images. To the best of our knowledge, PETALface is the first work leveraging the powers of PEFT for low resolution face recognition. Extensive experiments demonstrate that the proposed method outperforms full fine-tuning on low-resolution datasets while preserving performance on high-resolution and mixed-quality datasets, all while using only 0.48% of the parameters. Code: https://kartik-3004.github.io/PETALface/
Hyp-OC: Hyperbolic One Class Classification for Face Anti-Spoofing
Apr 22, 2024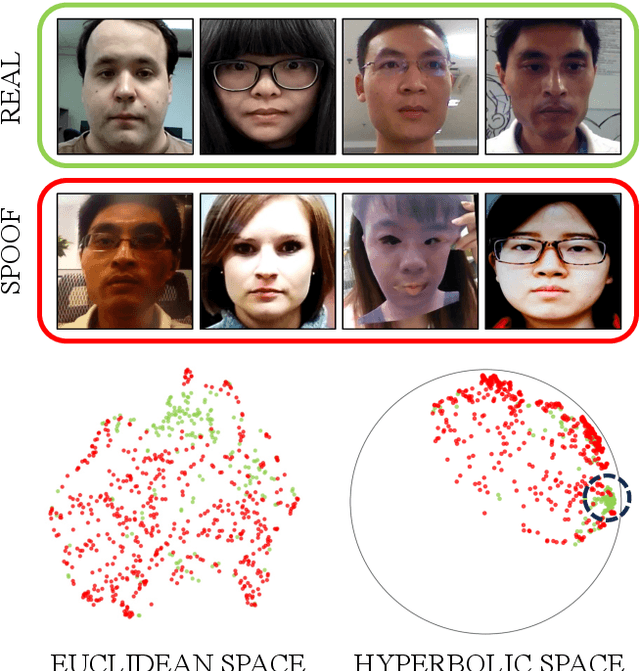
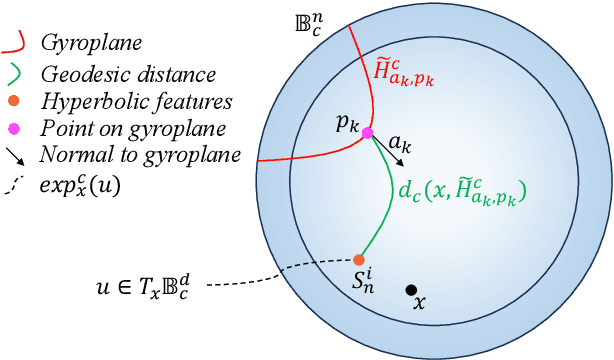
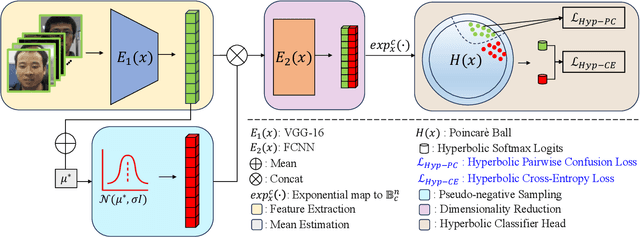

Face recognition technology has become an integral part of modern security systems and user authentication processes. However, these systems are vulnerable to spoofing attacks and can easily be circumvented. Most prior research in face anti-spoofing (FAS) approaches it as a two-class classification task where models are trained on real samples and known spoof attacks and tested for detection performance on unknown spoof attacks. However, in practice, FAS should be treated as a one-class classification task where, while training, one cannot assume any knowledge regarding the spoof samples a priori. In this paper, we reformulate the face anti-spoofing task from a one-class perspective and propose a novel hyperbolic one-class classification framework. To train our network, we use a pseudo-negative class sampled from the Gaussian distribution with a weighted running mean and propose two novel loss functions: (1) Hyp-PC: Hyperbolic Pairwise Confusion loss, and (2) Hyp-CE: Hyperbolic Cross Entropy loss, which operate in the hyperbolic space. Additionally, we employ Euclidean feature clipping and gradient clipping to stabilize the training in the hyperbolic space. To the best of our knowledge, this is the first work extending hyperbolic embeddings for face anti-spoofing in a one-class manner. With extensive experiments on five benchmark datasets: Rose-Youtu, MSU-MFSD, CASIA-MFSD, Idiap Replay-Attack, and OULU-NPU, we demonstrate that our method significantly outperforms the state-of-the-art, achieving better spoof detection performance.
FaceXFormer: A Unified Transformer for Facial Analysis
Mar 19, 2024In this work, we introduce FaceXformer, an end-to-end unified transformer model for a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility. Conventional methods in face analysis have often relied on task-specific designs and preprocessing techniques, which limit their approach to a unified architecture. Unlike these conventional methods, our FaceXformer leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework. Moreover, we propose a parameter-efficient decoder, FaceX, which jointly processes face and task tokens, thereby learning generalized and robust face representations across different tasks. To the best of our knowledge, this is the first work to propose a single model capable of handling all these facial analysis tasks using transformers. We conducted a comprehensive analysis of effective backbones for unified face task processing and evaluated different task queries and the synergy between them. We conduct experiments against state-of-the-art specialized models and previous multi-task models in both intra-dataset and cross-dataset evaluations across multiple benchmarks. Additionally, our model effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight different tasks, all while maintaining the real-time performance of 37 FPS.
DeePhy: On Deepfake Phylogeny
Sep 19, 2022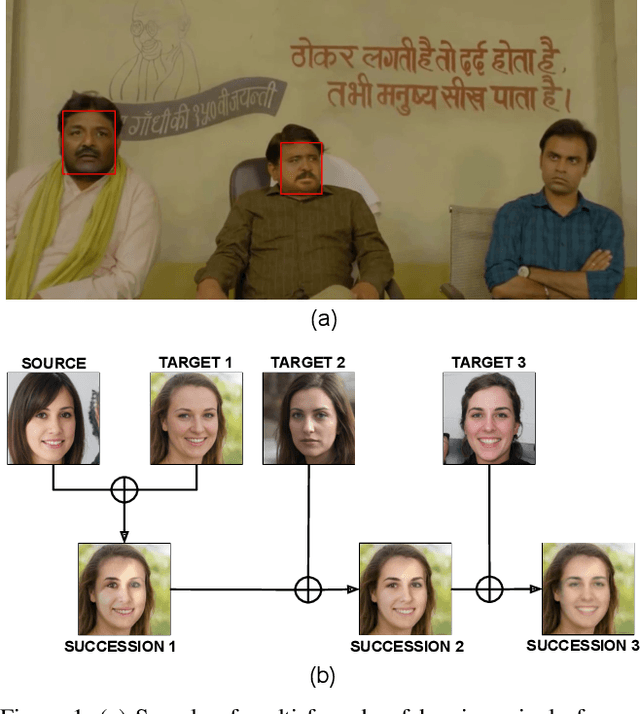
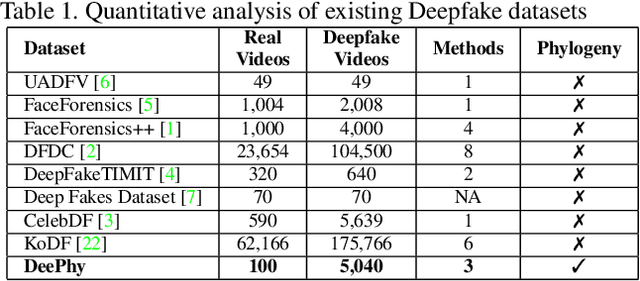

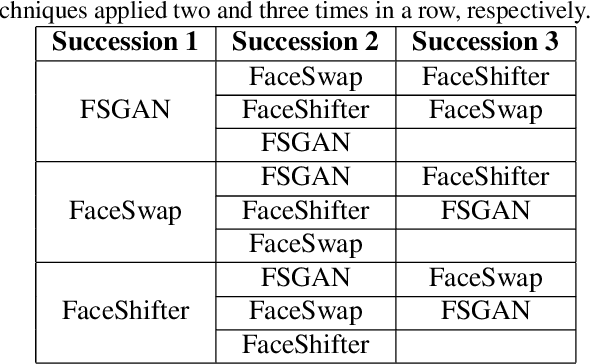
Deepfake refers to tailored and synthetically generated videos which are now prevalent and spreading on a large scale, threatening the trustworthiness of the information available online. While existing datasets contain different kinds of deepfakes which vary in their generation technique, they do not consider progression of deepfakes in a "phylogenetic" manner. It is possible that an existing deepfake face is swapped with another face. This process of face swapping can be performed multiple times and the resultant deepfake can be evolved to confuse the deepfake detection algorithms. Further, many databases do not provide the employed generative model as target labels. Model attribution helps in enhancing the explainability of the detection results by providing information on the generative model employed. In order to enable the research community to address these questions, this paper proposes DeePhy, a novel Deepfake Phylogeny dataset which consists of 5040 deepfake videos generated using three different generation techniques. There are 840 videos of one-time swapped deepfakes, 2520 videos of two-times swapped deepfakes and 1680 videos of three-times swapped deepfakes. With over 30 GBs in size, the database is prepared in over 1100 hours using 18 GPUs of 1,352 GB cumulative memory. We also present the benchmark on DeePhy dataset using six deepfake detection algorithms. The results highlight the need to evolve the research of model attribution of deepfakes and generalize the process over a variety of deepfake generation techniques. The database is available at: http://iab-rubric.org/deephy-database