 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN-GDITD: Out-of-distribution detection via Deep Neural Network based Gaussian Descriptor for Imbalanced Tabular Data
Sep 04, 2024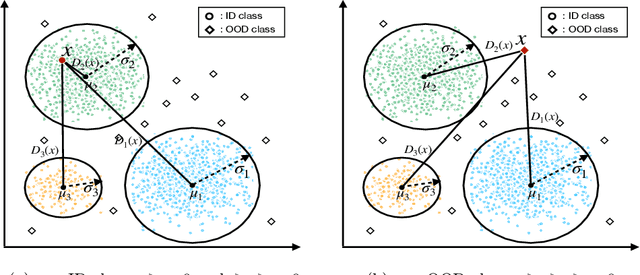
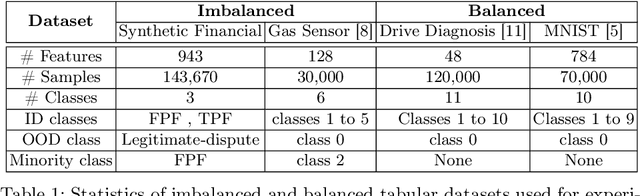

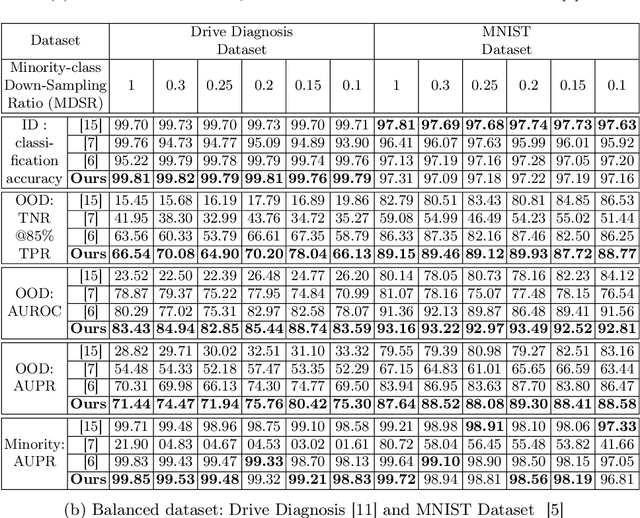
Classification tasks present challenges due to class imbalances and evolving data distributions. Addressing these issues requires a robust method to handle imbalances while effectively detecting out-of-distribution (OOD) samples not encountered during training. This study introduces a novel OOD detection algorithm designed for tabular datasets, titled Deep Neural Network-based Gaussian Descriptor for Imbalanced Tabular Data (DNN-GDITD). The DNN-GDITD algorithm can be placed on top of any DNN to facilitate better classification of imbalanced data and OOD detection using spherical decision boundaries. Using a combination of Push, Score-based, and focal losses, DNN-GDITD assigns confidence scores to test data points, categorizing them as known classes or as an OOD sample. Extensive experimentation on tabular datasets demonstrates the effectiveness of DNN-GDITD compared to three OOD algorithms. Evaluation encompasses imbalanced and balanced scenarios on diverse tabular datasets, including a synthetic financial dispute dataset and publicly available tabular datasets like Gas Sensor, Drive Diagnosis, and MNIST, showcasing DNN-GDITD's versatility.
Modeling Inter-Dependence Between Time and Mark in Multivariate Temporal Point Processes
Oct 27, 2022Temporal Point Processes (TPP) are probabilistic generative frameworks. They model discrete event sequences localized in continuous time. Generally, real-life events reveal descriptive information, known as marks. Marked TPPs model time and marks of the event together for practical relevance. Conditioned on past events, marked TPPs aim to learn the joint distribution of the time and the mark of the next event. For simplicity, conditionally independent TPP models assume time and marks are independent given event history. They factorize the conditional joint distribution of time and mark into the product of individual conditional distributions. This structural limitation in the design of TPP models hurt the predictive performance on entangled time and mark interactions. In this work, we model the conditional inter-dependence of time and mark to overcome the limitations of conditionally independent models. We construct a multivariate TPP conditioning the time distribution on the current event mark in addition to past events. Besides the conventional intensity-based models for conditional joint distribution, we also draw on flexible intensity-free TPP models from the literature. The proposed TPP models outperform conditionally independent and dependent models in standard prediction tasks. Our experimentation on various datasets with multiple evaluation metrics highlights the merit of the proposed approach.
Entity Alignment For Knowledge Graphs: Progress, Challenges, and Empirical Studies
May 18, 2022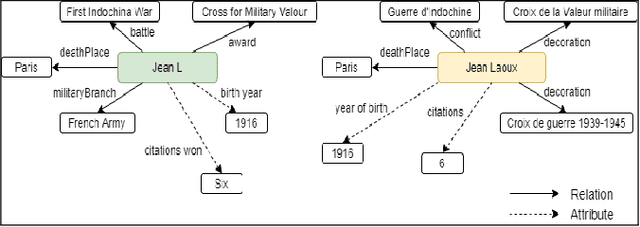
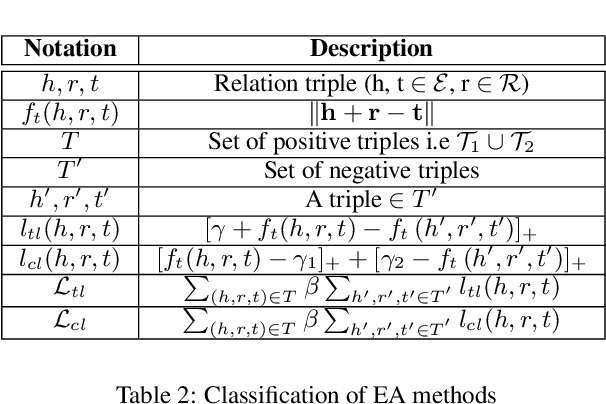
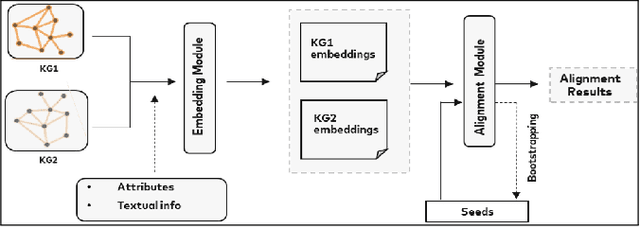
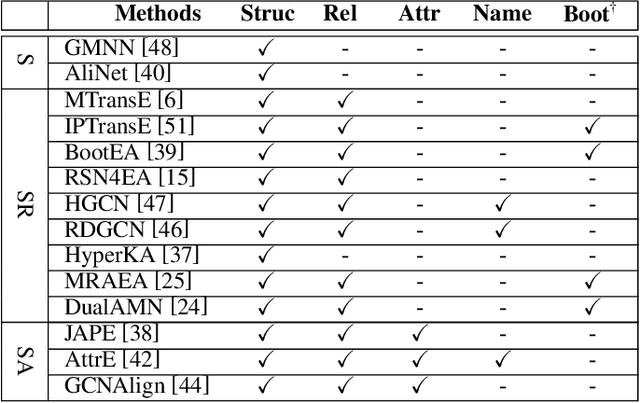
Entity Alignment (EA) identifies entities across databases that refer to the same entity. Knowledge graph-based embedding methods have recently dominated EA techniques. Such methods map entities to a low-dimension space and align them based on their similarities. With the corpus of EA methodologies growing rapidly, this paper presents a comprehensive analysis of various existing EA methods, elaborating their applications and limitations. Further, we distinguish the methods based on their underlying algorithms and the information they incorporate to learn entity representations. Based on challenges in industrial datasets, we bring forward $4$ research questions (RQs). These RQs empirically analyse the algorithms from the perspective of \textit{Hubness, Degree distribution, Non-isomorphic neighbourhood,} and \textit{Name bias}. For Hubness, where one entity turns up as the nearest neighbour of many other entities, we define an $h$-score to quantify its effect on the performance of various algorithms. Additionally, we try to level the playing field for algorithms that rely primarily on name-bias existing in the benchmarking open-source datasets by creating a low name bias dataset. We further create an open-source repository for $14$ embedding-based EA methods and present the analysis for invoking further research motivations in the field of EA.
Multi-Task Driven Explainable Diagnosis of COVID-19 using Chest X-ray Images
Aug 03, 2020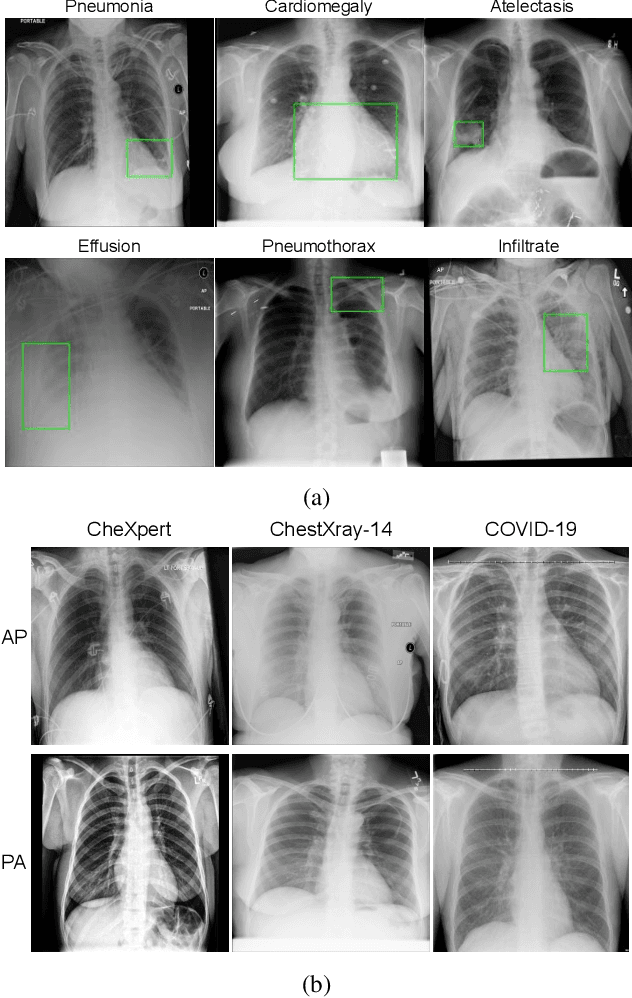
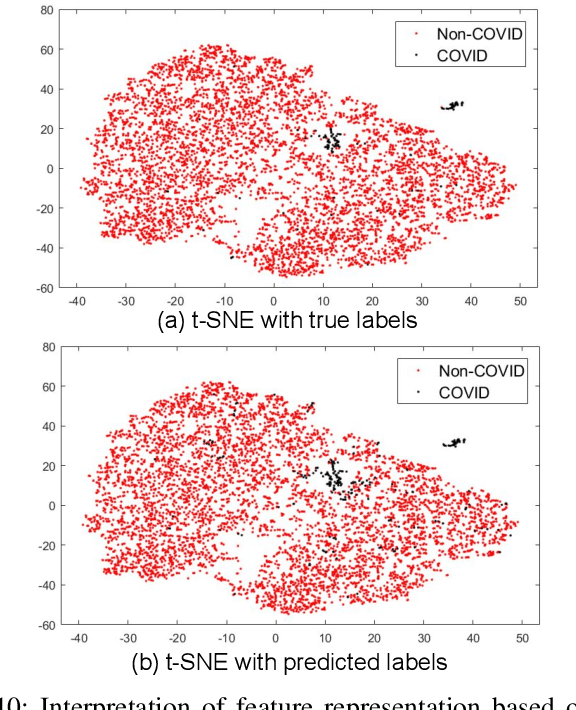
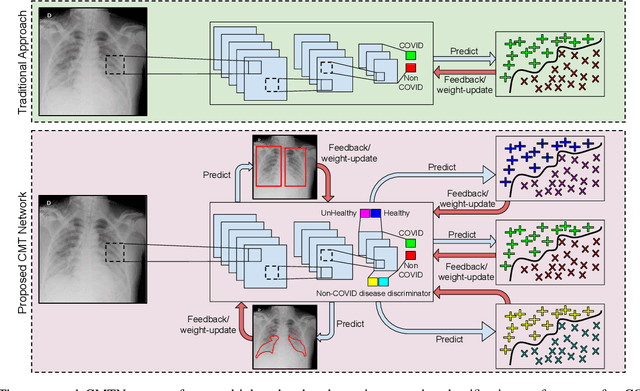
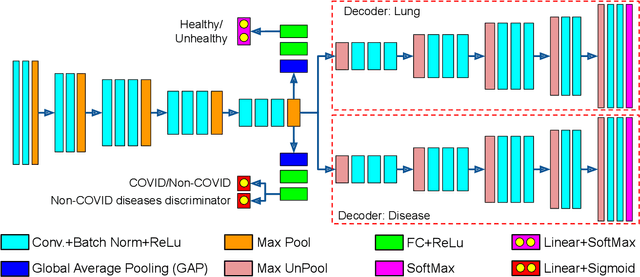
With increasing number of COVID-19 cases globally, all the countries are ramping up the testing numbers. While the RT-PCR kits are available in sufficient quantity in several countries, others are facing challenges with limited availability of testing kits and processing centers in remote areas. This has motivated researchers to find alternate methods of testing which are reliable, easily accessible and faster. Chest X-Ray is one of the modalities that is gaining acceptance as a screening modality. Towards this direction, the paper has two primary contributions. Firstly, we present the COVID-19 Multi-Task Network which is an automated end-to-end network for COVID-19 screening. The proposed network not only predicts whether the CXR has COVID-19 features present or not, it also performs semantic segmentation of the regions of interest to make the model explainable. Secondly, with the help of medical professionals, we manually annotate the lung regions of 9000 frontal chest radiographs taken from ChestXray-14, CheXpert and a consolidated COVID-19 dataset. Further, 200 chest radiographs pertaining to COVID-19 patients are also annotated for semantic segmentation. This database will be released to the research community.