 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonizing Geometry and Uncertainty: Diffusion with Hyperspheres
Jun 12, 2025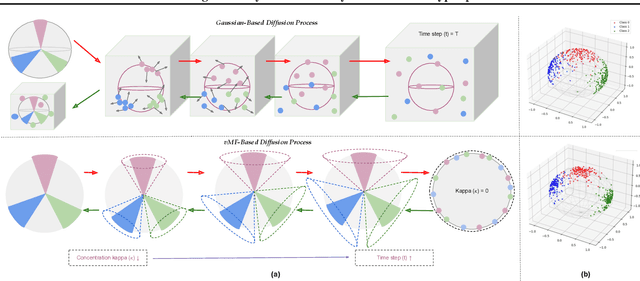
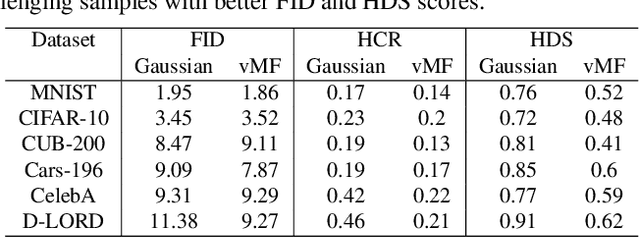


Do contemporary diffusion models preserve the class geometry of hyperspherical data? Standard diffusion models rely on isotropic Gaussian noise in the forward process, inherently favoring Euclidean spaces. However, many real-world problems involve non-Euclidean distributions, such as hyperspherical manifolds, where class-specific patterns are governed by angular geometry within hypercones. When modeled in Euclidean space, these angular subtleties are lost, leading to suboptimal generative performance. To address this limitation, we introduce HyperSphereDiff to align hyperspherical structures with directional noise, preserving class geometry and effectively capturing angular uncertainty. We demonstrate both theoretically and empirically that this approach aligns the generative process with the intrinsic geometry of hyperspherical data, resulting in more accurate and geometry-aware generative models. We evaluate our framework on four object datasets and two face datasets, showing that incorporating angular uncertainty better preserves the underlying hyperspherical manifold. Resources are available at: {https://github.com/IAB-IITJ/Harmonizing-Geometry-and-Uncertainty-Diffusion-with-Hyperspheres/}
LitMAS: A Lightweight and Generalized Multi-Modal Anti-Spoofing Framework for Biometric Security
Jun 07, 2025Biometric authentication systems are increasingly being deployed in critical applications, but they remain susceptible to spoofing. Since most of the research efforts focus on modality-specific anti-spoofing techniques, building a unified, resource-efficient solution across multiple biometric modalities remains a challenge. To address this, we propose LitMAS, a $\textbf{Li}$gh$\textbf{t}$ weight and generalizable $\textbf{M}$ulti-modal $\textbf{A}$nti-$\textbf{S}$poofing framework designed to detect spoofing attacks in speech, face, iris, and fingerprint-based biometric systems. At the core of LitMAS is a Modality-Aligned Concentration Loss, which enhances inter-class separability while preserving cross-modal consistency and enabling robust spoof detection across diverse biometric traits. With just 6M parameters, LitMAS surpasses state-of-the-art methods by $1.36\%$ in average EER across seven datasets, demonstrating high efficiency, strong generalizability, and suitability for edge deployment. Code and trained models are available at https://github.com/IAB-IITJ/LitMAS.
Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
Mar 25, 2025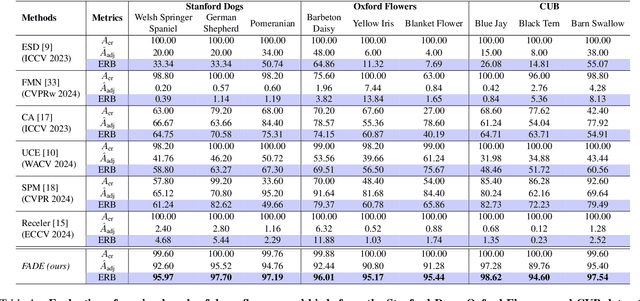
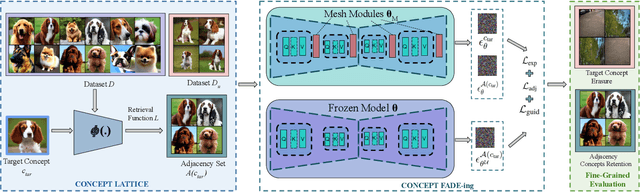
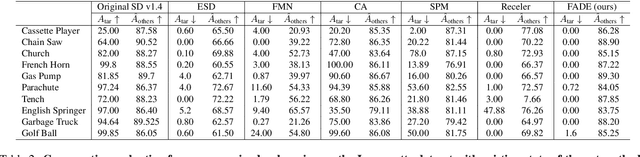
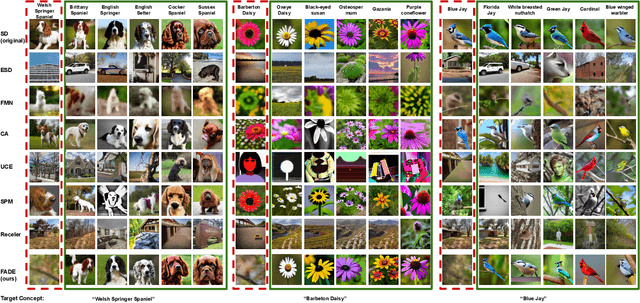
Existing unlearning algorithms in text-to-image generative models often fail to preserve the knowledge of semantically related concepts when removing specific target concepts: a challenge known as adjacency. To address this, we propose FADE (Fine grained Attenuation for Diffusion Erasure), introducing adjacency aware unlearning in diffusion models. FADE comprises two components: (1) the Concept Neighborhood, which identifies an adjacency set of related concepts, and (2) Mesh Modules, employing a structured combination of Expungement, Adjacency, and Guidance loss components. These enable precise erasure of target concepts while preserving fidelity across related and unrelated concepts. Evaluated on datasets like Stanford Dogs, Oxford Flowers, CUB, I2P, Imagenette, and ImageNet1k, FADE effectively removes target concepts with minimal impact on correlated concepts, achieving atleast a 12% improvement in retention performance over state-of-the-art methods.
Continual Unlearning for Foundational Text-to-Image Models without Generalization Erosion
Mar 17, 2025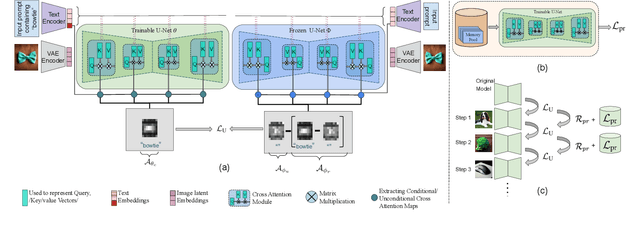

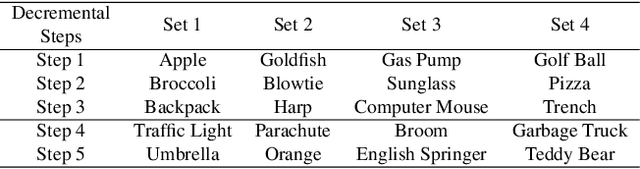

How can we effectively unlearn selected concepts from pre-trained generative foundation models without resorting to extensive retraining? This research introduces `continual unlearning', a novel paradigm that enables the targeted removal of multiple specific concepts from foundational generative models, incrementally. We propose Decremental Unlearning without Generalization Erosion (DUGE) algorithm which selectively unlearns the generation of undesired concepts while preserving the generation of related, non-targeted concepts and alleviating generalization erosion. For this, DUGE targets three losses: a cross-attention loss that steers the focus towards images devoid of the target concept; a prior-preservation loss that safeguards knowledge related to non-target concepts; and a regularization loss that prevents the model from suffering from generalization erosion. Experimental results demonstrate the ability of the proposed approach to exclude certain concepts without compromising the overall integrity and performance of the model. This offers a pragmatic solution for refining generative models, adeptly handling the intricacies of model training and concept management lowering the risks of copyright infringement, personal or licensed material misuse, and replication of distinctive artistic styles. Importantly, it maintains the non-targeted concepts, thereby safeguarding the model's core capabilities and effectiveness.
HyperSpaceX: Radial and Angular Exploration of HyperSpherical Dimensions
Aug 05, 2024Traditional deep learning models rely on methods such as softmax cross-entropy and ArcFace loss for tasks like classification and face recognition. These methods mainly explore angular features in a hyperspherical space, often resulting in entangled inter-class features due to dense angular data across many classes. In this paper, a new field of feature exploration is proposed known as HyperSpaceX which enhances class discrimination by exploring both angular and radial dimensions in multi-hyperspherical spaces, facilitated by a novel DistArc loss. The proposed DistArc loss encompasses three feature arrangement components: two angular and one radial, enforcing intra-class binding and inter-class separation in multi-radial arrangement, improving feature discriminability. Evaluation of HyperSpaceX framework for the novel representation utilizes a proposed predictive measure that accounts for both angular and radial elements, providing a more comprehensive assessment of model accuracy beyond standard metrics. Experiments across seven object classification and six face recognition datasets demonstrate state-of-the-art (SoTA) results obtained from HyperSpaceX, achieving up to a 20% performance improvement on large-scale object datasets in lower dimensions and up to 6% gain in higher dimensions.
On Responsible Machine Learning Datasets with Fairness, Privacy, and Regulatory Norms
Oct 31, 2023
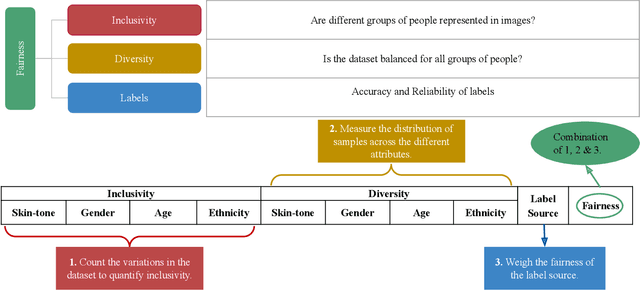


Artificial Intelligence (AI) has made its way into various scientific fields, providing astonishing improvements over existing algorithms for a wide variety of tasks. In recent years, there have been severe concerns over the trustworthiness of AI technologies. The scientific community has focused on the development of trustworthy AI algorithms. However, machine and deep learning algorithms, popular in the AI community today, depend heavily on the data used during their development. These learning algorithms identify patterns in the data, learning the behavioral objective. Any flaws in the data have the potential to translate directly into algorithms. In this study, we discuss the importance of Responsible Machine Learning Datasets and propose a framework to evaluate the datasets through a responsible rubric. While existing work focuses on the post-hoc evaluation of algorithms for their trustworthiness, we provide a framework that considers the data component separately to understand its role in the algorithm. We discuss responsible datasets through the lens of fairness, privacy, and regulatory compliance and provide recommendations for constructing future datasets. After surveying over 100 datasets, we use 60 datasets for analysis and demonstrate that none of these datasets is immune to issues of fairness, privacy preservation, and regulatory compliance. We provide modifications to the ``datasheets for datasets" with important additions for improved dataset documentation. With governments around the world regularizing data protection laws, the method for the creation of datasets in the scientific community requires revision. We believe this study is timely and relevant in today's era of AI.
Are Face Detection Models Biased?
Nov 07, 2022



The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. Research in bias focuses primarily on facial recognition and attribute prediction with scarce emphasis on face detection. Existing studies consider face detection as binary classification into 'face' and 'non-face' classes. In this work, we investigate possible bias in the domain of face detection through facial region localization which is currently unexplored. Since facial region localization is an essential task for all face recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Most existing face detection datasets lack suitable annotation for such analysis. Therefore, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. Utilizing the extensive annotations from F2LA, an experimental setup is designed to study the performance of four pre-trained face detectors. We observe (i) a high disparity in detection accuracies across gender and skin-tone, and (ii) interplay of confounding factors beyond demography. The F2LA data and associated annotations can be accessed at http://iab-rubric.org/index.php/F2LA.
DeePhy: On Deepfake Phylogeny
Sep 19, 2022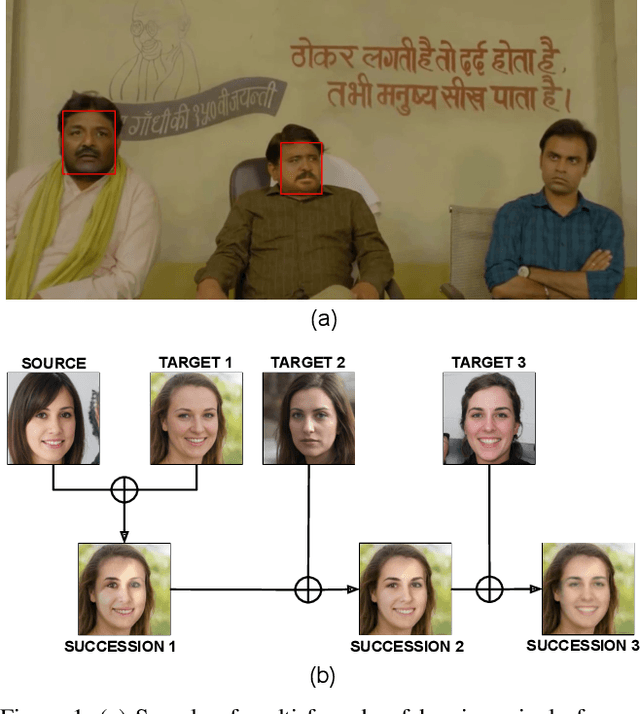
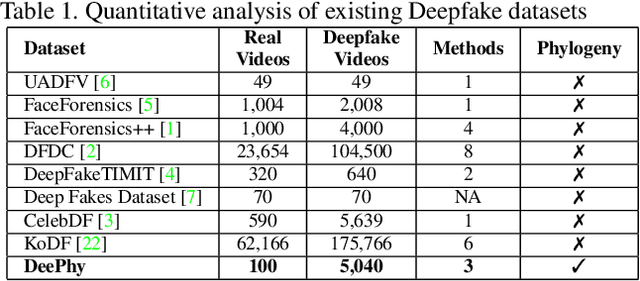

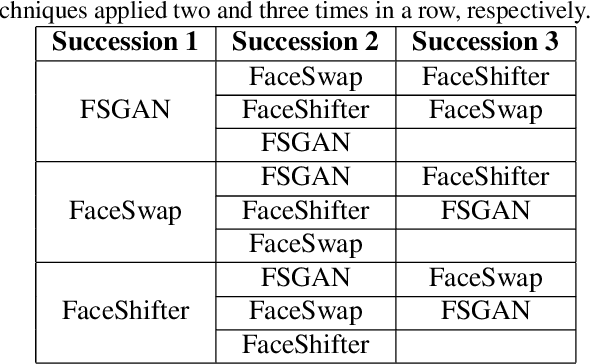
Deepfake refers to tailored and synthetically generated videos which are now prevalent and spreading on a large scale, threatening the trustworthiness of the information available online. While existing datasets contain different kinds of deepfakes which vary in their generation technique, they do not consider progression of deepfakes in a "phylogenetic" manner. It is possible that an existing deepfake face is swapped with another face. This process of face swapping can be performed multiple times and the resultant deepfake can be evolved to confuse the deepfake detection algorithms. Further, many databases do not provide the employed generative model as target labels. Model attribution helps in enhancing the explainability of the detection results by providing information on the generative model employed. In order to enable the research community to address these questions, this paper proposes DeePhy, a novel Deepfake Phylogeny dataset which consists of 5040 deepfake videos generated using three different generation techniques. There are 840 videos of one-time swapped deepfakes, 2520 videos of two-times swapped deepfakes and 1680 videos of three-times swapped deepfakes. With over 30 GBs in size, the database is prepared in over 1100 hours using 18 GPUs of 1,352 GB cumulative memory. We also present the benchmark on DeePhy dataset using six deepfake detection algorithms. The results highlight the need to evolve the research of model attribution of deepfakes and generalize the process over a variety of deepfake generation techniques. The database is available at: http://iab-rubric.org/deephy-database
Multi-Task Driven Explainable Diagnosis of COVID-19 using Chest X-ray Images
Aug 03, 2020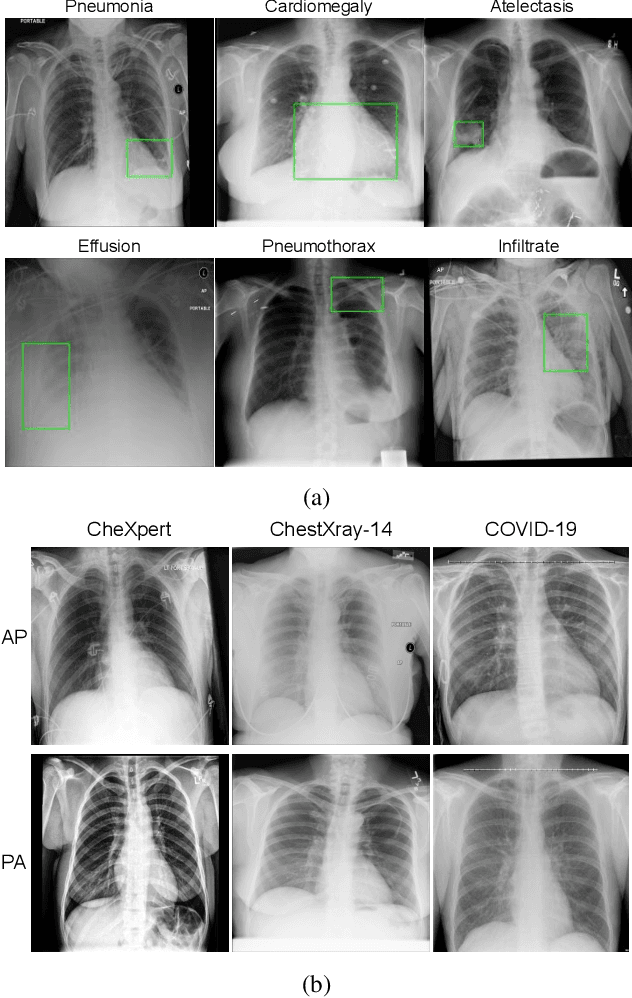
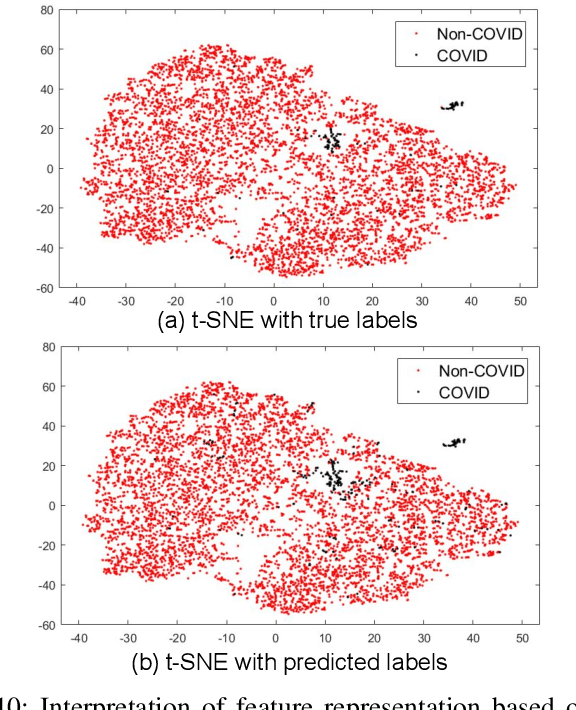
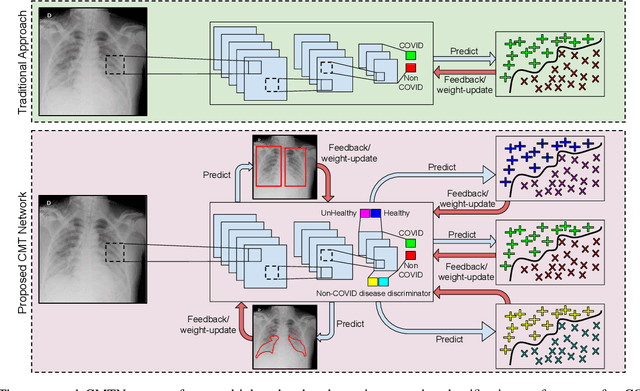
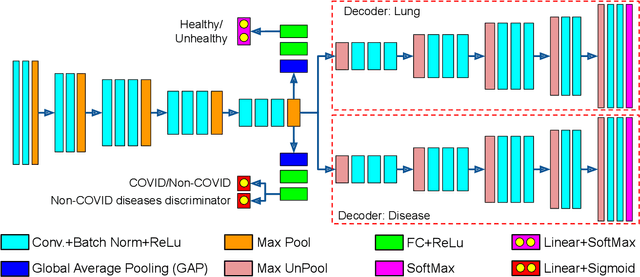
With increasing number of COVID-19 cases globally, all the countries are ramping up the testing numbers. While the RT-PCR kits are available in sufficient quantity in several countries, others are facing challenges with limited availability of testing kits and processing centers in remote areas. This has motivated researchers to find alternate methods of testing which are reliable, easily accessible and faster. Chest X-Ray is one of the modalities that is gaining acceptance as a screening modality. Towards this direction, the paper has two primary contributions. Firstly, we present the COVID-19 Multi-Task Network which is an automated end-to-end network for COVID-19 screening. The proposed network not only predicts whether the CXR has COVID-19 features present or not, it also performs semantic segmentation of the regions of interest to make the model explainable. Secondly, with the help of medical professionals, we manually annotate the lung regions of 9000 frontal chest radiographs taken from ChestXray-14, CheXpert and a consolidated COVID-19 dataset. Further, 200 chest radiographs pertaining to COVID-19 patients are also annotated for semantic segmentation. This database will be released to the research community.